
Počítače kódují písmena jako čísla. Čísla od 0 do 32 jsou systémové znaky, od 33 do 127 jsou znaky anglické abecedy (plus znaky typu závorek a zavináčů) a čísla od 128 do 255 jsou různé národní znaky. Jejich přiřazení číslům se označuje jako kódování.
V současnosti se vyskytuje několik takových kódování češtiny. Zde jsou zobrazeny tabulky pro dvě nejčastější česká kódování (win a iso), dvě řidší česká kódování (dos a mac) plus tabulka Latin 1, se kterou se našinec též často potká.
Výsledné zobrazení je závislé také na použitém fontu. Použil jsem písmo Times New Roman CE z Windows (výchozí znaková sada win-1250), obrázky jsou sejmuté z testovací stránky prohlížečem Mozilla. Protože ne všechny znaky všech kódování toto písmo pokrývá, někde se zobrazují otazníky, jinde obdélníčky. Při použití ne-windowsích písem by zobrazení byla trochu jiná, ale zjišťováním všech kombinací bych pak mohl strávil prázdniny.
Kdo chce zjistit kód znaku, musí si sečíst čísla v záhlavích tabulky.
Standardní české kódování používané na Unixu, Linuxu a akceptované i systémem Windows. V Internet Exploreru je označováno jako středoevropské (ISO).
Windowsovské kódování v prohlížečích Internet Explorer označované jako středoevropské.
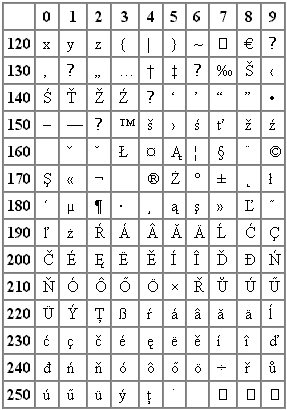
Ve výstupech ze straších programů se lze setkat s dosovským kódováním.

Macintoshovské kódování pro střední Evropu

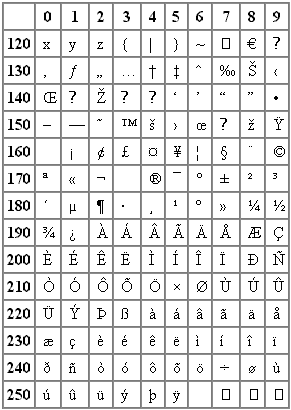
Označuje se jako západoevropské jazyky. V prohlížečích se zobrazuje, pokud dokument neobsahuje žádné informace o kódování (meta tag nebo http hlavičku).
Předchozí: Diagnostická stránka
Vizte též: Pojednání o češtině, Rozdíly kódování, Testovací stránka
Obsah
Hledání
Základní kurs
Editory
HTML tipy
Provoz webu
CSS styly
Jak psát web:
http://dusan.pc-slany.cz/internet/
Píše Yuhů: autorova stránka, mail: dusan@pc-slany.cz
Poslední aktualizace 27.07.2001
