| LinuxovΘ noviny | 07-08/2001 | ||
|
| |||
Definice RAIDuNa rozdφl od jin²ch hardwarov²ch problΘm∙ jsou v²padky disk∙ obvykle spojeny s Φasov∞ nßroΦnou obnovou dat ze zßloh. T∞mto problΘm∙m se ale m∙╛eme vyhnout pou╛itφm redundantnφch diskov²ch polφ RAID, kterß jsou v∙Φi v²padk∙m jednotliv²ch disk∙ odoln∞j╣φ. OznaΦenφ RAID pochßzφ z anglickΘho "Redundant Array of Inexpensive Disks" nebo takΘ "Redundant Array of Independent Disks". Jednß se tedy o n∞kolik disk∙ slouΦen²ch do jednoho logickΘho svazku, kter² zpravidla zaji╣╗uje urΦitou redundanci dat, dφky kterΘ je pak odoln² v∙Φi hardwarov²m v²padk∙m n∞kterΘho z disk∙. I kdy╛ je v nßzvu obsa╛eno slovφΦko "redundant", ne v╣echny typy RAIDu jsou skuteΦn∞ redundantnφ. Zatφmco n∞kterΘ typy RAIDu jsou navr╛eny s ohledem na maximßlnφ bezpeΦnost dat, jinΘ jsou naopak optimalizovßny na rychlost.
HardwarovΘ a softwarovΘ implementace RAIDuRAID lze provozovat v podstat∞ dvojφm zp∙sobem. Bu∩ je realizovßn v hardwaru, co╛ obnß╣φ specißlnφ °adiΦ osazen² procesorem a zpravidla vybaven² vlastnφ pam∞tφ, kterß slou╛φ jako cache. Ve╣kerΘ funkce RAIDu plnφ °adiΦ a z pohledu operaΦnφmu systΘmu se chovß jako jedin² disk. Tato °e╣enφ b²vajφ pom∞rn∞ drahß (Mylex, DPT - nynφ Adaptec, ICP Vortex, velcφ v²robci PC jako HP, IBM, Compaq apod. majφ svΘ vlastnφ implementace). P°ednostφ hardwarov²ch °e╣enφ b²vß maximßlnφ spolehlivost a ve srovnßnφ se softwarovou variantou RAIDu dovedou odlehΦit zßt∞╛i systΘmu. RAID ov╣em takΘ m∙╛e b²t realizovßn pat°iΦn²m ovladaΦem na ·rovni operaΦnφho systΘmu a spousta operaΦnφch systΘm∙ to takΘ dnes umo╛≥uje. Toto °e╣enφ m∙╛e b²t za jist²ch okolnostφ flexibiln∞j╣φ a rychlej╣φ, ale takΘ nßroΦn∞j╣φ na systΘmovΘ prost°edky - zejmΘna na Φas procesoru. V poslednφch letech se setkßvßme i s nap∙l hardwarov²mi/softwarov²mi implementacemi RAIDu, kdy hardware obsahuje jen minimßlnφ podporu a v∞t╣inu prßce d∞lß ovladaΦ - tato varianta je levnß, ale °ada produkt∙ tΘto kategorie je nevalnΘ kvality a v²konu. Tento Φlßnek je zam∞°en² na softwarov² RAID pod Linuxem.
Teorie fungovßnφ RAIDuNe╛ se zam∞°φme na detaily softwarovΘho RAIDu pod Linuxem, podφvßme se na princip fungovßnφ jednotliv²ch typ∙ RAIDu a jejich vlastnosti.
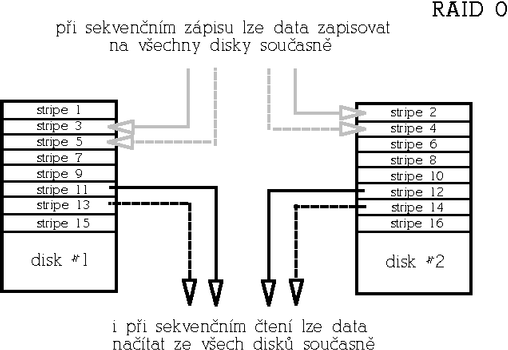
RAID 0 (Nonredundant striped array)Tento typ je urΦen pro aplikace, kterΘ vy╛adujφ maximßlnφ rychlost a nenφ redundantnφ. Naopak je pot°eba vzφt v ·vahu, ╛e pravd∞podobnost v²padku takovΘho pole roste s poΦtem disk∙. Ideßlnφ pou╛itφ p°edstavujφ audio/video streamingovΘ aplikace, eventußln∞ databßze a obecn∞ aplikace, p°i kter²ch Φteme sekvenΦn∞ velkß mno╛stvφ dat. Zßkladnφ jednotkou pole je tzv. stripe (z angl. "stripe", Φesky pruh), co╛ je blok dat urΦitΘ velikosti (b∞╛n∞ 4-64kB v zßvislosti na aplikaci). Po sob∞ jdoucφ data jsou pak v poli rozlo╛ena st°φdav∞ mezi disky do "strip∙" takov²m zp∙sobem, aby se p°i sekvenΦnφm Φtenφ/zßpisu p°istupovalo ke v╣em disk∙m souΦasn∞. Tφm je zaji╣t∞na maximßlnφ rychlost jak p°i Φtenφ tak i zßpisu, ale souΦasn∞ je tφm dßna takΘ zranitelnost pole. P°i v²padku kterΘhokoliv disku se stßvajφ data v podstat∞ neΦitelnß (respektive nekompletnφ). RAID 0 b²vß oznaΦovßn rovn∞╛ jako striping. Proto╛e nenφ redundantnφ, mß nejv²hodn∞j╣φ pom∞r cena/kapacita. PoΦet disk∙ je libovoln². Je ov╣em t°eba pamatovat na to, ╛e s rostoucφm poΦtem disk∙ v poli roste i pravd∞podobnost v²padku pole (proto╛e v²padek libovolnΘho disku znamenß havßrii celΘho pole); RAID 0 je tedy velmi rychl², ale mΘn∞ bezpeΦn² ne╛ samostatn² disk.
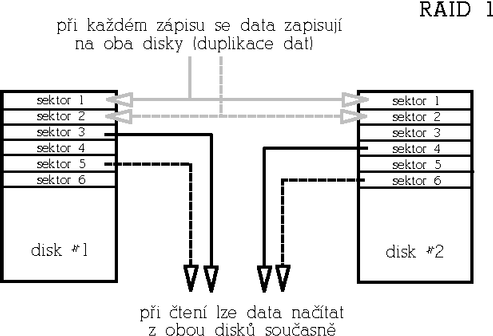
RAID 1 (Mirrored array)RAID 1 je naopak maximßln∞ redundantnφ. Rychlost Φtenφ m∙╛e b²t oproti samostatnΘmu disku v²razn∞ vy╣╣φ, rychlost zßpisu je stejnß jako u samostatnΘho disku. Funguje tak, ╛e data jsou p°i zßpisu "zrcadlena" na v╣echny disky v poli (tedy v p°φpad∞ RAIDu 1 tvo°enΘho dv∞ma disku jsou data duplikovßna apod.). P°i Φtenφ lze vyu╛φt vφcero kopiφ dat a podobn∞ jako u RAIDu 0 Φφst za v╣ech disk∙ souΦasn∞. Tento typ pole je urΦen pro aplikace s d∙razem na maximßlnφ redundanci. V²hodou tohoto redundantnφho °e╣enφ je stabilnφ v²kon i v p°φpad∞ v²padku disku, nev²hodou je pom∞r cena/kapacita. PoΦet disk∙ b²vß bu∩ 2 anebo libovoln², Φφm v∞t╣φ poΦet disk∙, tφm v∞t╣φ redundance a odolnost proti v²padku.
