
|
| Previous Top Next |
|
What is XML
|
| · | It is not a programming language.
|
| · | It is not the next generation of HTML.
|
| · | It is not a database.
|
| · | It is not specific to any horizontal or vertical market.
|
| · | It is not the solution to all your problems, but it can be a very powerful tool in building such a solution.
|
| <product>
|
| <name>Apple</name>
|
| <price>0.10</price>
|
| </product>
|
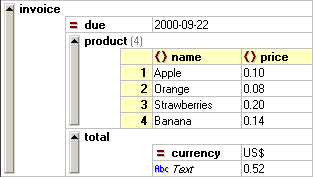
| <invoice due="2000-09-22">
|
| <product>
|
| <name>Apple</name>
|
| <price>0.10</price>
|
| </product>
|
| <product>
|
| <name>Orange</name>
|
| <price>0.08</price>
|
| </product>
|
| <product>
|
| <name>Strawberries</name>
|
| <price>0.20</price>
|
| </product>
|
| <product>
|
| <name>Banana</name>
|
| <price>0.14</price>
|
| </product>
|
| <total currency="US$">0.52</total>
|
| </invoice>
|
|
| · | drag & drop elements
|
| · | insert new rows
|
| · | copy/paste your data to and from other applications (e.g. Excel, etc.) and
|
| · | manipulate data in a graphical way that is not possible in views offered by other products
|
|