C/C++ & Visual C++
Datové struktury a algoritmy (12.)
Minule jsme si ukázali základní implementaci binárního vyhledávacího stromu. Dnes se k ní vrátíme a ukážeme si rekurzivní implementace metod, které jsme implementovali minule. Také budeme pokračovat metodou Smaz(), která bude mít za úkol mazání prvků binárního stromu. Přeji příjemné čtení!
12.1. Binární strom - jiná implementace metod
Již minule jsme se zmínili o tom, že strom je rekurzivní datovou strukturou. Nyní si ukážeme jak tyto metody naprogramovat, definice třídy stromu je stejná jako v minulém dílu, jen přidáme metody VlozR() a VlozDoStromuR(). Nejprve výkonná metoda:
template<class T> void CBinStrom<T>::VlozDoStromuR(CUzel<T>*
&_lpUzel, const T& _Data)
{
if(!_lpUzel)
{
_lpUzel = new
CUzel<T>(_Data); //
osetrime prazdny strom
}
else
{
if(_Data == _lpUzel->VratData())
{
return;
}
if(_lpUzel->VratData()
> _Data)
{
VlozDoStromuR(_lpUzel->VratLevy(), _Data);
}
else
{
VlozDoStromuR(_lpUzel->VratPravy(), _Data);
}
}
}
Nyní metoda zajišťující vložení do kompletního stromu:
template<class T> void CBinStrom<T>::VlozR(const
T& _Data)
{
VlozDoStromuR(m_lpKoren, _Data);
}
Metoda vyhledávání byla v minulém dílu uvedena v rekurzivní verzi. Ukážeme si tedy pro úplnost její nerekurzivní verzi NajdiVeStromu() (a metodu z minulého dílu přejmenujeme na NajdiVeStromuR() a stejně tak i s metodou Najdi()):
template<class T> CUzel<T>* CBinStrom<T>::NajdiVeStromu(CUzel<T>
*_lpUzel, const T& _Data)
{
CUzel<T> *lpRet = NULL;
while(_lpUzel != NULL)
{
if(_lpUzel->VratData()
== _Data)
{
lpRet = _lpUzel;
break;
}
else
{
if(_lpUzel->VratData() < _Data)
{
_lpUzel = _lpUzel->VratPravy();
}
else
{
_lpUzel = _lpUzel->VratLevy();
}
}
}
return lpRet;
}
Ještě veřejná metoda Najdi():
template<class T> CUzel<T>* CBinStrom<T>::Najdi(const
T& _Data)
{
return NajdiVeStromu(m_lpKoren,
_Data);
}
Metoda pro mazání stromu byla také rekurzivní v minulém dílu. Ta by se na nerekurzivní verzi přepisovala mnohem hůře, s největší pravděpodobností bychom byli nuceni použít nějaké jiné datové struktury pro uložení vrcholů.
Vidíme, že ani jedna z verzí metod není o moc složitější na naprogramování. Ovšem pokud se naskytne rekurzivní i nerekurzivní verze metody, pak je většinou výhodnější použít nerekurzivní verze - nebude docházet ke ztrátě času, která je důsledkem režie při volání funkce (ukládání návratové hodnoty apod.). Výjimku uděláme u metody mazání stromu, kde nám rekurze ušetří programátorskou práci, ačkoliv možná bude o trochu pomalejší.
12.2. Binární strom - mazání prvků
Poslední základní metoda bude provádět operaci mazání prvků binárního vyhledávacího stromu. Z těch metod, se kterými jsme se seznámili je nejsložitější. Musíme si uvědomit, že při mazání prvku mohou nastat následující tři případy:
-
prvek je listem - nemáme žádný problém, stačí prvek smazat a upravit ukazatel v rodičovském prvku
-
prvek má jednoho potomka - stačí změnit ukazatel rodiče mazaného prvku na následovníka tohoto prvku. Předtím si však uložíme ukazatel na mazaný prvek, abychom ho mohli smazat
-
prvek má dva následovníky - budeme muset nějak rozumně mazanou hodnotu nahradit jinou ze stromu. Musíme však brát ohled i na správné uspořádání stromu. Tomu se bude věnovat příslušný odstaveček.