RAID 2 (Parallel array with ECC)Pole tohoto typu jsou dnes ji╛ historiφ, proto╛e dne╣nφ disky majφ vlastnφ opravnΘ mechanismy a uchovßvajφ ECC informace pro ka╛d² sektor samy. V polφch tohoto typu se stripovalo po jednotliv²ch sektorech a Φßst disk∙ pole byla vyhrazena pro uklßdßnφ ECC informacφ. JakΘkoliv Φtenφ i zßpis proto zpravidla zahrnovalo p°φstup ke v╣em disk∙m pole, co╛ bylo p°ekß╛kou vy╣╣φho v²konu zejmΘna u aplikacφch pracujφcφch se v∞t╣φmi kusy dat. Tento typ nenφ redundantnφ.
RAID 3 (Parallel array with parity)TakΘ tento typ polφ se ji╛ nepou╛φvß, jednß se o p°edch∙dce RAIDu 4. Stripovalo se po sektorech, ale jeden disk byl vyhrazen jako paritnφ, co╛ zaji╣╗ovalo redundanci (princip zaji╣t∞nφ redundance je stejn² jako u RAIDu 4 a 5, kter² je popsßn nφ╛e). Proto╛e i v tomto p°φpad∞ se stripovalo po sektorech, jakΘkoliv Φtenφ i zßpis zpravidla zahrnovalo p°φstup ke v╣em disk∙m pole.
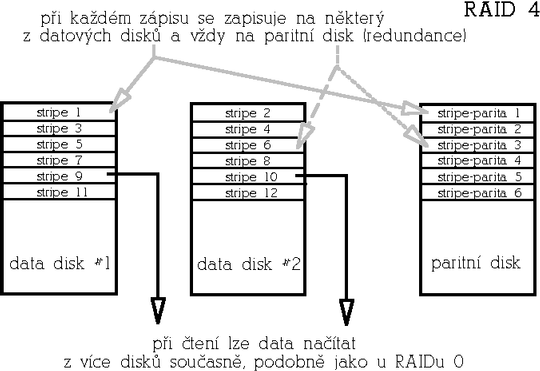
RAID 4 (Striped array with parity)Raid 4 je redundantnφ pole, kterΘ se dnes ji╛ pou╛φvß mßlo. FunkΦn∞ je podobnΘ RAIDu 5, kter² je ale v²konn∞j╣φ. Funguje tak, ╛e jeden disk je vyhrazen jako tzv. paritnφ disk. Na paritnφm disku je zaznamenßn kontrolnφ souΦet (operace XOR p°es data stejnΘ pozice jednotliv²ch disk∙). Pokud tedy dojde k v²padku n∞kterΘho z datov²ch disk∙, lze data rekonstruovat z dat zbyl²ch disk∙ a parity ulo╛enΘ na paritnφm disku. RAID 4 je odoln² v∙Φi v²padku libovolnΘho jednoho disku a mß tedy p°φzniv² pom∞r cena/kapacita. Paritnφ disk ale p°edstavuje ·zkΘ hrdlo tΘto architektury p°i zßpisech, proto╛e ka╛d² zßpis znamenß takΘ zßpis na paritnφ disk. Mimimßlnφ poΦet disk∙ je 3.
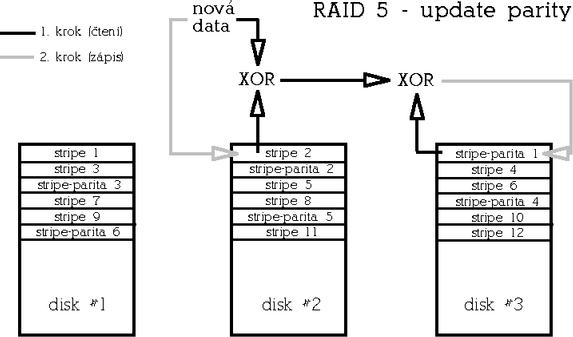
RAID 5 (Striped array with rotating parity)Tento typ poskytuje redundanci v∙Φi v²padku libovolnΘho jednoho disku s dobr²m pom∞rem cena/kapacita a v²konem. RAID 5 je vylep╣enß varianta RAIDu 4 v tom, ╛e parita nenφ ulo╛ena na jednom vyhrazenΘm disku, ale je rozmφst∞na rovnom∞rn∞ mezi v╣emi disky pole, Φφm╛ se odstranφ ·zkΘ hrdlo architektury RAIDu 4.
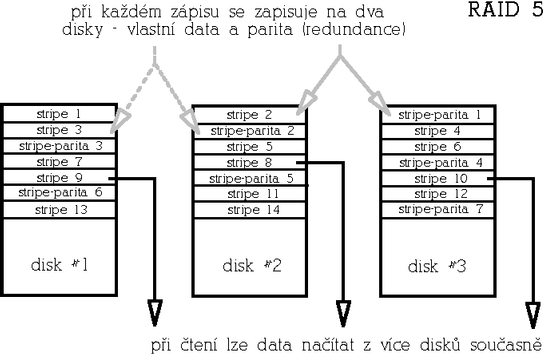 Paritu lze spoΦφtat bu∩ tak, ╛e skuteΦn∞ naΦteme a XORujeme data z odpovφdajφcφch datov²ch strip∙ v╣ech disk∙ (takto se parita poΦφtß p°i inicializaci pole, vy╛aduje to tedy p°φstup ke v╣em disk∙m). Ve druhΘm p°φpad∞ naΦteme p∙vodnφ data z datovΘho stripu, kterß se majφ zm∞nit, provedeme XOR s nov²mi daty a v²sledek je╣t∞ XORujeme s p∙vodnφ hodnotou parity (takto se parita poΦφtß na ji╛ inicializovanΘm b∞╛φcφm poli). Zßpis dat tedy p°edstavuje dvoje Φtenφ (dat a parity), v²poΦet parity a dvojφ zßpis (op∞t dat a parity). PoΦet p°φstup∙ na disk p°i zßpisu je v tomto p°φpad∞ konstantnφ bez ohledu na poΦet disk∙ v poli - p°istupuje se v╛dy ke dv∞ma disk∙m - a to takΘ mß za nßsledek ni╛╣φ v²kon tohoto typu pole ve srovnßnφ s redundantnφm RAIDem 1.
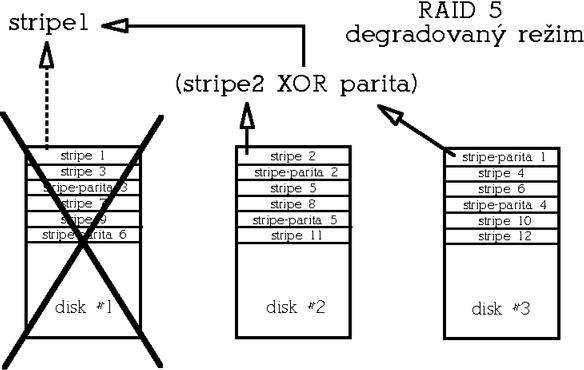
 V degradovanΘm re╛imu (degradovan² re╛im znamenß stav, kdy je n∞kter² z disk∙ z pole vy°azen kv∙li hardwarovΘ chyb∞) se pak musejφ data ulo╛enß na vadnΘm disku odvodit z dat zb²vajφcφch disk∙ a parity. Na rozdφl od redundantnφho RAIDu 1, kde v²padek disku obvykle neznamenß v²razn² pokles v²konu, vykazuje RAID 5 v degradovanΘm re╛imu v²razn∞ snφ╛en² v²kon zejmΘna p°i Φtenφ. Minimßlnφ poΦet disk∙ pro tento typ diskovΘho pole jsou 3.
