Analýzy a grafy
| Pokud Excel nepoužíváme jen jako zásobárnu dat, pak výsledkem naší práce jsou číselné hodnoty, které prezentujeme jako takové, nebo je zpracováváme do vizuální podoby - grafu. Příznivé výsledky vyzdvihneme (jako zdůvodnění obvykle postačí pár vět), nepříznivé bychom nejraději lidově řečeno zašlapali do země (hledání příčin může znamenat i vznik nové teorie). Excel každopádně alespoň v základu poskytuje nástroje pro analýzu získaných dat, pomůcky pro eliminaci chyb a dokonce cosi, co bychom mohli nazvat generátorem správných výsledků. Správně, jedná se o statistické nástroje. V dnešním díle se jim nevyhneme, ale ukážeme si jen cestu, kterou se dát, neboť toto téma je velmi obsáhlé a vyžaduje znalosti příbuzného oboru - teorie pravděpodobnosti. V přiloženém sešitu najdete dostatečnou zásobu ukázek. Začneme tím jednodušším - grafy. |
|
Pro tuto chvíli proto není předmětem zájmu tvorba grafů "pro oko". Jak můžou grafy vypadat z hlediska barevnosti, uspořádání nebo třeba velikostí písma, ukazují samotné příklady a je na čtenáři, aby s ukázkami experimentoval. Na webových stránkách (a možná i někdy na tomto místě) je námět designu v Excelu samostatně zpracován. Zde jen stručně a ryze prakticky:
 |
|
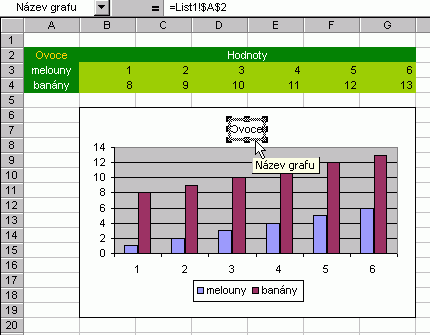
Věřím, že už znáte alespoň ty základní typy grafů, které Excel nabízí. Kdy jaký použít? Pokusím se alespoň nastínit některá použití:
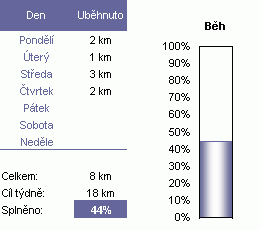
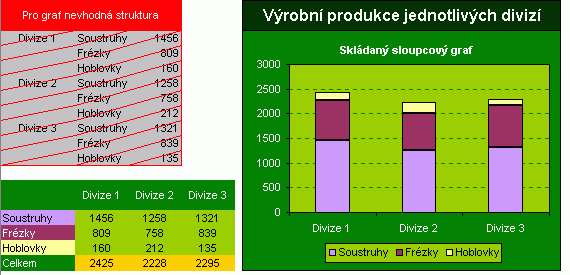
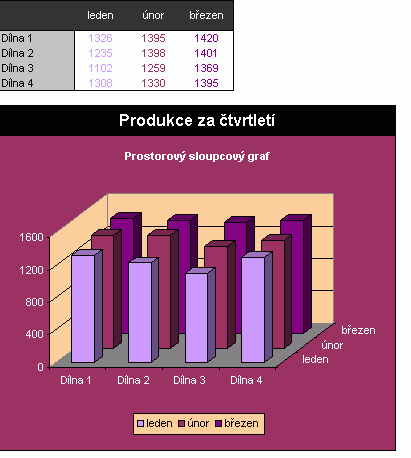
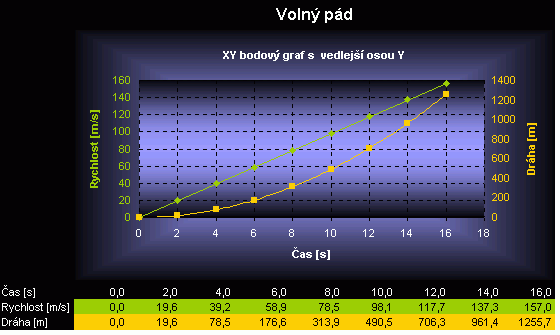

