a) závislé na řečníkovi - jsou vyvíjeny pro práci s jedním řečníkem. Jsou to nejjednodušší typy, jejich vývoj je poměrně snadný, jsou levnější a většinou přesnější, ale nejsou tak flexibilní jako další typy.
b) nezávislé na řečníkovi - jsou schopny pracovat s jakýmkoliv řečníkem určitého typu (např. řečníkem mluvícím češtinou, či americkou angličtinou, apod.). Vývoj těchto systémů je nejsložitější, systémy jsou nejdražší a nejsou tolik přesné jako systémy závislé na řečníkovi. Nicméně jsou flexibilnější a mají větší rozsah použití, než systémy závislé na řečníkovi.
c) adaptivní - jsou vyvíjeny s cílem přizpůsobovat se vlastnostem nových řečníků. Jejich složitost je někde mezi systémy nezávislými a systémy závislými na řečníkovi.
Systémy můžeme také porovnávat podle velikosti slovníku. Nejsou sice na rozdělení dle velikosti žádné ustálené definice, vžité jsou ale přibližně tyto hodnoty:
malý slovník - desítky slov
střední slovník - stovky slov
velký slovník - tisíce slov
velmi velký slovník - desítky tisíc slov
Rozpoznávání řeči začíná vzorkováním řeči - to se provádí "klasickými" metodami (mikrofon, zesilovač, D/A převodník).
Další stupeň je zpracovaní akustického signálu. Nejpoužívanější techniky jsou různé techniky spektrální analýzy
2 Metody rozpoznávání slabik
Existuje mnoho důvodů, které podporují důležitou artikulační a percepční roli slabiky, včetně na slabice založeném přízvuku a rytmu. Existuje však i několik nevýhod spojených s užíváním slabiky jako jednotky pro segmentaci. Především neexistuje, jak již bylo naznačeno, obecný souhlas z fonetického i lingvistického hlediska o tom, kde mají být umístěny hranice slabik. Slabičná hranice je zřetelná pouze v posloupnostech, v nichž se střídají fonémy souhláskové a samohláskové. Je-li mezi dvě sousední jádra vložena souhlásková skupina, povědomí slabičné hranice mizí a fonologická teorie dosud neobsahuje pravidla, která by slabičnou hranici přesně stanovila. Další nevýhodou je značný počet existujících slabik; v mluvené češtině to je více než 10000.
Příslušnost souhlásky ke konci určité slabiky či na začátek slabiky následující je tedy víceméně sporná. Je určena dělením ve frázování řeči a může plynout z konkrétní výslovnosti. Umístění slabiky je též silně ovlivněno lexikálními a gramatickými vlivy.
Určitým zobecněním a také rozvinutím rozpoznávání slabik je použití poloslabiky jako rozpoznávací jednotky. Takto může být zredukován inventář slabik. Každá slabika může být totiž pokládána za kompozici počáteční poloslabiky, obsahující počáteční souhláskový shluk a příslušné části slabikového jádra, plus koncové poloslabiky, obsahující zbývající část samohláskového jádra a koncový souhláskový shluk. Užitím poloslabikových jednotek lze redukovat až 5krát rozměr inventáře vyžadovaného pro reprezentaci promluv ve srovnání s celými slabikami. Nicméně i užití poloslabik zavádí určitou složitost s rozdělováním samohláskového jádra. Jestliže například je hranice mezi počáteční a koncovou poloslabikou vytvořena ve středu samohláskového jádra, musí být věnována zvláštní péče procesu porovnávání samohlásky na obou stranách hranice, zvláště jsou-li samohlásky následovány sonorními hláskami (tj. l, r, j, m, n, ň).
Další možností je poté použití demislabik. Ty se od půlslabik liší umístěním hranice mezi počáteční a koncovou demislabikou. Počáteční demislabika je vymezena zcela krátce tak, že rozdělující hranice je umístěna těsně za přechod CV (tj. počáteční demislabika obsahuje koartikulační jev, ale neobsahuje podstatnou část samohlásky). Umístění hranice tímto způsobem je efektivní tím, že uvolňuje omezení na obou stranách hranice a má i potenciál v redukci inventáře, podobně jako u půlslabik.