12.2.1. Nalezení rodiče prvku
Abychom nemuseli neustále hledat rodiče mazaného prvku, si nejprve upravíme metodu pro hledání prvku. A to takovým způsobem, že přidáme ještě jeden parametr, ve kterém bude uložen právě tento ukazatel. To pro nás nebude žádný problém, neboť při vyhledávání prvku s danou hodnotou musíme přes rodičovský prvek přejít - stačí přidat jediný řádek, jak vidíme na výpisu. Vzhledem k tomu, že budeme tento ukazatel měnit, budeme ho předávat jako referenci na ukazatel na vrchol (uzel) stromu. Použijeme nerekurzivní verzi hledání prvku:
template<class T> CUzel<T>* CBinStrom<T>::NajdiVeStromu(CUzel<T>
*_lpUzel, const T& _Data,
CUzel<T>* &_lpRodic)
{
CUzel<T> *lpRet = NULL;
while(_lpUzel != NULL)
{
if(_lpUzel->VratData()
== _Data)
{
lpRet = _lpUzel;
break;
}
else
{
_lpRodic = _lpUzel; // ulozime si rodice
if(_lpUzel->VratData() < _Data)
{
_lpUzel = _lpUzel->VratPravy();
}
else
{
_lpUzel = _lpUzel->VratLevy();
}
}
}
return lpRet;
}
Podobně upravíme i funkci pro hledání v celém stromu - implementace je v přiloženém projektu.
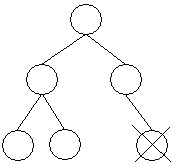
12.2.2. Mazání listového prvku
Grafická interpretace situace:
template<class T> void CBinStrom<T>::SmazList(CUzel<T>*
_lpMazany, CUzel<T>* _lpRodic)
{
if(_lpRodic)
{
// mame-li
rodice
if(_lpMazany
== _lpRodic->VratLevy())
{
_lpRodic->NastavLevy(NULL);
}
else
{
_lpRodic->NastavPravy(NULL);
}
}
else
{
// mazeme
koren stromu
m_lpKoren =
NULL;
}
delete _lpMazany;
// kazdopadne
mazeme mazany prvek
}
Jde tedy jen o to, zjistit, zda je mazaný prvek levým nebo pravým následovníkem a příslušným způsobem upravit ukazatele.
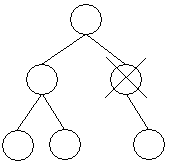
12.2.2. Mazání prvku s jedním následovníkem
Grafická interpretace situace:
template<class T> bool CBinStrom<T>::SmazSJednim(CUzel<T>*
_lpMazany, CUzel<T>* _lpRodic)
{
// nejprve si uchovame potomka
mazaneho prvku - je jen jeden
CUzel<T>* lpPotomek = (_lpMazany->VratLevy() == NULL) ? _lpMazany->VratPravy() :
_lpMazany->VratLevy();
// pokud neexistuje predchudce -
budeme mazat koren
if(!_lpRodic) { m_lpKoren = lpPotomek;
}
else
{
// jinak preskocime mazany ve strukture stromu
if(_lpMazany
== _lpRodic->VratLevy())
{
_lpRodic->NastavLevy(lpPotomek);
}
else
{
_lpRodic->NastavPravy(lpPotomek);
}
}
delete _lpMazany;
// kazdopadne
mazeme mazany prvek
}
Mažeme velice podobně, jako v případě listu. Jen je nutné najít následovníka mazaného prvku a toho zařadit správně pod rodiče.