Kombinace vφce typ∙ polφZ definic v²╣e popsan²ch typ∙ polφ vypl²vß, ╛e redundantnφ pole nejsou tak rychlß, jak bychom si mohli p°ßt a naopak u RAIDu 0 nßm chybφ redundance. Existuje ov╣em mo╛nost, jak v²hody jednotliv²ch typ∙ diskov²ch polφ spojit. Tato metoda spoΦφvß ve vytvo°enφ kombinovan²ch polφ, kdy disky v poli urΦitΘho typu jsou samy tvo°eny poli jinΘho typu. P°φkladem m∙╛e b²t nap°. RAID 1+0, kdy jsou pole typu RAID 1 dßle slouΦeny do RAIDu 0. TakovΘ pole je pak redundantnφ (toleruje v²padek a╛ dvou disk∙), rychlej╣φ zejmΘna v zßpisech ne╛ samotn² RAID 1, a mß lep╣φ pom∞r cena/kapacita ne╛ RAID 1 (velikost je zde n/2 * disk a minimßlnφ poΦet disk∙ je pak 4. Dal╣φ mo╛nostφ je t°eba RAID 0+1, RAID 5+0, RAID 5+1 apod.
Jak RAID o╣et°φ v²padek diskuV╣echny typy redundantnφch polφ obvykle umo╛≥ujφ nakonfigurovat krom∞ aktivnφch disk∙ je╣t∞ 1 Φi vφce rezervnφch disk∙. Aktivnφmi disky zde rozumφme disky, kterΘ jsou souΦßstφ funkΦnφho pole. V p°φpad∞ v²padku n∞kterΘho z aktivnφch disk∙ pak m∙╛e systΘm mφsto vadnΘho disku okam╛it∞ zaΦφt pou╛φvat disk rezervnφ. Po aktivaci rezervnφho disku do pole systΘm provede na pozadφ (tedy bez naru╣enφ dostupnosti pole) rekonstrukci pole a jakmile je rekonstrukce hotova, je pole op∞t pln∞ redundantnφ. Rekonstrukcφ je mφn∞na bu∩ synchronizace obsahu novΘho disku s ostatnφmi aktivnφmi disky (v prφpad∞ RAIDu 1), anebo rekonstrukce obsahu p∙vodnφho vadnΘho disku na zßklad∞ redundantnφ informace (jednß-li se o RAID 4 nebo 5). Po dobu, ne╛ rekonstrukce prob∞hne, se pole nachßzφ v tzv. degradovanΘm re╛imu, kdy v zßvislosti na konfiguraci nemusφ b²t redundantnφ a v p°φpad∞ RAIDu 5 se to projevφ snφ╛en²m v²konem (odtud nßzev "degradovan² re╛im"). Je samoz°ejm∞ mo╛nΘ pole provozovat bez rezervnφch disk∙ a disk vym∞nit pozd∞ji manußln∞. Detailn∞ se na v²m∞nu disk∙ a rekonstrukci polφ je╣t∞ podφvßme pozd∞ji.
Redundantnφ pole neznamenajφ konec zßlohRedundantnφ diskovß pole jsou odolnß pouze v∙Φi v²padk∙m urΦitΘho poΦtu disk∙. Neochrßnφ p°ed v²padkem napßjenφ, po╣kozenφm souborovΘho systΘmu p°i pßdu celΘho systΘmu nebo chybou administrßtora. Proto je pot°eba myslet i na dal╣φ metody ochrany dat - nap°. na zßlo╛nφ zdroje napßjenφ (UPS), ╛urnßlovacφ souborovΘ systΘmy apod. a v ka╛dΘm p°φpad∞ pravideln∞ zßlohovat.
Typy polφ podporovan²ch Linuxov²m ovladaΦem RAIDuA╛ doposud jsme se zab²vali pouze teoriφ fungovßnφ diskov²ch polφ, podφvejme se tedy jak to vypadß se softwarov²m RAIDem v Linuxu. Softwarovß implementace RAIDu pod OS Linux podporuje 5 typy diskov²ch polφ:
Historie, dostupnost, omezenφP∙vodnφ ovladaΦ "MetaDisku" (odtud nßzev ovladaΦe - md) napsal Marc Zyngier. Implementace zpoΦßtku del╣φ dobu podporovala pouze typy linear, RAID 0 a RAID 1. Pozd∞ji ovladaΦ vyvφjeli zejmΘna Ingo Molnßr, Gadi Oxman a nynφ Neil Brown. P°ibyla podpora dal╣φch typ∙ polφ a podpora bootovßnφ z RAIDu 0 a 1. V souΦasnΘ dob∞ se m∙╛eme setkat se dv∞ma verzemi ovladaΦe: verzφ 0.42, kterou obsahujφ Φistß jßdra °ady 2.2.x a verzφ 0.90, kterß se nachßzφ v jßdrech °ady 2.4.x. Jßdra 2.2.x v∞t╣iny distribucφ ale obsahujφ podporu RAIDu verze 0.90, ovladaΦ tΘto verze pro jßdra 2.2.x je k dispozici ve form∞ zßplaty jßdra. K provozovßnφ softwarovΘho RAIDu je zapot°ebφ krom∞ jadernΘho ovladaΦe takΘ sada utilit raidtools (d°φve mdtools), kterΘ musejφ odpovφdat verzi jadernΘho ovladaΦe (raidtools 0.42 a raidtools 0.90).OvladaΦe RAIDu jsou testovßny p°edev╣φm na platform∞ x86, ale lze je provozovat i na platformßch Sun Φi Alpha (a mo╛nß i dal╣φch, ov╣em na t∞chto exotiΦt∞j╣φch platformßch jsou mΘn∞ odlad∞ny). Pro jßdra °ady 2.2.x platφ urΦitß omezenφ, kterß vypl²vajφ z architektury tΘto °ady jader:
Pro jßdra °ady 2.4 tato omezenφ neplatφ.
KonfiguraceKonfigurace RAIDu verze 0.90 pou╛φvß konfiguraΦnφ soubor /etc/raidtab (na rozdφl od verze 0.42, kde byla konfigurace ulo╛ena v /etc/mdtab), ve kterΘm se pou╛φvajφ nßsledujφcφ direktivy:
Star╣φ verze softwarovΘho RAIDu (0.40 a╛ 0.51) pou╛φvaly konfiguraΦnφ soubor /etc/mdtab. P°esto╛e tato star╣φ verze ovladaΦe je souΦßstφ "Φist²ch jader" 2.2.x, je zastaralß a nebudeme se jφ zde v∙bec zab²vat. Pro ·plnost je star╣φ verze RAIDu dokumentovanß v p°φslu╣nΘm HOWTO.