Obtíže při identifikaci slabik lze v mnoha případech zobecnit. Například akustická realizace závisí jak na předcházejícím a následujícím zvuku, tak i na tempu a intonaci řeči. Tato závislost je známa jako koartikulace a zavádí určité "splývání" výslovnosti některých dvojic či skupin hlásek.
Přístup k rozpoznávání řeči pomocí slabik je výhodný hlavně pro slabikově frázované jazyky. Toto umožňuje se lépe vyrovnat s koartikulací a také umožňuje "obejít" mnohé ostatní vlivy výslovnosti, protože tyto jsou těsně svázány se slabikami. Další potíží je, že v běžné mluvě se logické dělení na slabiky nedodržuje a zejména v případě rychlé mluvy jsou nejen komoleny hlásky, ale také frázování neodpovídá mluvnickému členění na slabiky. Z tohoto důvodu je dobré rozlišit pojmy slabika a slabikový segment. V rámci rozpoznávání je poté potřeba tento nesoulad mezi očekávanou a přirozenou mluvou zohlednit. Dále je nutno mít na paměti spoluvyslovování některých spojení slabik a brát v ohled pouze rozumný počet takto utvářených segmentů řeči. Právě velké množství slabik je složitá úloha, která je důležitá a je nutno ji zde řešit, za prvé rozřešením problému slučování slabik a za druhé vytvoření databáze slabik, kterou samozřejmě nelze vytvářet ručně.
Vnímání hranic slabik je subjektivní a tedy nejednoznačné. Mezi výhody slabik patří také to, že lze při další analýze použít poznatky získané z lingvistiky. Například pravidelnost přízvuku (dobře patrnou v češtině) lze využít pro zjištění začátku slov. Prozódie je svázána s výslovností, a protože rozbor na úrovni slabik umožňuje se takto mluvou zabývat, je zde možnost využití takto získaných poznatků pro lepší porozumění například rychlé či jinak ovlivněné mluvy. Jedním z prvních kroků k dosažení těchto výhod je určení přízvuku. Dobré výsledky této metody byly experimentálně prokázány. Na takto získaných výsledcích lze dále uplatnit např. statistické metody. Ve většině případů intenzita zvuku se snižuje na hranicích slabik. V mnoha případech však toto snížení není výrazné a musí se počítat s koartikulací (např. slovo "kolo").
Dalším důležitým poznatkem je zde též možnost a výhodnost použití statistického přístupu při určování slabik či slabikových jednotek, které mají být zařazeny do omezeného slovníku. Důvodem tohoto omezení je velký celkový počet slabik jako takových a tudíž nerealizovatelnost jejich identifikace bez určitých úprav či omezení.
Před vlastním zpracováním řečového signálu se často využívá tzv. preemfáze. Preemfáze znamená zdůrazňování amplitud spektrálních složek řečového signálu s jejich vzrůstající frekvencí. Důvod tohoto procesu vyplývá právě z opačného chování řečového ústrojí, tj. poklesu amplitud spektrálních složek řečového signálu na vyšších frekvencích. Preemfáze tento pokles v jisté míře kompenzuje, takže dojde k relativnímu vyrovnání energetického spektra celého přenášeného pásma.
Příkladem určení hranice slabiky může být zjišťování energetických minim [16] (jiný přístup je např. v [7]). Funkci krátkodobé energie signálu lze definovat vztahem
kde s(k) je vzorek signálu v čase k a w(n) je příslušný typ okénka. Při měření krátkodobé energie lze doporučit délku mikrosegmentu 10-20 ms při frekvenci vzorkování 8-10 kHz. Hodnoty funkce krátkodobé energie poskytují pro každý mikrosegment informaci o průměrné hodnotě energie v mikrosegmentu. Jedním z nedostatků této charakteristiky je její značná citlivost na velké změny úrovně signálu. Již tak vysoká dynamika řečového signálu je díky kvadrátu v (1) ještě zvýšena. Z těchto důvodu se velmi často využívá krátkodobá intenzita, která zmíněný nedostatek nemá,
Hodnoty krátkodobé energie i krátkodobé intenzity mohou být využity například při automatickém oddělování segmentu ticha od segmentu řeči, lze jich též využít při oddělování znělých a neznělých částí promluvy.
