C/C++ & Visual C++
Datové struktury a algoritmy (13.)
Úvodem | Datové struktury | Kurz DirectX | Downloads | Otázky a odpovědi
Již v úvodním dílu o stromech jsme se zmínili o průchodu uzly stromu a to jak binárního, tak i obecného. V dnešním pokračování se budeme touto problematikou zabývat podrobněji a to jak s pomocí rekurzivního charakteru datové struktury stromu, tak i s využitím dříve implementovaných struktur - zásobníku a fronty.
13.1. Průchod stromem do hloubky - rekurzivně
Průchodem stromu rozumíme postupné projití všech uzlů stromu a provedení určité operace nad datovými prvky jednotlivých uzlů - může to být buď jednoduše vypsání, ale může to být i změna všech uzlů pomocí nějaké funkce. My si ukážeme všechny metody v první verzi (tedy výpis prvků stromu) a pak si řekneme, jak se dá napsat funkce průchodu stromem pro obecně definovanou funkci. Zabývat se budeme pro jednoduchost binárním vyhledávacím stromem, ale metody by se velice podobně implementovaly i pro obecné stromy. Podle toho, v jaké fázi funkce průchodu stromem budeme zpracovávat datový člen uzlů se rozlišují tři verze průchodu, které si nyní implementujeme:
template<class T> void CBinStrom<T>::PruchodPre(CUzel<T>*
_lpUzel)
{
if(_lpUzel)
{
cout << _lpUzel->VratData()
<< " ";
PruchodPre(_lpUzel->VratLevy());
PruchodPre(_lpUzel->VratPravy());
}
}
Ještě obslužná funkce pro průchod celým stromem:
template<class T> void CBinStrom<T>::PruchodStromem1()
{
PruchodPre(m_lpKoren);
}
Metoda je založena na rekurzi, vstoupíme do prvního uzlu zpracujeme první člen. Poté rekurzivně vstoupíme do levého podstromu, opět zpracujeme uzel. To pokračuje tak dlouho, dokud existují další levé podstromy. Dostaneme se tedy do nejlevějšího listu, z něj se pak funkce vrací o patro výš a zpracuje pravý podstrom. Může se tedy stát, že každý uzel stromu navštívíme třikrát - při sestupu (vykonání operace), při návratu z levého podstromu a konečně při návratu z pravého podstromu. Tento způsob průchodu stromu se nazývá preorder - akci vykonáváme totiž při prvním vstupu do uzlu. Ukážeme si výstup pro konkrétní strom. Strom bude vytvořen následujícím kódem:
CBinStrom<int> *lpStrom = new
CBinStrom<int>;
lpStrom->Vloz(8);
lpStrom->Vloz(5);
lpStrom->Vloz(9);
lpStrom->Vloz(13);
lpStrom->Vloz(4);
lpStrom->Vloz(7);
lpStrom->Vloz(11);
Takže v grafické interpretaci bude strom vypadat následovně:
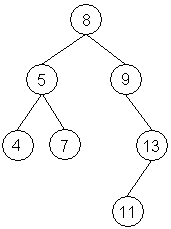
Po zavolání metody pro preorder průchod dostaneme posloupnost: 8 5 4 7 9 13 11.
To, že jsme provedli operaci nad datovým prvkem při vstupu do uzlu není jediná možnost. Ukážeme si tedy zbývající dvě metody a také posloupnosti, které nám dají:
template<class T> void CBinStrom<T>::PruchodIn(CUzel<T>*
_lpUzel)
{
if(_lpUzel)
{
PruchodIn(_lpUzel->VratLevy());
cout << _lpUzel->VratData()
<< " ";
PruchodIn(_lpUzel->VratPravy());
}
}
template<class T> void CBinStrom<T>::PruchodStromem2()
{
PruchodIn(m_lpKoren);
}
Tato metoda tedy provádí akci při druhém vstupu do uzlu a nazývá se inorder. Výsledná posloupnost má pak tvar: 4 5 7 8 9 11 13.