P°φklady konfiguracφP°φklad konfigurace pole linear. M∞jme pole typu linear slo╛enΘ ze dvou oddφl∙:
raiddev /dev/md0 raid-level -1 persistent-superblock 1 nr-raid-disks 2 nr-spare-disks 0 device /dev/sda1 raid-disk 0 device /dev/sdb1 raid-disk 1 P°φklad konfigurace RAID 0. M∞jme diskovΘ pole RAID 0 slo╛enΘ ze dvou oddφl∙, sda1 a sdb1, velikost stripu je 16 kB:
raiddev /dev/md0 raid-level 0 persistent-superblock 1 chunk-size 16 nr-raid-disks 2 nr-spare-disks 0 device /dev/sda1 raid-disk 0 device /dev/sdb1 raid-disk 1 P°φklad konfigurace RAID 1. M∞jme diskovΘ pole RAID 1 slo╛enΘ ze dvou oddφl∙ a s jednφm rezervnφm oddφlem:
raiddev /dev/md1 raid-level 1 nr-raid-disks 2 nr-spare-disks 1 device /dev/sda1 raid-disk 0 device /dev/sdb1 raid-disk 1 device /dev/sdc1 spare-disk 0 P°φklad konfigurace pole RAID 5 s rozlo╛enφm parity "left-symmetric", velikostφ stripu 4 kB a jednφm rezervnφm oddφlem:
raiddev /dev/md2 raid-level 5 nr-raid-disks 3 chunk-size 4 parity-algorithm left-symmetric nr-spare-disks 1 device /dev/sda1 raid-disk 0 device /dev/sdb1 raid-disk 1 device /dev/sdc1 raid-disk 2 device /dev/sdc1 spare-disk 0
Obslu╛n² software - RaidtoolsBalφΦek raidtools (nahrazuje star╣φ balφΦek mdtools urΦen² pro star╣φ verze ovladaΦe RAIDu) obsahuje obslu╛nΘ utility nezbytnΘ k manipulaci s diskov²mi poli:
V budoucnu z°ejm∞ budou utility z balφΦku raidtools nahrazeny jedinou utilitou mdctl, kterou vyvφjφ Neil Brown. Prvnφ verze tΘto utility jsou ji╛ k dispozici. Utilita mdctl nemusφ pou╛φvat ╛ßdn² konfiguraΦnφ soubor, v╣e pot°ebnΘ lze zadat na p°φkazovΘ °ßdce, anebo to mdctl zjistφ anal²zou RAID superblok∙ ulo╛en²ch na discφch (podobn∞ funguje automatickΘ startovßnφ polφ jßdrem p°i bootu). Cφlem autora je tedy p°idat v²hody a robustnost, kterou poskytuje vlastnost raid autodetect jßdra a zßrov∞≥ se vyhnout potencißlnφm konflikt∙m mezi neaktußlnφ konfiguracφ v souboru raidtab a skuteΦnou konfiguracφ polφ, ke kter²m Φasem m∙╛e dojφt, pokud pou╛φvßme raidtools. Zatφm je utilita mdctl ve stavu v²voje, tak╛e jejφ ostrΘ pou╛itφ je╣t∞ nelze doporuΦit. Poznßmka na vysv∞tlenou: Soubor raidtab odrß╛φ konfiguraci polφ v dob∞ jejich sestavenφ, ov╣em pokud t°eba pozd∞ji vym∞nφme nebo p°esuneme n∞kterΘ disky, nemusφ ji╛ odrß╛et skuteΦnou konfiguraci. Pokud tedy z n∞jakΘho d∙vodu pot°ebujeme pole znovu inicializovat anebo ho jen startujeme pomocφ raidstart, nesmφme zapomenout soubor raidtab ruΦn∞ upravit, abychom se u╣et°ili v budoucnu nep°φjemnostφ.
Inicializace polφJakmile mßme odpovφdajφcφm zp∙sobem rozd∞lenΘ disky a p°ipraven² konfiguraΦnφ soubor /etc/raidtab, m∙╛eme pole inicializovat utilitou mkraid, kterß pole sestavφ a aktivuje. Pokud zaklßdßme pole s perzistentnφmi RAID superbloky (viz nφ╛e), pak mkraid vypφ╣e i pozici RAID superblok∙:
# mkraid /dev/md5 handling MD device /dev/md5 analyzing super-block disk 0: /dev/sda7, 20163568kB, raid superblock at 20163456kB disk 1: /dev/sdb7, 20163568kB, raid superblock at 20163456kB Po ·sp∞╣nΘ inicializaci bychom m∞li v souboru /proc/mdstat, kter² obsahuje informace a aktivnφch polφch vid∞t odpovφdajφcφ zßznam, nap°:
$ cat /proc/mdstat Personalities : [raid0] [raid1] [raid5] read_ahead 1024 sectors md0 : active raid1 sdb1[1] sda1[0] 131968 blocks [2/2] [UU] PotΘ nßm nic nebrßnφ pole zformßtovat nap°. pomocφ mke2fs, pokud chceme na poli provozovat souborov² systΘm ext2. Utilita mke2fs akceptuje volbu -R stride=X, kterß udßvß kolik blok∙ souborovΘho systΘmu obsahuje 1 "stripe" pole. Tφm pßdem je takΘ vhodnΘ zadat ruΦn∞ velikost bloku (parametr -b). Nap°. m∞jme pole typu RAID 0 s velikostφ stripu 16 kB. Pokud budeme chtφt pou╛φt velikost bloku souborovΘho systΘmu 4 kB, zadßme:
mke2fs /dev/md0 -b 4096 -R stride=4
Raid autodetect anebo raidstart?Nynφ tedy mßme funkΦnφ diskovΘ pole. Zb²vß vy°e╣it zp∙sob, jak²m se bude pole vypφnat p°i vypnutφ systΘmu a zapφnat p°i startu systΘmu. Jednou mo╛nostφ je pou╛itφ utilit raidstart a raidstop. Pomocφ t∞chto utilit m∙╛eme pole aktivovat Φi zastavit kdykoliv, staΦφ tedy upravit p°φslu╣nΘ startovacφ skripty. (Pokud u╛ distribuce toto neobsahuje; nap°. distribuce Red Hat nenφ pot°eba upravovat, ze skriptu /etc/rc.d/rc.sysinit je raidstart volßn automaticky, existuje-li soubor /etc/raidtab a raidstop je volßn ze skriptu /etc/rc.d/init.d/halt.).
Druhou, robustn∞j╣φ metodou je vyu╛itφ mo╛nosti automatickΘ aktivace polφ jßdrem p°i bootu. Aby mohla fungovat, je pot°eba v prvΘ °ad∞ pou╛φvat perzistentnφ RAID superbloky a v╣echny diskovΘ oddφly, kterΘ jsou souΦßstφ polφ, musejφ b²t v tabulce oddφl∙ oznaΦeny jako typ Linux raid autodetect (tedy hodnota 0xfd hexadecimßln∞). Viz v²pis fdisku - nastavenφ diskov²ch oddφl∙ pro autodetekci RAID polφ. V²hodou tohoto °e╣enφ navφc je, ╛e jakmile je diskovΘ pole inicializovßno, nepou╛φvß se ji╛ pro op∞tovn² start / zastavenφ pole konfiguraΦnφ soubor /etc/raidtab. O sestavenφ a spu╣t∞nφ pole se postarß ovladaΦ RAIDu, kter² na v╣ech diskov²ch oddφlech typu Linux raid autodetect vyhledß RAID superbloky a na zßklad∞ informacφ v RAID superblocφch pole spustφ. Stejn∞ tak ovladaΦ RAIDu v╣echny pole korektn∞ vypne v zßv∞reΦnΘ fßzi ukonΦenφ b∞hu systΘmu potΘ, co jsou odpojeny souborovΘ systΘmy. I v p°φpad∞ zm∞ny jmen disk∙ nebo po p°enesenφ disk∙ na ·pln∞ jin² systΘm tedy pole bude korektn∞ sestaveno a nastartovßno, viz nßsledujφcφ ·ryvek systΘmovΘho logu po zßmen∞ disk∙ sdc za sdb a sdb za sda:
autorun ... considering sdb6 ... adding sdb6 ... adding sda6 ... created md4 bind<sda6,1> bind<sdb6,2> running: <sdb6><sda6> now! sdb6's event counter: 00000001 sda6's event counter: 00000001 md: device name has changed from sdc6 to sdb6 since last import! md: device name has changed from sdb6 to sda6 since last import! md4: max total readahead window set to 128k raid1: device sdb6 operational as mirror 1 raid1: device sda6 operational as mirror 0 md: updating md4 RAID superblock on device sdb6 [events: 00000002](write) sdb6's sb offset: 15332224 sda6 [events: 00000002](write) sda6's sb offset: 15332224
RAID superblokKa╛d² diskov² oddφl, kter² je souΦßsti raid svazku (v²jimku tvo°φ pouze svazky bez perzistentnφch superblok∙, viz nφ╛e) obsahuje tzv. RAID superblok. Tento superblok je 4kB Φßst RAID oddφlu vyhrazenß pro informace o p°φslu╣nosti danΘho oddφlu k urΦitΘmu poli a o stavu pole. Nßsleduje podrobn² popis superbloku, kter² se nßm bude pozd∞ji hodit p°i °e╣enφ n∞kter²ch problΘmov²ch situcacφ popsan²ch nφ╛e. ╚tenß°, kter² se nechce RAIDem zab²vat do hloubky, m∙╛e tuto Φßst p°eskoΦit.