1. Rekurentní sítě
Rekurentní sítě mají systém vnitřních zpětných vazeb a tedy i kreativní chování. Odezva rekurentní sítě je díky existenci vnitřní zpětné vazby silně časově závislá. Po vložení jistého vstupního signálu je určena příslušná výstupní hodnota a ta je současně znovu přivedena na vstup, který modifikuje. Při procesu učení rekurentních sítí se vychází z jistého počátečního stavu sítě a jejích postupné změny probíhají dokud není dosaženo stabilního stavu.
Mezi těmito sítěmi zaujímá významné místo Hopfieldova síť.
Stav sítě je možné vyjádřit souborem průběžných stavů výstupních signálů všech výkonových prvků. V původní Hopfieldově síti se mohl stav každého prvku měnit nezávisle v náhodných časových intervalech. U pozdějších verzí se obvykle uvažuje synchronní měna stavů všech prvků. V současné době se používají Hopfieldovy sítě ve smyslu asociativní paměti, dále se skutečnosti že Hopfieldova síť po konečném čase dosáhne lokálního minima energie využívá k řešení některých optimalizačních úloh, včetně NP-těžkých, případně NP-neúplných.
2. Vrstvené sítě
Vrstvená síť je síť s vstupní vrstvou dimenze m, výstupní vrstvou dimenze n a r skrytými vrstvami o obecně různých dimenzích.
Neurony sousedních dvou vrstev jsou propojeny systémem každý s každým. Síť se může nacházet ve dvou módech: tréninkovém a pracovním.
V pracovním módu je na vstup sítě přiveden vstupní vektor (dotaz) a z výstupní vrstvy je odečtena odezva sítě na tento stimul (odpověď). Problémem je k vrstvené síti s již danou topologií (počtem vrstev a neuronů v nich) najít váhy všech spojů. Náhodně zvolené váhy nebudou zřejmě odpovídat zobrazení, které má síť realizovat. V procesu adaptace (učení) je třeba váhy upravit. Dosud neexistuje metoda nezaručuje že (v konečném čase dospějeme) k ideálnímu bodu. Následuje přehled nejužívanějších metod:
Typickým příkladem jsou metody minimalizující globální chybu sítě definovanou jako sumu čtverců rozdílu žádaných a vypočítaných hodnot, existují ale i jiné hodnoty.
Vrstvené sítě s pevnou topologií které využívají gradientních metod jsou nejrozšířenější a historicky nejstarší. Patří mezi ně sítě typu Back-propagation, RBF a další.
Sítě s měnící se topologií jsou využívány především ke zrychlení reálných aplikací. Neuronové sítě jsou při použití v reálných úlohách velmi výpočtově náročné (obsahují velké množství spojení). Myšlenka sítí s dynamicky se měnící topologií většinou spočívá v inicializaci sítě s minimálním počtem neuronů, tréninkem a následným přidáváním dalších neuronů do sítě dle vhodně zvoleného kritéria. Z těchto sítí se prosadila především architektura kaskádová korelace.
Tato síť začíná učení bez skrytých neuronů, pro adaptaci používá gradientní metodu (minimalizaci globální chyby sítě). Pokud se vývoj chyby blíží k asymptotě je do sítě přidán skrytý neuron, jehož váhy jsou vypočteny na základě reziduální chyby sítě. Po připojení do sítě se již váhy přidaného neuronu nemění. Tímto způsobem je postupně vytvořena kaskádová topologie. Sítě tohoto typu se osvědčili především jako detektory vyšších řádů.
V [13] uvádějí autoři tyto výhody neuronových sítí při rozpoznávání plynulé řeči:
Během výslovnosti slabiky jsou průběžně aktivovány jednotlivé buňky slabikové vrstvy. Jakmile je ve fonotopické vrstvě aktivována buňka ticha, všechny buňky hláskové a fonotopické vrstvy jsou resetovány, přičemž záznam vyslovené slabiky ve slabikové vrstvě zůstane.
Tato slabiková vrstva má několik vlastností, které dovolují, aby výslovnost víceznačných spojení byla jednoznačně rozpoznána. První z nich je vzájemné ovlivňování. Sice neexistuje žádná interakce mezi buňkami, které jsou aktivovány v čase různých slabik, ale každé dvě slabikové buňky aktivované "zároveň" se navzájem ovlivňují. Takto se zaručuje, že nebudou vzájemně potlačeny a umožní, aby výsledné rozhodnutí o vyslovené slabice učinily vyšší vrstvy, tedy vrstva slovní a případně gramatická. Dochází tímto k možnému omezení počtu slabikových buněk, protože je využita kombinace více buněk.