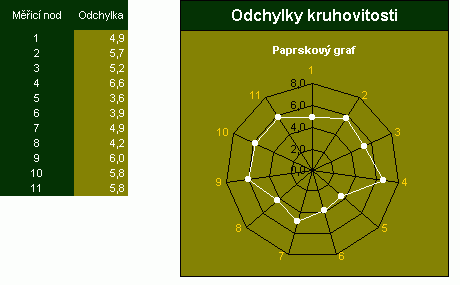
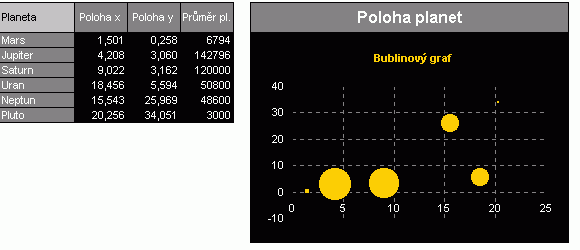
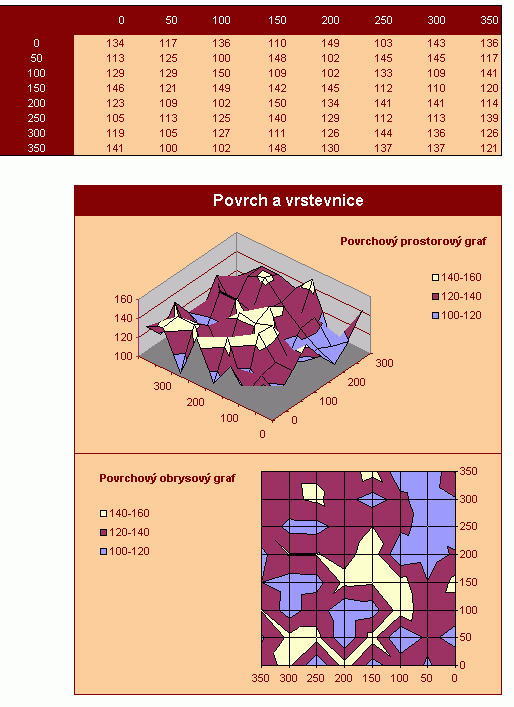
|
|
|
Předpokládejme, že máme za úkol vyhodnotit sadu dat, o které nám někdo řekl, že je náhodným výběrem hodnot z jediného určitého měření - nic víc, nic míň. K uspokojení sebe samých i zadavatele úlohy obyčejně stačí málo - říci, že hodnoty jsou (čtenář promine) "takové či makové plus minus trolejbus". Ono plus minus z pohledu statistiky znamená stanovit rozsah hodnot, ve kterém se všechny hodnoty budou nacházet, a to s určitou pravděpodobností. V daném případě nemusíme hloubat nad tím, jak data zprůměrovat - poslouží nám funkce PRŮMĚR pro aritmetický průměr. Hravě kupříkladu také dokážeme s pomocí funkcí MAX a MIN určit maximální a minimální hodnotu. Funkce MODE vrací nejčastější hodnotu (při absenci duplicitních hodnot vrací chybovou hodnotu #N/A). Ke stanovení tolerance, jež vymezí rozsah hodnot, slouží v Excelu funkce CONFIDENCE(alfa; směrodatná odchylka; počet). Hladina významnosti alfa (nejčastěji 0,05) znamená, že si přejeme získat toleranci vymezující takový interval, do něhož obecně všechny hodnoty budou spadat s pravděpodobností 100*(1-alfa)%. Směrodatná odchylka (v daném případě se jedná o výběr hodnot) se vypočte funkcí SMODCH.VÝBĚR. Pro kontrolu celkového počtu hodnot měření uplatníme funkci POČET. X-tou nejmenší a největší hodnotu obstarávají funkce LARGE a SMALL a zbytek můžeme zajistit již známými postupy pro podmíněný počet a součet. 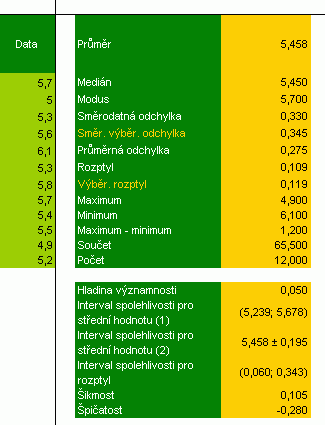
To podstatné...