Třetí metoda provádí operaci nad uzlem až v posledním vstupu a proto nese název postorder. Její kód naleznete v přiložených zdrojových souborech. Výsledná posloupnost má tvar: 4 7 5 11 13 9 8.
Všechny tyto tři metody se dají např. použít k reprezentaci matematických výrazů v paměti počítače, o čemž si povíme v některém z dalších dílu.
Nyní se podíváme na to, jak napsat metodu průchodu stromem tak, aby se s každým datovým prvkem provedla nějaká námi definovaná operace - např. se pokusíme hodnoty všech datových prvků vynásobit dvěma:
template<class T> void CBinStrom<T>::PruchodPre(CUzel<T>*
_lpUzel,
void (*operace)(CUzel<T> *_lpParam))
{
if(_lpUzel)
{
operace(_lpUzel);
PruchodPre(_lpUzel->VratLevy(),
operace);
PruchodPre(_lpUzel->VratPravy(),
operace);
}
}
template<class T> void CBinStrom<T>::PruchodStromem1(void
(*operace)(CUzel<T> *_lpParam))
{
PruchodPre(m_lpKoren, operace);
}
Nyní už si jen v hlavním programu definujeme funkci pro vynásobení datového členu dvěmi následujícím způsobem:
void VynasobDvema(CUzel<int> *_lpUzel)
{
_lpUzel->NastavData(_lpUzel->VratData()
* 2);
}
Poté už ji jen použijeme ve funkci main() takto:
lpStrom->PruchodStromem1(VynasobDvema);
Zbývající dvě metody se opět liší jen pořadím provedení operace a jsou obsaženy v implementaci projektu.
Kód naleznete v sekci Downloads (projekt Strom).
13.2. Průchod stromem do hloubky - nerekurzivně
Nyní se podíváme na to, jak napsat tyto funkce bez použití rekurzivního volání. Pokud bychom uzly stromu implementovali tak, že by obsahovaly i odkaz na své rodiče, pak by bylo možné napsat funkci pro průchod pomocí několika cyklů. To ovšem není náš případ a proto se podíváme na jinou možnost - využijeme námi dříve stvořené třídy pro zásobník a příště i pro frontu. My jsme si tyto dvě třídy implementovali jako statické a o dynamických jsme si jen pověděli, jak je naprogramovat. V tomto případě se nám budou hodit dynamické implementace, neboť předem nevíme kolik prvků (vnitřních uzlů) strom má. Takže nyní malá odbočka a ukážeme si jednoduchou implementaci jedné z těchto tříd (CDynZasob):
#ifndef CDYNZASOB_H
#define CDYNZASOB_H
template<class T> class CPrvek {
private:
T m_Data;
CPrvek<T> *m_lpDalsi;
public:
CPrvek() : m_lpDalsi(NULL) { }
CPrvek(const T& _Data) :
m_Data(_Data), m_lpDalsi(NULL) { }
T VratData() const { return m_Data; }
CPrvek<T>* VratDalsi() const { return
m_lpDalsi; }
void NastavDalsi(CPrvek<T> *_lpDalsi)
{ m_lpDalsi = _lpDalsi; }
void NastavData(const T& _Data) {
m_Data = _Data; }
};
template<class T> class CDynZasob {
private:
CPrvek<T> *m_lpVrchol;
public:
CDynZasob() : m_lpVrchol(NULL) { }
~CDynZasob() { if(!JePrazdny()) {
SmazZasob(); } }
void VytvorPrazdny();
bool SmazZasob();
bool JePrazdny() { return (m_lpVrchol
== NULL); }
bool Vloz(const T& _Data);
// vklada
na zacatek
bool Vyjmi(T &_Vyber);
// odebere prvni prvek
};
template<class T> void CDynZasob<T>::VytvorPrazdny()