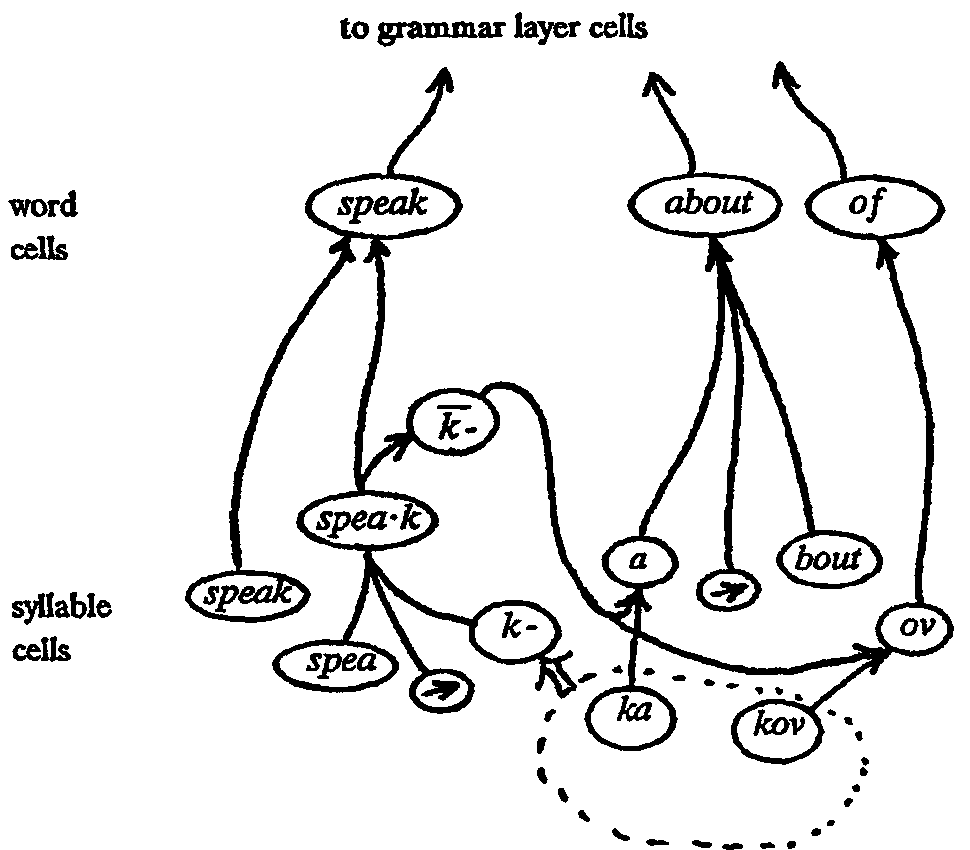
Obr.1: Ilustrace alternativního slabikování
Tento výsledek nevyhovuje pro porozumění smyslu fráze. S tímto se systém, který rozpoznává také slova, vyrovnává porovnáváním zjištěného slabikování a aktivních buněk, které jsou zaktivovány pro jednotlivé předpony a přípony slabik. Takto se například s pomocí aktivních buněk "spea" a "k-" získá vyhovující slovo "speak". (Jde o náhradní vstup slovní buňky "speak"). Dále je poté aktivována buňka " -", která značí, že souhláska "k" jako předpona spojení "ka" může být vynechána. Vznikne takto "a" jako výsledek současné aktivace " -" a "ka". Buňky "a" a "ka" však zůstanou aktivní obě, protože se může jednat o splynutí výslovností konce jednoho a začátku dalšího slova, kde "k" může náležet oběma slovům.
Po takto provedeném přizpůsobení na vstupní množinu frází může dojít k přesunu souhlásky i bez uvedení nového určení náhrady ve slovní vrstvě. Příklad na Obr. 1, převzatý z [13], ukazuje takto vytvořené spojení pro přeslabikování "spea-kov" na "speak of", kdy vytvoření nové definice není potřebné, protože je využito již existující struktury.
