C/C++ & Visual C++
Datové struktury a algoritmy (11.)
Úvodem | Datové struktury | Kurz DirectX | Downloads | Otázky a odpovědi
11.1 Pojmy a základy
Stromy jsou, podobně jako lineární spojové seznamy, složeny z uzlů (angl. nodes). Tyto uzly jednak obsahují data a pak obsahují také ukazatele na další uzly. Tím nám vzniká rekurzivní datová struktura. Ukážeme si grafickou interpretaci obecného stromu:
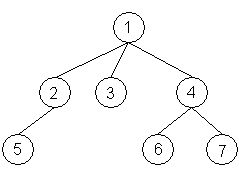
Pokud si obrázek obrátíte, pak uvidíte proč tuto datovou strukturu nazýváme stromem. Uvedeme si některé pojmy, které se vyskytují ve spojitosti se stromy:
-
kořen (angl. root) - je počátečním uzlem stromu a je vždy jen jeden. Lze také definovat jako uzel, který nemá rodiče. V našem obrázku to je tedy uzel označený 1
-
potomek (angl. child) - pokud k některému uzlu vede čára z uzlu nad ním (ten je na nižší hladině, jak se povíme níže), pak je tento prvek potomkem prvku z kterého vede čára. Například uzly 2, 3, 4 jsou potomky uzlu (kořenu) 1
-
rodič (angl. parent) - uvedeme příklad - rodičem prvku 3 je uzel 1
-
list (ang. leaf) - uzel, který nemá potomka nazýváme listem. V našem diagramu jsou to uzly 5, 3, 6 a 7
-
větev (branch) - spojnice dvou uzlů
Prvky, které nejsou listy se také někdy označují jako vnitřní uzly stromu a listy se někdy označují jako koncové uzly.
Typ stromu je pak určen tím, kolik potomků mají jednotlivé uzly. Označme n počet potomků uzlu, pak pro:
-
n = 2 - binární strom
-
n = 3 - ternární strom
-
n = 4 - quadtree
Pokud položíme n = 1, vidíme, že datovou strukturou, kterou dostaneme je jednosměrný lineární spojový seznam.
Další důležitou věcí, kterou vidíme v diagramu je, že každý uzel stromu vlastně tvoří nový strom - říkáme mu podstrom. Stačí vzít uzel 4 a dostáváme strom s kořenem 4 a jeho dvěma potomky - uzly 6 a 7.
Pokud bychom chtěli, a v naší implementaci se nám to hodilo, pak je možné do každého uzlu navíc uložit i ukazatel na rodiče tohoto uzlu, což by v některých případech ulehčilo průchod stromem.
Spojový seznam byla vlastně čára, na které byly uloženy jednotlivé uzly - ostatně proto jsme mu také říkali lineární. Narozdíl od toho, u stromů zavádíme hladiny. Více nám o tom poví obrázek:
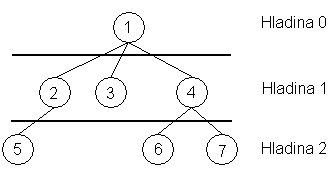
Na 0-té hladině leží pouze kořen a všichni jeho potomci mají hladinu o jedna vyšší. Jako počáteční hladinu jsme si zvolili 0, neboť pole nám v našem oblíbeném C/C++ začínají také od nuly.
11.2 Obecné stromy
To jsou stromy, jejichž uzly ukazují na nekonečný počet dalších uzlů. Až si prohlédnete obrázek, uvidíte, že se v životě používají celkem často:
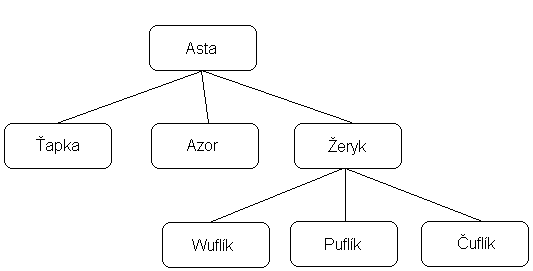
Jak takovýto strom, hlavně s ohledem na nekonečný počet potomků jednotlivých uzlů realizovat? Jednoduše, stačí si na pomoc vzít spojový seznam a do každého uzlu stromu umístit jen odkaz na prvního potomka uzlu. Samozřejmě to není jediná možnost, lze použít i dynamicky se zvětšující pole nebo jinou strukturu. Uzly tedy budou v tomto případě obsahovat dva ukazatele - ukazatel na prvního potomka a na uzly na stejné hladině (dalo by se říci na sourozence). To ovšem kromě kořene, který bude mít ukazatel na sourozence s hodnotou NULL.