RAID superblok (o velikosti 4 kB) je ulo╛en na konci diskovΘho oddφlu. Jeho pozici zφskßme bu∩ ze systΘmovΘho logu (ovladaΦ RAIDu loguje updaty RAID superbloku):
md: updating md0 RAID superblock on device kernel: sdb1 [events: 000000e8](write) sdb1's sb offset: 8956096 nebo ji takΘ m∙╛eme odvodit z velikosti diskovΘho oddφlu (komentß° zdrojovΘho k≤du balφΦku raidutils):
If x is the real device size in bytes, we return an apparent size of: y = (x & (MD_RESERVED_BYTES - 1)) - MD_RESERVED_BYTES and place the 4kB superblock at offset y. #define MD_RESERVED_BYTES (64 * 1024) Nejjednodu╣╣φ je ale podφvat se do /proc/mdstat, kde je uvedena velikost ka╛dΘho svazku v blocφch, nap°. u pole typu RAID 1:
md0 : active raid1 sdb1[1] sda1[0] 131968 blocks [2/2] [UU]
RAID superblok z diskovΘho oddφlu sdb1 pak zφskßme a ulo╛φme do souboru /tmp/superblok p°φkazem:
dd if=/dev/sdb1 of=/tmp/superblok bs=1k skip=131968 count=4 Jestli╛e se jednß o pole RAID 0, slo╛enΘ ze dvou disk∙, pak velikost zφskanou z /proc/mdstat vyd∞lφme 2 nap°:
md4 : active raid0 sdd1[1] sdc1[0] 17942272 blocks 16k chunks pak superblok zkopφrujeme p°φkazem:
dd if=/dev/sdb1 of=/tmp/superblok bs=1k skip=8971136 count=4 ProhlΘdnout si jej m∙╛eme nap°. pomocφ utility od (s vhodn²mi parametry, nap°. od -Ax -tx4). Pro kontrolu, superblok v╛dy zaΦφnß "magick²m Φφslem" 0xa92b4efc. Superblok obsahuje zejmΘna nßsledujφcφ informace:
Perzistentnφ superbloky a RAID 0 / linearPokud provozujeme pole RAID 0 Φi linear, mßme mo╛nost zvolit variantu bez pou╛itφ perzistentnφho superbloku. Volba "persistent-superblock 0", znamenß, ╛e se RAID superblok nebude uklßdat na disk. Tato mo╛nost existuje z d∙vod∙ zachovßnφ kompatibility s polemi z°φzen²mi pomocφ star╣φ verzφ ovladaΦe RAIDu. Po vypnutφ takovΘho pole nez∙stane na svazku informace o konfiguraci a stavu pole. Proto je tato pole nutnΘ v╛dy znovu inicializovat p°i ka╛dΘm startu bu∩ utilitou mkraid, nebo pomocφ utility raid0run (co╛ je pouze symbolick² odkaz na mkraid) a nelze vyu╛φt automatickΘho startovßnφ polφ jßdrem p°i bootu.Poznßmka: Na tuto volbu je t°eba dßvat pozor p°i konfiguraci - pokud p°i konfiguraci pole RAID 0 direktivu persistent-superblock vynechßme, pou╛ije se standardnφ hodnota 0, tedy pole bez perzistentnφch superblok∙!
Monitorovßnφ stavu poleAktußlnφ stav diskov²ch polφ zjistφme vypsßnφm souboru /proc/mdstat. Prvnφ °ßdek obsahuje typy polφ, kterΘ ovladaΦ podporuje (zßle╛φ na konfiguraci jßdra). U jednotliv²ch RAID svazk∙ je pak uvedeno kterΘ diskovΘ oddφly svazek obsahuje, velikost svazku, u redundantnφch polφ pak celkov² poΦet konfigurovan²ch oddφl∙ a z toho poΦet funkΦnφch, nßsledovan² schΘmatem funkΦnosti v hranat²ch zßvorkßch. Nßsledujφcφ p°φklad uvßdφ stav funkΦnφho pole RAID 1:
md0 : active raid1 hdc1[1] hda1[0] 136448 blocks [2/2] [UU] Druh² p°φklad uvßdφ stav pole RAID 1 po v²padku jednoho disku, oddφl sdc1 je oznaΦen jako nefunkΦnφ (F=Failed mφsto Φφsla aktivnφho oddφlu):
md0 : active raid1 sdc1[F] sdd1[0] 8956096 blocks [2/1] [U_] T°etφ p°φklad ukazuje stav pole RAID 1, kdy probφhß rekonstrukce:
md1 : active raid1 hdc2[1] hda2[0] 530048 blocks [2/2] [UU] \ resync=4% finish=6.7min SouΦßstφ raidtools bohu╛el nenφ utilita k monitorovßnφ stavu diskov²ch polφ, tak╛e si administrßtor musφ vypomoci skriptem, kter² je pravideln∞ spou╣t∞n z cronu a kontroluje /proc/mdstat (jednodu╣e nap°. tak, ╛e si skript na disk ulo╛φ obsah /proc/mdstat nebo jeho MD5 souΦet a nßsledn∞ kontroluje, jestli se /proc/mdstat zm∞nil; v p°φpad∞ zm∞ny pak prost°ednictvφm e-mailu uv∞domφ administrßtora) anebo filtrem systΘmovΘho logu.
