
Speed Exam Guide (2.0)
Faster speed, not only save your time, but also long your harddisk life, any similar softwares will read harddisk continuely in finding process. faster speed = less reading, and you can get the same result!
If you need a duplicate file finder, your primary concern must be its search speed. Here, we will show you some effects of the testing environment, help you get the right judgment.
First, this kind of software will traverse all the files in your selected directories。Normally, the information of the directories and files is read from the hard disk at the first traversal, and it will be cached in memory, so the subsequent traversal will read it from memory directly. Therefore, it may be unfair to the software tested first. To avoid that, you can (1) reboot the system after every testing, or (2) traverse the directories you want to search before testing, for example, in the windows explorer, right-click on the directory and choose properties from the pop-up menu, and then the explorer will traverse the selected directory.
Second, when the amount of search files increases, the amount of search time doesn't increase linearly. For example, a simple but "stupid" algorithm, find the duplicate file by comparing it to all others, and then 100 files need just 10,000 comparisons, but 1000,000 files will need 1000,000,000,000 comparisons! What a googol! Maybe it will never get finished :-). So the optimization of the search algorithm is the major problem of this kind of software. Therefore, if you want to get the real capability of this kind of software, you shall let the test simples huge enough, and maybe you will realize the huge difference of search speed among them.
Third, you'd better temporarily disable the virus real time monitor before you begin to find duplicate files, because the monitor will catch the operation of the file reading and check the virus, which will slow down the search speed greatly.
I give a example below, help you determine the suitable simple.
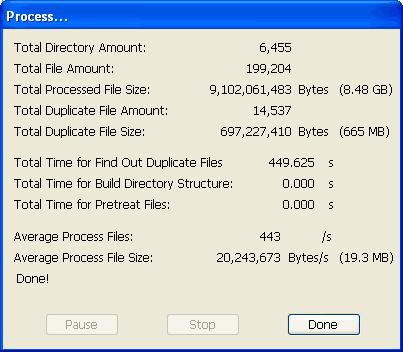
System: CPU: AMD Sempron 2500+, Hard disk: Seagate 7200RPM 250GB
Simple: offline image websites, 6,455 directories, 199,204 files, total 8.48GB size, include 14,537 duplicate files, total 665MB size.
Memory Usage: I use IceSword1.12 to get the CloneSensor memory usage. It show CloneSensor consume 6MB memory after startup, and when the search finished, CloneSensor struck 54MB peak memory usage. It's mean that you can search upto 500,000 files without using virtual memory if you have 120MB free physical memory, (Any software will slown down greatly when it use virtual memory)
Result: Just 7.5 minutes, the search result came out, 443 files/second, process 443 files every second?! So crazy! Is it magical? Test it yourself! :) The search algorithm of CloneSensor had gone through evolution five times. With the special optimized algorithm, CloneSensor can keep the high speed in finding files, in spite of the amount of files grows more and more, and really gets all results of the true byte-by-byte comparison. You can validate the results with any similar softwares which claim true byte-by-byte comparison.
Comparing with 1.1, in 2.0, the finding speed is 26.6% faster but the memory usage reduce 15%.
Click here for the detail of speed exam guide of 1.1
I haven't enough time to test the speed of all similar softwares, If you find any similar software faster than CloneSensor, please write to me. I have 2 more idea to boost the finding speed, but more complicate to realize, your information will inspirit me to challenge the difficulty! :)