Oproti metodě DTW je nevýhodou skrytých Markovových modelů pracnost a časová náročnost při trénování parametrů modelu (i pro případ malých slovníků, neboť pro vytvoření spolehlivého modelu slova je třeba značné množství trénovacích promluv).
3 Metody potlačení hluku
V minulosti se vylepšování řečového signálu zaměřovalo na potlačení aditivního hluku na pozadí. Z pohledu signálového zpracování je snazší se vyrovnat s aditivním šumem. Navíc vzhledem k přirozenému dělení řeči je možné sledovat samotný šum v pauzách, což může být velice užitečné.
Vylepšování řeči je velmi speciální případ odhadování signálu, protože mluva je nestacionární a lidské ucho se neřídí jednoduchými matematickými mírami chyb. Proto je potřeba mít také měření subjektivní srozumitelnosti a kvality. Cílem tedy je optimální odhad získaný měřením hluku.
Metody používající pouze jeden mikrofon zde jsou
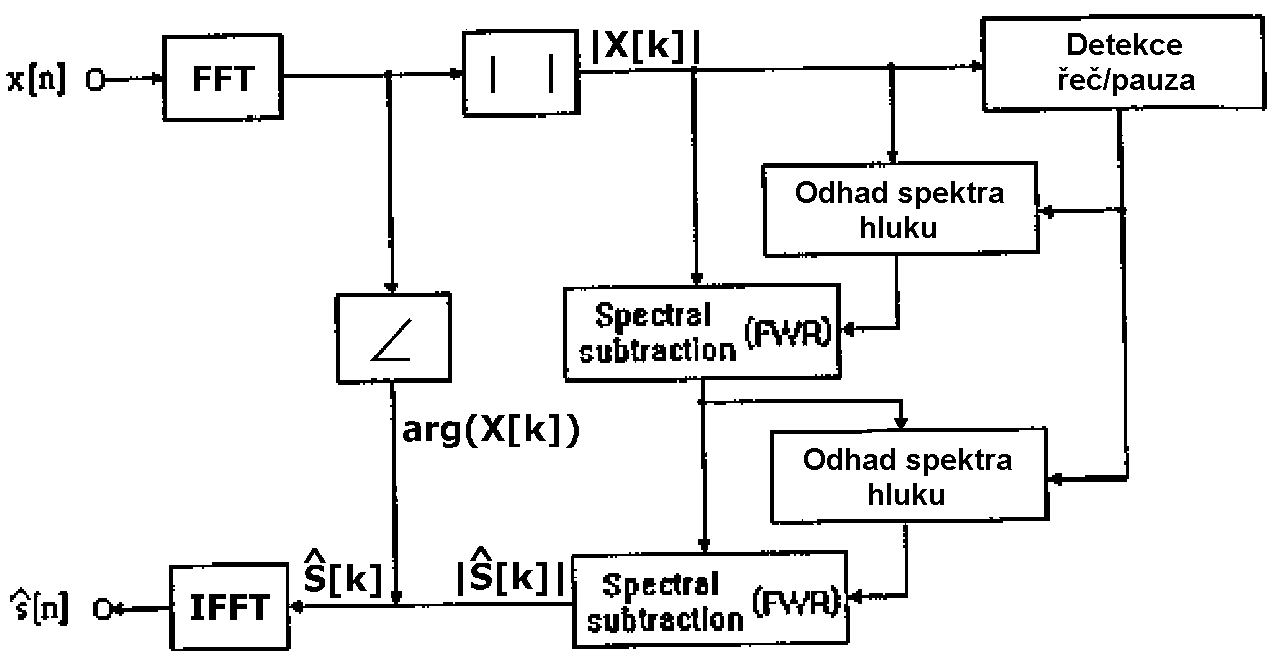
Obr.2: Diagram principu cinnosti metody spektrálního odecítání
Hlavní výhodou metody spektrálního odečítání je její jednoduchost. Narozdíl například od metod využívajících více mikrofonů k nalezení a odlišení mluvy od okolního hluku, v případe odhadu hluku v pauzách řeči, lze spektrálním odečítání použít i pro jednomikrofonové snímání. Dalším kladem je také možnost nastavení odfiltrování pomocí počtu jeho “opakování”, jak je znázorněno na obrázku.