Poznámka: Neberte prostý průměr jako samozřejmost. Je důležité znát alespoň význam váženého průměru (typické příklady průměrování dat ze skupin "hrušky a švestky", kdy je třeba zohlednit charakter "hrušek a švestek") a geometrického průměru (používaný např. ve finančnictví). |
Nemějte obavy, jen předestřu možnosti a nástroje "velké statistiky". Vše vychází z volby Nástroje / Analýza dat, jejíž zobrazení je podmíněno instalovaným doplňkem Analytické nástroje. Využití podnabídek vydá na půl roku studia a zkoušení... Následující dialog je s menšími obměnami obsažen v každém typu analýzy:
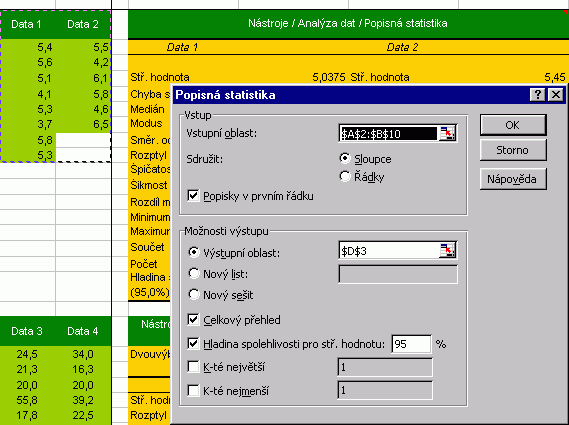
Ukázka výše se týká Popisné statistiky, což je téma, kterým doporučuji začít. Volba Popisné statistiky plně nahrazuje "ručně" získané hodnoty popsané v prvních krůčcích. Ovšem pozor! Výsledkem nejen této, ale všech nabídek Analýzy dat je tabulka statických hodnot, které se nemění při změně zpracovávaných hodnot! A co víc, při omylu a přepisu dat není funkční notoricky známé "Undo", nebo-li krok zpět. Domnívám se, že v tomto směru Excel (vyzkoušen 2000 a XP) zůstává v době kamenné. Stručně k dalším volbám:
Jsem si vědom snad až přílišné stručnosti v prostém vyjmenování metod. Není ovšem možné rozebrat kupříkladu t-testy. Bylo by nutné mluvit o vlastním Studentově rozdělení, říci, co se myslí rozdělením, mluvit o hypotézách, o jednostranných a oboustranných testech, o kvantilech, stupních volnosti, kritickém oboru, testovacích charakteristikách atd. A ani se nemohu tvářit, že tomu všemu rozumím na základě jednoho semestru pravděpodobnosti a statistiky :-). Bez výkladu teorie není dobré ani zmiňovat použití jednotlivých testů. V přiloženém sešitu je ovšem najdete. Tento článek také chápejte víceméně jako nastartování debaty a jistě se někdy dočká pokračování. Ano, objeví se v něm i grafy určené výhradně pro statistiku (krabicové a další). To podstatné...
|
|
Tímto bych se rád vrátil ke krátce zmíněným spojnicím trendu u grafů typu XY. Ty jsou totiž vytvářeny právě na základě regresní analýzy. 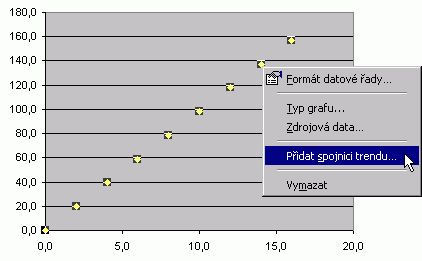
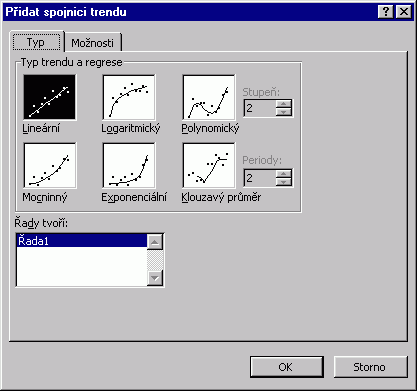
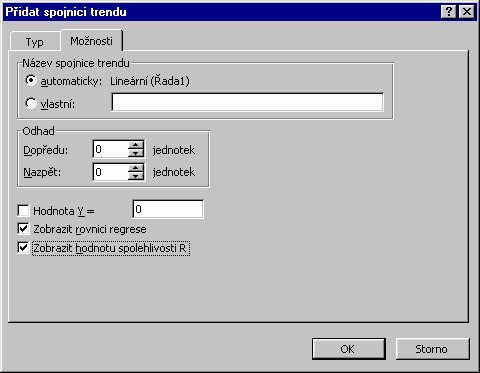