{
if(m_lpVrchol)
{
SmazZasob();
}
m_lpVrchol = NULL;
}
template<class T> bool CDynZasob<T>::SmazZasob()
{
bool bNavrat = false;
if(!JePrazdny())
{
CPrvek<T> *lpMazany;
while(m_lpVrchol)
{
lpMazany = m_lpVrchol;
m_lpVrchol = m_lpVrchol->VratDalsi();
// posun na dalsi prvek
delete lpMazany;
}
bNavrat =
true;
}
return bNavrat;
}
template<class T> bool CDynZasob<T>::Vloz(const T& _Data)
{
bool bNavrat = false;
// jen vlozime prvek do zasobniku
CPrvek<T> *lpNovy = new CPrvek<T>(_Data);
if(lpNovy)
{
lpNovy->NastavDalsi(m_lpVrchol);
// novy prvek bude ukazovat na puvodni zacatek
m_lpVrchol =
lpNovy; // a presuneme novy zacatek
bNavrat =
true;
}
// opet novy prvek nemazeme
return bNavrat;
}
template<class T> bool CDynZasob<T>::Vyjmi(T &_Vyber)
{
bool bNavrat = false;
if(!JePrazdny())
{
_Vyber = m_lpVrchol->VratData();
CPrvek<T> *lpMazany
= m_lpVrchol;
m_lpVrchol =
m_lpVrchol->VratDalsi();
delete
lpMazany;
bNavrat =
true;
}
return bNavrat;
}
#endif
Kód není třeba probírat, je to jen použití lineárního spojového seznamu. My tento zásobník použijeme pro uchování uzlů našeho binárního stromu v metodě PruchodStromem4():
template<class T> void CBinStrom<T>::PruchodStromem4()
{
// musime
si pomoci, abychom mohli pouzit sablonu jako parametr sablony
typedef CUzel<T> LPTCUZEL;
CDynZasob<LPTCUZEL> Zasob;
Zasob.Vloz(*m_lpKoren);
CUzel<T> Zpracovani;
cout << endl << "Nerekurzivne! :" <<
endl;
while(!Zasob.JePrazdny())
{
if(Zasob.Vyjmi(Zpracovani))
{
cout << " " << Zpracovani.VratData();
if(Zpracovani.VratPravy()) { Zasob.Vloz(*Zpracovani.VratPravy()); }
if(Zpracovani.VratLevy()) { Zasob.Vloz(*Zpracovani.VratLevy()); }
}
}
}
Jednoduše vyjdeme z kořene, který uložíme do zásobníku jako první, vstoupíme do cyklu, který skončí až v okamžiku, kdy bude zásobník prázdný. V cyklu nejprve vyjmeme vrchol ze zásobníku (při prvním průchodu cyklem to je kořen), zpracujeme data obsažená v tomto uzlu a uložíme na zásobník následníky tohoto uzlu. Ukládáme je v pořadí pravý a pak levý, tím docílíme toho, že strom bude procházen zleva doprava. Do levého se totiž díky charakteru zásobníku dostaneme dříve. Pokud nám však nezáleží na pořadí navštívení jednotlivých vrcholů, můžeme řádky klidně prohodit.
Ještě dodám ke kódu, že definici jiného jména pro šablonu CUzel<T> by bylo lepší umístit vně třídy. Zde je to jen proto, aby byla vidět definice. Samozřejmě by bylo možné metodu upravit tak, aby umožňovala provedení nějaké operace nad daty obsaženými v uzlu jako jsme to udělali u rekurzivních metod.
Kód naleznete v sekci Downloads (projekt Strom2).
13.4. Co bude příště
Příště si povíme ještě o průchodu stromem do šířky a také budeme řešit velice známou úlohu o koni na šachovnici, která nám ukáže využití metody průchodu stromem. Nadefinujeme si některé vlastnosti stromů a podíváme se na datovou strukturu příbuznou stromům, která se nazývá halda.