Detektor pauzy slouží k získání vzorku hluku. Pokud znám odhad hluku na pozadí, mohu podle jeho charakteristik dostat roztřídění a rozeznání zdroje hluku. Dobrý odhad spektra je omezen efektem hudebních tónu. Existuje sice několik metod na omezení tohoto efektu, přesto jejich nevýhodou je i to, že zkreslují výslednou “vylepšenou” řeč.
Metody spektrálního odečítání se liší zejména způsobem odhadu a odečtení hluku. Některé z nich jsou:
Detektory řeč/pauza mohou fungovat na různých principech. Některé z nich například jsou [15]:
Vhodné se z teoretického hlediska ukazují systémy založené na vlnkové transformaci, protože si lze představit úvodní smyslové zpracování jako určitý druh vlnkové transformace následované kompresním nelineárním systémem.
Nevýhodou této metody je nutnost odečíst hluk v pauzách řeči. Pokud jsou tyto pauzy špatně určeny, tak je potom celý proces odečítání mnohem méně účinný, či dokonce znehodnocuje samotný užitečný řečový signál. Proto byly vyvinuty metody, které na základě takto získaného odhadu šumu dokáží tento rušivý signál na pozadí řeči rozeznat i během samotné mluvy a tím zvýšit schopnost potlačení hluku oproti prostému spektrálního odečítání popsanému výše. Tímto však roste také složitost metody a vyžaduje dobré nastavení parametrů, aby byl nejen správně určen úsek řečové aktivity, ale také byla samotná mluva dobře odlišena od hluku jež na pozadí zůstal.
4 Závěr
Obecně lze říci, že existují základní dva přístupy, které se týkají úkolu vyrovnání se s hlukem. Jednou možností je předem upravit zdrojový signál tak, aby v něm byl hluk omezen. Druhým přístupem je užití dostatečně odolného postupu rozpoznávání slabik, který je schopen překlenout i zkreslení dané zahlučeným prostředím.
Vzhledem k tomu, že popsané metody rozpoznávání slabik jsou většinou založeny na naučení se vzoru mluvy v bezhlučném prostředí, je jejich schopnost odolávat hluku z principu omezená. Srovnávání jejich odolnosti je obtížné s ohledem na velké množství struktur, jimiž je možné tyto metody realizovat. Obecně je však v případě silného hluku nutné vždy použít některou z metod na jeho omezení.
Metody potlačení hluku se dělí hlavně dle počtu signálů (počtu mikrofonů), které mají k dispozici na vstupu. Zmíněny byly zejména metody: spektrální odečítání (typické pro jeden použitý mikrofon), obecné vícemikrofonové snímání a využití typických vlastností řeči pro její odlišení od zahlučeného pozadí (uveden je přístup inspirovaný lidských sluchem).
Důležitým hlediskem je složitost zpracování. Posuzovaná hlediska závisí hlavně na dostupných prostředcích. Zatím však nebyla určena obecně nejvhodnější metoda, tedy taková, která by umožnila nejspolehlivější rozpoznání. Nároky systému se týkají především snímání zvuku a poté jeho úpravy k získání výsledku. Samotná identifikace zasahuje oblast výpočetní náročnosti při úpravě a rozpoznávání. Prostředky využité při snímání jsou ovlivněny zejména požadavky na omezení hluku. Hlavním hlediskem je potřebný počet mikrofonů (prostorová náročnost) a jejich případná směrovost.
Literatura
http://noel.feld.cvut.cz/~pollak/publ/eur93.pdf
[2] Survey of the State of the Art in Human Language Technology [online]. Vydáno 21. listopadu 1995. [cit. 2001-02-08]. Formát PostScript i HTML. Dostupné z URL:
http://cslu.cse.ogi.edu/HLTsurvey/HLTsurvey.html
[3] Hanžl, Václav. Strukturalizace systému pro rozpoznávání řeči [online]. [cit. 2000-12-07].
http://noel.feld.cvut.cz/speechlab/publ/
http://noel.feld.cvut.cz/cgi-bin/man.cgi?section=1&topic=ghostview
[4] Ingerle, Jan. Semestrální práce z předmětu ASI : Potlačování šumu v řeči na bázi spektrálního odečítání. Praha, 2000. 4 s. Semestrální práce z předmětu ASI na Fakultě elektrotechnické Českého vysokého učení technického na Katedře teorie obvodu. [online]. Poslední revize 29. října 2000 [cit. 2000-12-08].