Rekonstrukce poleRedundantnφ typy polφ je t°eba po inicializaci, po v²m∞n∞ disku, nebo po nahrazenφ vadnΘho disku rezervnφm (viz direktiva spare-disk v /etc/raidtab) rekonstruovat Φi synchronizovat. Ve v╣ech p°φpadech systΘm rekonstrukci spou╣tφ automaticky. Pr∙b∞h rekonstrukce je mo╛nΘ sledovat v /proc/mdstat (viz p°φklad o n∞kolik °ßdek v²╣e). Rekonstrukce probφhß s nφzkou prioritou, nezabere tedy Φas procesoru na ·kor jin²ch aplikacφ, ale bude se sna╛it vyu╛φt maximßlnφ prostupnosti I/O za°φzenφ. Proto m∙╛eme po dobu rekonstrukce pozorovat zpomalenφ diskov²ch operacφ. Maximßlnφ rychlost rekonstrukce ov╣em takΘ lze ovlivnit nastavenφm limitu v /proc/sys/dev/md/speed-limit, v²chozφ hodnota je 100 kB/sec. OvladaΦ RAIDu umφ souΦasn∞ spustit rekonstrukci na n∞kolika polφch souΦasn∞. Pokud jsou v╣ak oddφly jednoho disku souΦßstφ vφce polφ, kterΘ by se m∞ly synchronizovat souΦasn∞, provede se synchronizace polφ postupn∞ (z d∙vodu v²konu). V systΘmovΘm logu se pak objevφ ne╣kodnΘ hlß╣enφ typu "XX has overlapping physical units with YY":
md: syncing RAID array md1 md: minimum _guaranteed_ reconstruction speed: 100 KB/sec. md: using maximum available idle IO bandwith for reconstruction. md: using 128k window. md: serializing resync, md2 has overlapping physical units with md1! md: md1: sync done. md: syncing RAID array md2 md: minimum _guaranteed_ reconstruction speed: 100 KB/sec. md: using maximum available idle IO bandwith for reconstruction. md: using 128k window. md: md2: sync done. V /proc/mdstat jsou ty svazky, na kter²ch je rekonstrukce pozastavena, oznaΦeny jako pln∞ funkΦnφ, ale je u nich poznßmka resync=DELAYED:
Personalities : [linear] [raid0] [raid1] [raid5] read_ahead 1024 sectors md2 : active raid1 hdc3[1] hda3[0] 530048\ blocks [2/2] [UU] resync=DELAYED md1 : active raid1 hdc2[1] hda2[0] 530048\ blocks [2/2] [UU] resync=4% finish=6.7min md0 : active raid1 hdc1[1] hda1[0] 136448\ blocks [2/2] [UU] Pokud zformßtujeme a p°ipojφme Φerstv∞ z°φzenΘ redundantnφ pole, na kterΘm probφhß rekonstrukce, mohou se v systΘmovΘm logu objevit nßsledujφcφ ne╣kodnΘ hlß╣enφ (je to zp∙sobenΘ tφm, ╛e mke2fs, fsck a ovladaΦ FS pou╛φvajφ p°i p°φstupu jinou velikost bloku, ne╛ je v²chozφ velikost se kterou pracuje ovladaΦ raidu):
kernel: set_blocksize: b_count 1, dev md(9,3),\ block 96765, from c014 kernel: set_blocksize: b_count 1, dev md(9,3),\ block 96766, from c014 kernel: set_blocksize: b_count 2, dev md(9,3),\ block 96767, from c014 kernel: md3: blocksize changed during write kernel: nr_blocks changed to 32 (blocksize 4096,\ j 24160, max_blocks 385536)
Redundantnφ pole: v²m∞na disku, hot plugPokud p°i Φtenφ nebo zßpisu na n∞kter² z diskov²ch oddφl∙, kter² je souΦßstφ redundantnφho diskovΘho pole, dojde k chyb∞, je dotyΦn² oddφl oznaΦen jako vadn² a pole jej p°estane pou╛φvat. Pokud mßme v danΘm diskovΘm poli za°azen jeden nebo vφce rezervnφch disk∙ (direktiva spare-disk), je tento v p°φpad∞ v²padku automaticky aktivovßn, systΘm provede rekonstrukci pole a pr∙b∞h rekonstrukce zaznamenß do systΘmovΘho logu. V opaΦnΘm p°φpad∞ pole z∙stane v provozu v degradovanΘm re╛imu, pak to v systΘmovΘm logu bude vypadat zhruba takto:
kernel: SCSI disk error : host 0 channel 0\ id 4 lun 0 return code = 28000002 kernel: [valid=0] Info fld=0x0, Current sd08:11:\ sense key Hardware Error kernel: Additional sense indicates\ Internal target failure kernel: scsidisk I/O error:\ dev 08:11, sector 2625928 kernel: raid1: Disk failure on sdb1,\ disabling device. kernel: Operation continuing on 1 devices kernel: md: recovery thread got woken up ... kernel: md0: no spare disk to reconstruct\ array! - continuing in degraded mode kernel: md: recovery thread finished ... P°φjemnou vlastnostφ diskov²ch polφ je takΘ mo╛nost v²m∞ny disku za chodu systΘmu. Samoz°ejm∞ k tomu pot°ebujeme v prvΘ °ad∞ hardware, kter² to umo╛≥uje. OvladaΦe slu╣n²ch SCSI °adiΦ∙ umo╛≥ujφ p°idßvßnφ Φi ubφrßnφ za°φzenφ, to ale samo o sob∞ nestaΦφ. Je zapot°ebφ pou╛φvat SCA disky urΦenΘ pro "hot swap" a odpovφdajφcφ SCSI subsystΘm s SCA konektory a elektronikou, kterß zajistφ stabilitu SCSI sb∞rnice p°i odebφrßnφ Φi p°idßvßnφ za°φzenφ. M∞jme pole typu RAID 1, ve kterΘm do╣lo k chyb∞ na oddφlu sdc1. Disk sdc1 je p°ipojen ke kanßlu 0 SCSI °adiΦe 0 a mß ID rovno 4:
md0 : active raid1 sdc1[F] sdd1[0] 8956096 blocks [2/1] [U_] Jak tedy probφhß v²m∞na vadnΘho disku, mßme-li k tomu pot°ebnΘ hardwarovΘ vybavenφ:
Pokud nemßme hardware pot°ebn² k "hot-swap" v²m∞n∞ disk∙, musφme se smφ°it s vypnutφm systΘmu, v²m∞nou vadnΘho disku a op∞tovn²m zapnutφm systΘmu. Potom staΦφ pouze vytvo°it pomocφ fdisku odpovφdajφcφ diskovΘ oddφly a p°φkazem raidhotadd je za°adit do diskovΘho pole. P°φkazy pro p°idßvanφ a ubφrßnφ SCSI za°φzenφ jsou popsßny ve zdrojovΘm k≤du jßdra (soubor linux/drivers/scsi/scsi.c).
IDE nebo SCSI?Doposud jsme se zb²vali obecn∞ fungovßnφm softwarovΘho RAIDu, ov╣em ve chvφli kdy se rozhodneme sestavit systΘm s RAIDem, musφme se zamyslet nad v²hodami a nev²hodami t∞chto rozhranφ, kterΘ s provozovßnφm diskov²ch polφ souvisejφ. Proto╛e tato problematika je sama o sob∞ rozsßhlß, uvedeme na tomto mφst∞ pouze n∞kolik zßsadnφch rozdφl∙:Rozhranφ SCSI mß n∞kolik rys∙, kterΘ napomßhajφ vy╣╣φmu v²konu diskovΘho subsystΘmu:
Rozhranφ IDE mß naopak n∞kolik nedostatk∙, kterΘ komplikujφ jeho nasazenφ, zejmΘna:
Je tedy jasnΘ, ╛e aΦkoliv maximßlnφ teoretickΘ propustnosti obou rozhranφ jsou dnes pom∞rn∞ vysokΘ, v prost°edφ, kde je kladen d∙raz na reßlnou vysokou propustnost nejen p°i sekvenΦnφm Φtenφ nebo zßpisu, je rozhranφ SCSI stßle volbou Φφslo jedna. Pokud se rozhodneme budovat systΘm na bßzi IDE, rozhodn∞ se vyplatφ obsazovat ka╛d² kanßl IDE pouze jednφm za°φzenφm. (A to jak z d∙vodu v²konu, tak stability, proto╛e pokud bychom nap°. sestavili pole RAID 5 z IDE disk∙ a disky by byly na kanßlech po dvou, riskujeme v p°φpad∞ v²padku n∞kterΘho z "master" disk∙ havßrii celΘho pole, proto╛e tφm mohou v krajnφm p°φpad∞ vypadnout disky oba - jak "master" tak i "slave"".)
TestovßnφKdy╛ zprovoznφme redundantnφ diskovΘ pole, bude nßs zajφmat i zp∙sob, jak²m otestovat jeho odolnost proti v²padku disku. M∙╛eme k tomu pou╛φt utilitu raidsetfaulty, kterß simuluje v²padek disku a oznaΦφ jej jako vadn² (je pot°eba mφt dostateΦn∞ novou verzi balφΦku raidtools, ve star╣φch verzφch tatu utilita chybφ). Potom m∙╛eme disk vy°adit z pole p°φkazem raidhotremove, op∞t p°idat p°φkazem raidhotadd a sledovat pr∙b∞h rekonstrukce pole. Metodu testovßnφ tφm, ╛e za chodu vytßhneme konektor disku, rozhodn∞ nelze doporuΦit, proto╛e tφmto zp∙sobem m∙╛eme hardware vß╛n∞ po╣kodit.