Spojnice trendu se vytváří při vybrané řadě datových bodů s využitím nabídky Přidat spojnici trendu v příručním menu. Na kartě Typ volíme druh regrese a na kartě Možnosti pak definujeme možnosti odhadu dalších hodnot směrem vpřed i vzad. Zpravidla stojíme o zápis rovnice proložené křivky a proto si zde zaškrtneme políčko Zobrazit rovnici regrese. Pozn. Hodnota spolehlivosti R je ve statistice nazývána koeficientem determinace. K hodnotám regrese a předpovědi hodnot můžeme přistoupit i funkcemi přímo z listu. Odhady budoucích hodnot lineární regrese vrací funkce LINTREND a FORECAST, pro zjištění koeficientů regresní přímky y=ax+b aplikujte funkce LINREGRESE a SLOPE, resp. INTERCEPT. U exponenciální regrese se užívají funkce LOGLINTREND a LOGLINREGRESE. |
|
Tato tématika v sobě obsahuje odpovědi na otázky typu "co by, kdyby", totiž sledujeme změnu finálního výsledku na základě změn proměnné či proměnných. První z podtémat se jmenuje Citlivostní analýza a její funkci najdete pod menu Data / Tabulka. Vyplněný dialog dvouvstupové citlivostní analýzy je uveden níže. Buňka F9 přitom obsahuje vzorec =G4+G5*$G$3. 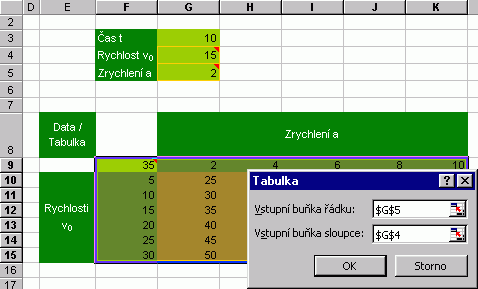
Narozdíl od Analýzy dat tato metoda vrací matici funkce TABELOVAT, jejíž obsah (výsledky závislosti proměnných podle předpisu v buňce F9) se přizpůsobuje změně vstupů. Druhou možností je použít Nástroje / Správce scénářů. Zjednodušeně řečeno, jedná se o zásobník, do něhož se ukládají sady hodnot, pro které je možné zobrazit přehled s výsledky výpočtu (tlačítko Zpráva). Nové scénáře se přidávají tlačítkem Přidat, následným výběrem měněných buněk a sadou hodnot pro daný scénář. 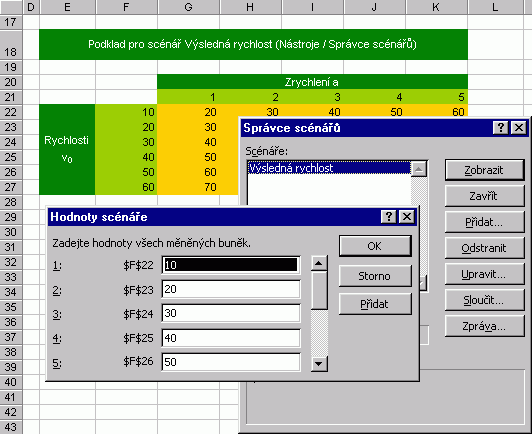
Upřímně řečeno, nespatřuji ani ve funkcích citlivostní analýzy, ani ve Správci scénářů vyjímečné schopnosti. |
Na závěr dnešního povídání něco lehčího. Excel poskytuje nástroj pro hledání "těch správných" proměnných (měněné buňky), které se objevují ve vzorci pro známého řešení (cílová buňka). To je v zásadě opak předchozí úlohy "co by, kdyby". Pomůcka se jmenuje Řešitel, pracuje na bázi numerických metod a vyžaduje instalaci doplňku stejného jména. Řešení může být samozřejmě několik a Excel nabízí jejich ukládání. Nejlépe osvětlí funkci příklad s dialogy:
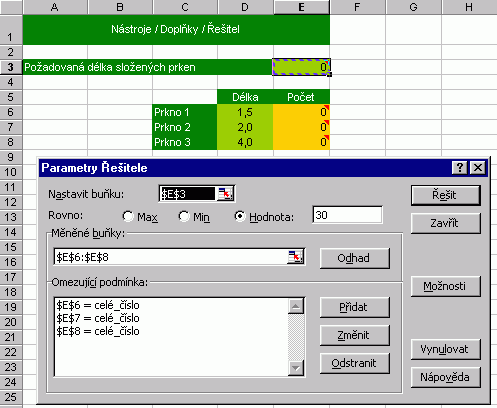
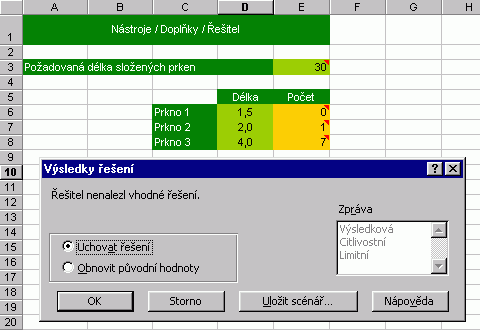
Méně výkonná grafická, ale použitelná je i metoda Nástroje / Hledat řešení. Vyzkoušejte ji. |
Poděkování vzdálené (a někdy i osobní) patří následujícím autorům publikací a článků:
Josef Tvrdík: Opatrně s Excelem při statistických výpočtech, Excel ve výuce statisticky (články naleznete na albert.osu.cz/tvrdik/)