http://amber.feld.cvut.cz/user/xingerle/files/asi.pdf
http://amber.feld.cvut.cz/user/xingerle/files/asi.ps
[5] Ingerle, Jan - Štrupl, Miroslav. Study of Multisensor Beamformer [online]. 2000. Czech-German Speech Processing Workshop 2000. [cit. 2000-12-08].
http://amber.feld.cvut.cz/user/xingerle/files/ws2000.pdf
http://amber.feld.cvut.cz/user/xingerle/files/ws2000.ps
[6] Rothkrantz, L.J.M. - Nollen, D. Speech Recognition using Elman Neural Networks [online]. 1999 [cit. 2000-12-08].
http://link.springer.de/link/service/series/0558/bibs/1692/16920146.htm
[7] Kopeček, Ivan. Speech Recognition and Syllable Segments. In Proceedings of the International Workshop on Text, Speech and Dialogue - TSD’99. Berlin Heidelberg New York : Springer-Verlag, 1999., s. 203-208. Lectures Notes in Artificial Intelligence 1692. ISBN 3-450-66494-7. CEZ:J07/98:143300003, zaměř. GA201/99/1248, projekt VaV. [online]. 1999 [cit. 2000-12-08].
http://link.spřinger.de/link/service/series/0558/bibs/1692/16920203.htm
[8] Kopeček, Ivan. Syllable Based Approach to Automatic Prosody Detection; Applications for Dialogue Systems. In Proceedings of the ESCA Workshop on Dialogue and Prosody. Veldhoven : European Speech Communication Association, 1999., s. 89-92. GA201/99/1248, projekt VaV. [online]. [cit. 2000-12-08].
http://www.fi.muni.cz/~kopecek/diapro99.ps
[9] Kopecek, Ivan. Syllable Segments in Czech. In Proceedings of the XXVII. Mezhvuzovskoy naucznoy konferencii, Vypusk 10. St. Petersburg : Univ. of St. Petersburg, 1998., s. 60-64. [online]. [cit. 2000-12-08].
http://www.fi.muni.cz/lsd/publications/stpb.ps
[10] Cohen, M. - Franco, H. - Morgan, N. - Rumelhart, D. - Abrash, V. Hybrid Neural Network/Hidden Markov Model Continuous Speech Recognition [online]. 1992, [cit. 2000-12-08].
http://www-speech.sri.com/projects/hybrid/papers/icslp.92.cohen.ps
[11] Abrash, V. - Cohen, M. - Franco, H. - Konig, Y. - Morgan, N. - Rumelhart, D. Combining Neural Networks and Hidden Markov Models for Continuous Speech Recognition [online]. [cit. 2001-03-19].
http://citeseer.nj.nec.com/197231.html
[12] Dobias, Ladislav. Metody a realizace hlasových vstupů a výstupů v robotice [online]. Předmět “Řízení robotů” FEL CVUT. 10.11.1998, poslední revize 8.12.1998 [cit. 2000-12-08].
http://cs.felk.cvut.cz/~xdobiasl/
[13] Noetzel, Andrew. Robust Syllable Segmentation of Continuous Speech using Neural Networks. In Electro International Conference Record, New York, 1991. p. 580-585. (Andrew Noetzel; Associate Professor; Polytechnic University, Department of Computer Science; 333 Jay Street, Brooklyn, NY 11201).
[14] Shim, Chongjoon - Espinoza-Varas, Blas - Cheung, John Y. A PC-based Neural Network for Recognition of Difficult Syllables using LPC Coefficient Difference. In International Joint Conference on Neural Networks, San Diego, California, 1990. p. II-185 - II-190. [15] Davidek, V. - Sika, J. - Stusak, J. Implementing a Noise Cancellation System with the TMS320C31 [online]. 1999, [cit. 2001-03-19].
http://www-s.ti.com/sc/psheets/spra335/spra335.pdf
[16] Psutka, Josef. Komunikace s počítačem mluvenou řečí. 1. vydání. Praha : Academia, 1995. ISBN 80-200-0203-0.