TipyNynφ u╛ mßme za sebou jak teorii fungovßnφ RAIDu, tak z velkΘ Φßsti i praxi softwarovΘho RAIDu pod Linuxem. V tΘto poslednφ Φßsti se zam∞°φme na mΘn∞ obvyklΘ postupy a tipy, jak °e╣it n∞kterΘ problΘmovΘ situace.
Jak zalo╛it redundantnφ pole v degradovanΘm re╛imuSoftwarov² RAID je pom∞rn∞ flexibilnφ. Pokud jsme nap°φklad v situaci, kdy pot°ebujeme p°evΘst systΘm b∞╛φcφ na samostatnΘm disku na redundantnφ pole RAID 1, nemusφme kv∙li tomu reinstalovat systΘm. M∙╛eme vyu╛φt toho, ╛e lze vytvo°it pole v degradovanΘm re╛imu. Dejme tomu, ╛e mßme instalovan² systΘm na diskovΘm oddφlu sda1 a pro zjednodu╣enφ je to jedin² oddφl na disku sda. Do poΦφtaΦe jsme p°idali disk stejn∞ velk² disk sdb a mßme p°ipraveno jßdro podporujφcφ sofwarov² RAID. Pomocφ fdisku vytvo°φme diskov² oddφl sdb1 obdobn∞ jako je na disku sda. Nynφ vytvo°φme konfiguraΦnφ soubor /etc/raidtab:
raiddev /dev/md0 raid-level 1 persistent-superblock 1 nr-raid-disks 2 nr-spare-disks 0 device /dev/sdb1 raid-disk 0 device /dev/sda1 failed-disk 1 Pomocφ mkraid inicializujeme pole, vytvo°φme na n∞m souborov² systΘm (nap°. pomocφ mke2fs), p°φpojφme a zkopφrujeme na n∞j data z sda1. Odpovφdajφcφm zp∙sobem upravφme konfiguraΦnφ soubory na svazku md0 (/etc/fstab apod.). Po tΘ systΘm nabootujeme ze svazku md0 (t°eba pomocφ diskety anebo upravφme konfiguraci pro LILO), zkontrolujeme, ╛e je v╣e v po°ßdku a p°φkazem raidhotadd p°idßme oddφl sda1 do pole.
Jak p°idat t°etφ aktivnφ disk do pole RAID 1Pokud mßme pole RAID 1 tvo°enΘ dv∞ma disky a rozhodneme se pro zv²╣enφ redundance p°idat je╣t∞ t°etφ, nestaΦφ na to pouze p°φkaz raidhotadd. Ten toti╛ disk do pole p°idß, ale pouze jako disk rezervnφ ("spare"). Pokud chceme, aby byl t°etφ disk takΘ aktivnφ, musφme si op∞t pomoci direktivou failed-disk v konfiguraΦnφm souboru /etc/raidtab. T°etφ disk oznaΦφme jako failed-disk a nezapomeneme zv²╣it celkov² poΦet aktivnφch disk∙ na 3 (nr-raid-disk):
raiddev /dev/md0 raid-level 1 persistent-superblock 1 nr-raid-disks 3 nr-spare-disks 0 device /dev/sda1 raid-disk 0 device /dev/sdb1 raidd-disk device /dev/sdc1 failed-disk PotΘ pomocφ mkraid pole znovu inicializujeme a p°φkazem raidhotadd p°idßme oddφl sdc1. (Tφm, ╛e oznaΦφme nov² disk jako failed-disk zajistφme, ╛e jej mkraid p°i inicializaci p°eskoΦφ, ale pole bude poΦφtat se 3 disky, nßslednΘ spu╣t∞nφ raidhotadd pak zajistφ aktivaci.)
Kdy╛ z RAIDu 5 vypadne vφce disk∙RAID 5 je odoln² v∙Φi v²padku jednoho disku. Proto╛e se stripuje, nejsou data z jednotliv²ch disk∙ samostatn∞ pou╛itelnß a tato situace je tΘm∞° ne°e╣itelnß. Co tedy d∞lat v p°φpad∞, kdy╛ k v²padku vφce ne╛ jednoho disku dojde? Pokud disky z∙staly po v²padku pole alespo≥ ΦßsteΦn∞ pou╛itelnΘ, m∙╛eme se pokusit o obnovenφ pole nßsledujφcφm zp∙sobem, op∞t s vyu╛itφm direktivy failed-disk. Utilita mkraid v podstat∞ pouze zapφ╣e na oddφly RAID svazku superbloky a nastartuje pole - nijak tedy nem∞nφ obsah oddφl∙. Teprve jadern² ovladaΦ RAIDu spou╣tφ rekonstrukci a tomu m∙╛eme zabrßnit tφm, ╛e pomocφ mkraid pole znovu inicializujeme, ale pouze v degradovanΘm re╛imu (upravφme raidtab). Pole pak m∙╛eme p°ipojit s p°φznakem pouze pro Φtenφ a zjistit, nakolik jsou data na svazku pou╛itelnß. Toto m∙╛eme podle pot°eby opakovat a postupn∞ z pole vynechat jin² z disk∙, kterΘ z pole v dob∞ havßrie vypadly, a╛ najdeme takovou kombinaci, p°i kterΘ je souborov² systΘm po╣kozen nejmΘn∞ (m∙╛eme zkusit spustit fsck). Potom m∙╛eme svazek p°ipojit i pro zßpis a pomocφ fsck souborov² systΘm naostro opravit. Na zßv∞r m∙╛eme p°idat i poslednφ chyb∞jφcφ disk pomocφ raidhotadd, co╛ vede ke spu╣t∞nφ rekonstrukce pole. Tato metoda ale p°edstavuje krajnφ °e╣enφ a rozhodn∞ od nφ nelze oΦekßvat zßzraky.
Kdy╛ se zm∞nφ po°adφ Φi jmΘna disk∙Pokud se zm∞nφ po°adφ nebo jmΘna za°φzenφ (nap°. p°idßnφ dal╣φch disk∙ Φi periferiφ), kterΘ tvo°φ RAID svazek a nepou╛φvßme automatickΘ startovßnφ RAIDu jßdrem p°i bootu, musφme odpovφdajφcφm zp∙sobem upravit konfiguraΦnφ soubor /etc/raidtab a p°φpadn∞ pole znovu inicializovat pomocφ mkraid -force (pozor - pouze pro ty, kte°φ v∞dφ, co d∞lajφ). Pokud pou╛φvßme vlastnost "raid autodetect" jßdra, ovladaΦ RAIDu si poradφ sßm a pole sestavφ a spustφ podle informacφ ulo╛en²ch v RAID superblocφch diskov²ch oddφl∙.
Roz╣φ°enφ pole, konverze raidu na jin² typUtilita raidreconf, kterou p∙vodn∞ vyvφjel Jakob Oestergaard, nynφ vyvφjenß jako open source aktivita Connexem, umφ zmen╣ovat, zv∞t╣ovat RAID 0 a 5 svazky, p°evßd∞t svazky typu RAID 0 na RAID 5, p°idat nov² disk do RAIDu 1 a 5, vytvo°it pole RAID 0 ze samostatn²ch disk∙. Tato utilita ale nenφ dostateΦn∞ testovßna, tak╛e pozornΘ Φtenφ manußlu a zßloha je naprostou nutnostφ! Spolu s utilitou resize2fs je tedy mo╛nΘ tedy mo╛nΘ m∞nit i velikost polφ.