V reálném problému se nám může takovýto obecný strom hodit třeba k rozhodování umělé inteligence počítačové hry. V uzlu by byla například otázka, zda postava vidí útočníka, možnosti by byly ano/ne. Výhodou pak je, že vybráním např. možnosti ano vyloučíme všechny otázky následující v podstromě ne, čímž se vyhneme zkoumání mnoha neperspektivních otázek a tedy i úspoře času.
Zpracovávat stromy rekurzivně můžeme celkem třemi způsoby. Zpracováním rozumíme provedení určité operace nade všemi uzly stromu. U obecných stromů se používají dvě metody, které nám zajistí průchod všemi uzly stromu - jsou to pre-order a post-order (třetí metoda se nazývá in-order). O funkci všech těchto tří metod se zmíníme později.
11.3 Binární stromy a binární vyhledávací strom
My se nyní budeme zabývat a také implementujeme strom, který se používá velice často. Je to případ stromu pro n = 2, tedy každý uzel stromu bude ukazovat na dva další uzly - označme si je třeba levý a pravý. Datovým prvkem který budeme vkládat do stromu pak bude často hodnota typu int. Pro vkládání prvku si zavedeme pravidlo, že pokud je prvek menší nežli hodnota v uzlu, pak prvek uložíme do levé větve uzlu. V opačném případě do pravé. Pokud prvek bude ve stromě již obsažen, nestane se nic. Strom, který splňuje tyto speciální podmínky nazýváme právě binární vyhledávací strom a slouží k rychlému zjištění, zda je hodnota ve stromě uložena či ne. Jiné užité pro binární stromy je pak reprezentace aritmetického výrazu v paměti počítače, popř. k implementaci datové struktury nazvané halda, se kterou se setkáme v některém z dalších dílů. Někdy lidé označují binární stromy jako B-stromy, což ale není správné. B-strom je úplně jiná datová struktura, která nachází uplatnění třeba v souborovém systému.
Implementujeme si tedy takový binární strom:
#ifndef BINSTROM_H
#define BINSTROM_H
template<class T> class CUzel {
private:
T m_Data;
CUzel<T> *m_lpLevy;
CUzel<T> *m_lpPravy;
public:
CUzel() : m_lpLevy(NULL), m_lpPravy(NULL)
{ }
CUzel(const T& _Data) :
m_Data(_Data), m_lpLevy(NULL), m_lpPravy(NULL) { }
T VratData() const { return m_Data; }
CUzel<T>* &VratLevy() { return m_lpLevy;
}
CUzel<T>* &VratPravy() { return m_lpPravy;
}
void NastavLevy(CUzel<T> *_lpLevy) {
m_lpLevy = _lpLevy; }
void NastavPravy(CUzel<T> *_lpPravy)
{ m_lpPravy = _lpPravy; }
void NastavData(const T& _Data) {
m_Data = _Data; }
};
template<class T> class CBinStrom {
private:
CUzel<T> *m_lpKoren;
public:
CBinStrom() : m_lpKoren(NULL) { }
~CBinStrom() { if(!JePrazdny()) {
SmazStrom(m_lpKoren); } }
bool VytvorPrazdny();
bool SmazStrom(CUzel<T>* &_lpUzel);
bool JePrazdny();
bool Vloz(const T& _Data);
// vklada
do stromu
bool VlozDoStromu(CUzel<T>* &_lpUzel,
const T& _Data);
CUzel<T>* Najdi(const T& _Data);
// vrati ukazatel na nalezeny prvek nebo NULL
CUzel<T>* NajdiVeStromu(CUzel<T> *_lpUzel,
const T& _Data);
bool Smaz(const T& _Data);
// smaze
data
};
A nyní k jednotlivým metodám. Jako první vezmeme metodu pro zjištění, zda je strom prázdný, což nastane jen je-li ukazatel na kořen NULL:
template<class T> bool CBinStrom<T>::JePrazdny()
{
return (m_lpKoren == NULL);
}
Nyní metody pro novou inicializaci stromu a tedy i smazání stromu:
template<class T> bool CBinStrom<T>::VytvorPrazdny()
{
bool
bNavrat = false;
if(!JePrazdny())
{
bNavrat = SmazStrom(m_lpKoren);
// smazeme puvodni strom
}
// nova inicializace promennych se
provede jiz v metode SmazStrom()
return bNavrat;
}
template<class T> bool CBinStrom<T>::SmazStrom(CUzel<T>*
&_lpUzel) // budeme menit
ukazatel
{
bool
bNavrat = false;
if(_lpUzel)
{
SmazStrom(_lpUzel->VratLevy());
SmazStrom(_lpUzel->VratPravy());
cout << "Mazu " << (_lpUzel)->VratData() << endl;
delete (_lpUzel);
_lpUzel = NULL;
bNavrat = true;
}
return
bNavrat;
}
Vidíme, že mazání stromu je rekurzivní záležitost. Prostě smažeme levou podvětev, pravou podvětev a nakonec vlastní uzel. Pro jistotu nastavíme uzlu hodnotu NULL. Proto nestačí předávat jako parametr ukazatel - nemohli bychom ho totiž v těle funkce měnit.