12.2.3. Mazání prvku se dvěma následovníky
Poslední a nejsložitější metoda je před námi. Grafická interpretace situace:
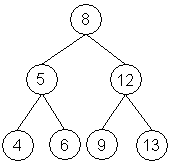
Rozhodneme-li se smazat např. prvek s hodnotou 12, musíme vybrat prvek, kterým 12 nahradíme, aby zůstala zachována struktura binárního vyhledávacího stromu. V tomto případě by to mohl být jeden z prvků 9 nebo 13. Pokusíme se tedy vyjmout prvek 8, pak už nemůžeme vybírat libovolně. Určitě by nevyhovoval prvek s číslem 13 a prvek s číslem 4. Naopak prvky 6 i 9 vyhovují uspořádání stromu. Pokud si na papír nakreslíte rozsáhlejší strom, dojdete k závěru, že lze vždy použít prvek, který leží buď v levé větvi nejvíce vpravo nebo prvek v pravé větvi co nejvíce vlevo. Takže jedna z možných implementací vypadá následovně:
template<class T> void CBinStrom<T>::SmazSeDvema(CUzel<T>*
_lpMazany)
{
// uchovame si prvek, kterym
nahradime nahrazovany prvek - vezmeme nejlevejsi zprava
CUzel<T>* lpNahrazujici = _lpMazany->VratPravy();
// soucasne si najdeme i rodice
tohoto prvku
CUzel<T>* lpRodic = _lpMazany;
while(lpNahrazujici->VratLevy())
{
lpRodic =
lpNahrazujici;
lpNahrazujici
= lpNahrazujici->VratLevy();
}
// nyni mame vse potrebne ->
prohodime data
_lpMazany->NastavData(lpNahrazujici->VratData());
// a smazeme nepotrebny prvek
if(lpNahrazujici->VratLevy() ||
lpNahrazujici->VratPravy())
{
SmazSJednim(lpNahrazujici,
lpRodic);
}
else
{
SmazList(lpNahrazujici,
lpRodic);
}
}
Funkce má jen jeden parametr, neboť rodiče mazaného prvku v tomto případě vůbec nepotřebujeme. V těle jen najdeme pomocí cyklu while nejlevější prvek v pravém podstromu našeho originálního stromu a zároveň i jeho rodiče. Prvek, který mažeme bude buď listovým prvkem nebo prvkem s jedním následovníkem a pro tyto případy již máme připraveny příslušné metody.
12.2.4. Metoda pro mazání prvku binárního vyhledávacího stromu
Zbývá nám už jen doplnit metodu, které zadáme jako parametr požadovanou hodnotu, kterou chceme mazat:
template<class T> bool CBinStrom<T>::Smaz(const T&
_Data)
{
bool bNavrat = false;
CUzel<T>* lpMazany = NULL, *lpRodic =
NULL;
lpMazany = Najdi(_Data, lpRodic);
if(lpMazany)
{
if((lpMazany->VratLevy()
== NULL) && (lpMazany->VratPravy() == NULL))
{
SmazList(lpMazany, lpRodic);
}
else
{
if((lpMazany->VratLevy() == NULL) || (lpMazany->VratPravy() == NULL))
{
SmazSJednim(lpMazany, lpRodic);
}
else
{
SmazSeDvema(lpMazany);
}
}
bNavrat =
true;
}
return bNavrat;
}
Metoda pouze vyhledá příslušné ukazatele - na prvek a jeho rodiče. Pak se jen rozhodne, kterou ze tří metod pro mazání prvku zavolá.
12.3. Co bude příště
Příště budeme pokračovat povídáním o stromech a s
největší pravděpodobností již opustíme binární vyhledávací strom. Budeme
se věnovat procházení stromem do hloubky, o kterém jsme se zmínili již v
minulém dílu. Dále zavedeme některé vlastnosti stromů. A nakonec si
povíme o problémech, které mohou vzniknout při vkládání prvků do stromu.
Nashledanou příště.