Boot raidJe mo╛nΘ provozovat ko°enov² svazek na RAIDu, a to typu linear, RAID 0 a RAID 1. Konfigurace star╣φch verzφ LILa byla sice trochu problematickß, ale novΘ verze LILa ji╛ RAID podporujφ p°φmo, viz Software-RAID-0.4x-HOWTO (ke star╣φ verzi RAIDu), Boot+Root+Raid+LILO HOWTO (k novΘ verzi RAIDu).
Jak potlaΦit autodetekci RAID polφPokud mßme jßdro s podporou autodetekce RAID polφ a z n∞jakΘho d∙vodu pot°ebujeme autodetekci doΦasn∞ vypnout, m∙╛eme jßdru p°i startu zadat parametr raid=noautodetect.
RAID a swapV souvislosti s RAIDem se Φasto diskutuje o tom, zda mß smysl vytvß°et odklßdacφ oddφly na RAIDu a kdy╛ ano, tak jak² typ pole pou╛φt. Tady je zapot°ebφ vzφt v potaz omezenφ danß ovladaΦem RAIDu (viz v²╣e omezenφ platnß pro jßdra 2.2.x) a dßle se musφme rozhodnout, zda nßm jde o zrychlenφ swapovßnφ, nebo o robustnost systΘmu. Pokud nßm jde o rychlost, m∙╛eme jako odklßdacφ oddφl pou╛φt svazek RAID 0; ov╣em podobnΘho efektu m∙╛eme dosßhnout i bez pou╛itφ RAIDu a to tak, ╛e v /etc/fstab uvedeme u odklßdacφch oddφl∙ stejnou prioritu:
/dev/sda3 none swap sw,pri=1 /dev/sdb3 none swap sw,pri=1 Pou╛φvat pro swap RAID 0 je tedy v podstat∞ zbyteΦnΘ. Naopak v p°φpad∞, ╛e nßm jde o robustnost systΘmu, m∙╛eme pro odklßdacφ oddφl s v²hodou pou╛φt RAID 1 svazek. SystΘm pak s v²padkem disku nep°ijde o Φßst swapu.
V²kon a stabilitaNejprve srovnejme v²kon softwarovΘho raidu pod jßdry 2.2 a 2.4: RAID 0 je rychlej╣φ u jader 2.4, RAID 1 je na tom zhruba stejn∞, RAID 5 byl na °ad∞ 2.4 z poΦßtku v²razn∞ pomalej╣φ, i kdy╛ toto se v poslednφ dob∞ rychle m∞nφ a nynφ je v²kon srovnateln² nebo lep╣φ. Pokud jde o srovnßnφ rychlosti softwarovΘho RAIDu a hardwarov²ch °e╣enφ, softwarov² RAID je oproti hardwarovΘ implementaci samoz°ejm∞ nßroΦn∞j╣φ na systΘmovΘ prost°edky, ale na druhou stranu b²vß mnohdy rychlej╣φ (v²razn∞ rychlej╣φ b²vß zejmΘna RAID 0). (Poznßmka: pro vylep╣enφ v²konu RAIDu 1 p°i Φtenφ existuje zßplata ovladaΦe RAIDu "readbalance".)Pokud jde o robustnost implementace, stabilita RAIDu typ∙ linear, RAID 0 a 1 je pom∞rn∞ vysokß, naopak nasazenφ RAIDu 5 v ostrΘm provozu je╣t∞ nelze doporuΦit. V tΘto souvislosti je╣t∞ zmφnφm jednu vlastnost LinuxovΘ implementace softwarovΘho RAIDu: V p°φpad∞ jakΘkoliv I/O chyby ovladaΦ RAIDu okam╛it∞ dan² diskov² oddφl z RAIDu vy°adφ, bez ohledu na to, jestli se jednß o chybu fatßlnφ, anebo o p°φpad, kdy by t°eba staΦilo danou I/O operaci zopakovat. Jin²mi slovy disk, kter² obΦas vrßtφ n∞jakou chybu, ale je nadßle vφce mΘn∞ schopn² fungovat (a kter² by systΘm nadßle pou╛φval, pokud by nebyl souΦßstφ RAID svazku, ale byl p°ipojen² jako samostatn² oddφl), linuxov² ovladaΦ p°estane pou╛φvat. Tφm se zbyteΦn∞ sni╛uje robustnost RAIDu, proto╛e snadn∞ji m∙╛e dojφt k situaci, kdy z pole vypadne postupn∞ i vφce disk∙, ne╛ kolik je k provozu danΘho pole t°eba a pole zhavaruje. Proto lze doporuΦit pou╛itφ rezervnφch disk∙ a vyhnout se shßn∞nφ rezervnφho disku na poslednφ chvφli, kdy u╛ pole mezitφm b∞╛φ v degradovanΘm re╛imu. Ze srovnßnφ softwarov²ch RAID implementacφ Linuxu, Windows 2000 a Solarisu vypl²vß, ╛e linuxov² RAID ve v²chozφm nastavenφ provßdφ rekonstrukci se snφ╛enou prioritou a limitovanou rychlostφ, tak╛e probφhajφcφ rekonstrukce mnohem mΘn∞ negativn∞ ovliv≥uje v²kon systΘmu po dobu rekonstrukce. (Poznßmka: V odkazovanΘm srovnßnφ ov╣em auto°i opakovan∞ chybn∞ uvßd∞jφ absenci n∞kter²ch vlastnostφ linuxovΘ softwarovΘ implementace RAIDu.)
Zßv∞remSoftwarov² RAID je cenov∞ lßkavou alternativou nßkladn²ch hardwarov²ch °e╣enφ. Dal╣φ v²hodou je flexibilita (nap°. mo╛nost sestavenφ pole v degradovanΘm re╛imu, mo╛nost eventußlnφ ΦßsteΦnΘ zßchrany dat v p°φpad∞ v²padku celΘho pole, proto╛e je znßmß struktura dat v diskovΘm poli, konverze RAID svazk∙ z jednoho typu RAIDu na jin²). N∞kterΘ z t∞chto mo╛nostφ jsou ale spφ╣e experimentßlnφho rßzu. Za spolehlivΘ lze oznaΦit implementace RAIDu typu linear, RAID 0 nebo RAID 1. Softwarov² RAID je nßroΦn∞j╣φ na systΘmovΘ prost°edky ne╛ hardwarovß °e╣enφ, n∞kterΘ typy (zejmΘna RAID 0) ov╣em mohou b²t v²razn∞ rychlej╣φ ne╛ hardwarovΘ varianty. Je tedy na adminstrßtorovi, aby zvß╛il v²hody a nev²hody sofwarovΘho Φi hardwarovΘho RAIDu vzhledem k aktußlnφm podmφnkßm.
Tento Φlßnek ani v nejmen╣φm nenahrazuje dokumentaci k ovladaΦi LinuxovΘho
softwarovΘho RAIDu Φi obslu╛n²m utilitßm - proto zde a╛ na v²jimky zßm∞rn∞
nejsou komentovßny p°epφnaΦe obslu╛n²ch utilit. D∙kladnΘ Φtenφ dokumentace
(nebo v p°φpad∞ nejasnostφ studium zdrojovΘho k≤du - dokumentace bohu╛el
stßle nenφ ·plnß) by m∞lo b²t samoz°ejmostφ, rovn∞╛ existuje konference
linux-raid s prohledßvateln²m
archφvem.
A je╣t∞ ·pln∞ poslednφ poznßmka na zßv∞r:
nezapomφnejme, ╛e (redundantnφ) RAID chrßnφ pouze p°ed v²padkem urΦitΘho
poΦtu disk∙ a rozhodn∞ nenahrazuje nutnost pravidelnΘho zßlohovßnφ dat.
|
|||