Nyní se podíváme na vkládání prvku do stromu, které musí probíhat podle našich pravidel - prvky menší nežli prvek v uzlu jdou do levého podstromu, prvky větší do pravého. Prvky nejsou v seznamu obsaženy vícekrát než jednou. Metody budou dvě, jedna která vykoná veškerou práci. Ta umístí prvek na správné místo ve stromě pod prvkem, který ji předáme jako parametr. Druhá funkce pak už jen zajistí vložení prvku do celého stromu:
template<class T> bool CBinStrom<T>::VlozDoStromu(CUzel<T>* &_lpUzel,
const T& _Data)
{
bool bNavrat =
false;
// budeme
hledat spravne misto pro umisteni uzlu a ukladat si posledni nadrazeny prvek
CUzel<T> *lpRodic
= NULL, *lpNovy = _lpUzel;
while(lpNovy
!= NULL)
{
if(lpNovy->VratData() == _Data) { return true; }
// nalezneme-li prvek, pak koncime
else
{
if(lpNovy->VratData() > _Data)
{
lpRodic = lpNovy;
lpNovy = lpNovy->VratLevy();
}
else
{
lpRodic = lpNovy;
lpNovy = lpNovy->VratPravy();
}
}
}
// nyni mame
misto pro novy prvek a tak ho vytvorime
lpNovy = new
CUzel<T>(_Data);
if(lpNovy)
{
if(lpRodic == NULL)
{
_lpUzel = lpNovy; // znaci, ze neexistoval prvni uzel
bNavrat = true;
}
else
{
if(lpRodic->VratData() > _Data)
{
lpRodic->NastavLevy(lpNovy); // zapojime doleva
}
else
{
lpRodic->NastavPravy(lpNovy); // zapojime doprava
}
bNavrat = true;
}
}
return bNavrat;
}
template<class T> bool CBinStrom<T>::Vloz(const
T& _Data)
{
return
VlozDoStromu(m_lpKoren, _Data);
}
V těle funkce opět měníme ukazatel předaný jako argument, takže používáme opět referenci na ukazatel. Tato funkce jde samozřejmě, vzhledem k vlastnostem stromů, napsat také rekurzivně. K tomu se dostaneme ještě v příštím dílu.
A nyní metoda pro nalezení hodnoty v tomto vyhledávacím stromě:
template<class T> CUzel<T>* CBinStrom<T>::NajdiVeStromu(CUzel<T> *_lpUzel,
const T& _Data)
{
CUzel<T> *lpRet = NULL;
if(_lpUzel)
{
if(_lpUzel->VratData()
== _Data)
{
return _lpUzel;
}
else
{
if(_lpUzel->VratData() < _Data)
{
lpRet = NajdiVeStromu(_lpUzel->VratPravy(), _Data);
}
else
{
lpRet = NajdiVeStromu(_lpUzel->VratLevy(), _Data);
}
}
}
return lpRet;
}
template<class T> CUzel<T>* CBinStrom<T>::Najdi(const T&
_Data)
{
return NajdiVeStromu(m_lpKoren,
_Data);
}
#endif
Kód naleznete v sekci Downloads (projekt Strom).
11.4 Co bude příště
Tak dnes jsme si ukázali základní implementaci stromu a příště si ukážeme některé nevýhody této implementace. Povíme si o některých vlastnostech stromů jako je vyváženost a úplnost stromu. Také jsme nakousli procházení všemi uzly stromu, ke kterému se příště vrátíme a ukážeme si jak strom procházet do hloubky. U dalšího dílu nashledanou.