V posledním dílu jsme ukončili povídání o datových strukturách, které byly implementovány přes pole, což nás v některých ohledech omezovalo. Dnes se začneme věnovat datové struktuře seznamu, která je založena na dynamické alokaci paměti.
Sice už jsme se seznamem pracovali, ale neuvedli jsme si jeho charakteristické vlastnosti:
pevně stanovené pořadí
možnost opakování stejných prvků
možnost ukládat, vyjímat a samozřejmě vyhledávat údaje
Náš seznam (ať už pole, fronta nebo zásobník) implementovaný pomocí polí byl statický, museli jsme tedy už přímo v programu určit kolik bude mít maximálně prvků. Toto omezení odstraníme využitím spojového seznamu, jehož jednotlivé prvky jsou vytvářeny přímo za běhu programu. Protože alokace paměti probíhá přímo za běhu programu, má jisté nevýhody. Za prvé je paměťově náročnější, protože každý prvek musí obsahovat ukazatel na další prvek (následovníka, popř. i předchůdce) a funkce pro alokaci paměti nepatří k funkcím, které by byly zrovna málo časově nenáročné. Druhou nevýhodou pak je, že na k-tý prvek se můžeme dostat pouze průchodem přes prvky ležící před ním (nebo za ním, pokud je obousměrný) nelze použít výhod indexování jako u polí. Poslední pak je, že je trochu náročnější pro implementaci.
My se nyní budeme věnovat lineárnímu spojovému seznamu a to konkrétně jednosměrnému - každý prvek bude obsahovat ukazatel pouze na svého následovníka.
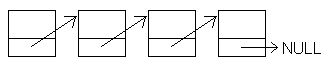
Je to tedy posloupnost objektů (struktur, tříd) stejného typu, které jsou seřazeny do řady. Jeho funkce je podobná funkci jednorozměrného pole, ovšem již s výše uvedenou nevýhodou: nejde indexovat, procházíme tedy vždy od začátku. Grafická reprezentace této datové struktury:
Malá spodní část prvku zobrazuje datový prvek obsažený ve struktuře, který odkazuje na následující prvek. Velká část pak zobrazuje data. Seznam je ukončen prvkem, ve kterém jsou platná data, ale ukazatel na další prvek má hodnotu NULL. Druhou možností je zarážka, se kterou se setkáme my. Zarážka neobsahuje data vkládaná uživatelem, uvidíme jak se ale dá využít pro ulehčení některých operací:
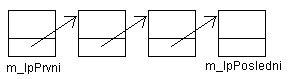
Implementovat budeme dvě třídy a to třídu CJednPrvek, která bude, jak už název říká, prvkem jednosměrného lineárního spojového seznamu. Druhou třídou bude CLinSpojSeznam, obsahující jako členskou proměnnou typu CJednPrvek určující začátek seznamu. Protože do seznamu budeme jistě přidávat prvky, tak se nám bude hodit i proměnná ukazující na jeho konec. Pokud by tam nebyla, tak bychom při každém vložení prvku na konec seznamu museli projít celý seznam (tedy všech N právě uložených prvků):
#ifndef LINSPOJSEZNAM_H
#define LINSPOJSEZNAM_H
template<class T> class CJednPrvek {
private:
T m_Data;
CJednPrvek<T> *m_lpDalsi;
public:
CJednPrvek() : m_lpDalsi(NULL) { }
CJednPrvek(const T& _Data) : m_Data(_Data), m_lpDalsi(NULL) { }
T VratData() const { return m_Data; }
CJednPrvek<T>* VratDalsi() const { return m_lpDalsi; }
void NastavDalsi(CJednPrvek<T> *_lpDalsi) { m_lpDalsi = _lpDalsi; }
void NastavData(const T& _Data) { m_Data = _Data; }
};
template<class T> class CLinSpojSeznam {
private:
CJednPrvek<T> *m_lpPrvni, *m_lpPosledni;
public:
CLinSpojSeznam() : m_lpPrvni(NULL), m_lpPosledni(NULL) { }
~CLinSpojSeznam() { if(!JePrazdny()) { SmazSeznam(); } }
bool VytvorPrazdny();
bool SmazSeznam();
bool JePrazdny() { return (m_lpPrvni == m_lpPosledni); }
bool VlozNaKonec(const T& _Data);
// vklada na konec seznamu
void Vypis();
};
Třída CJednPrvek je jasná, zapouzdřuje pouze náš datový prvek a ukazatel na další objekt CJednPrvek. Třída CLinSpojSeznam pak pro začátek obsahuje metody pro základní práci se seznamem, složitější metody budeme přidávat postupně:
template<class T> bool CLinSpojSeznam<T>::VytvorPrazdny()
{
bool bNavrat = false;
m_lpPrvni = new CJednPrvek<T>; // konstruktor automaticky nastavi m_lpDalsi na NULL,
jinak bychom to museli udelat my
if(m_lpPrvni)
{
m_lpPosledni = m_lpPrvni; // zacatek je i koncem
bNavrat = true;
}
return bNavrat;
}
K tomuto kousku kódu je nutné dodat, že ačkoliv vytváříme prázdný seznam, obsahuje tento hned jeden prvek. Tento speciální prvek budeme nazývat zarážkou a s výhodou ji využijeme při procházení pole za účelem nalezení prvku s určitou hodnotou. Na tento prvek bude vždy ukazovat členská proměnná třídy CLinSpojSeznam::m_lpPosledni. Protože prázdný seznam je celkem k ničemu, ukážeme si jak uložit prvek na konec seznamu:
template<class T> bool CLinSpojSeznam<T>::VlozNaKonec(const
T& _Data)
{
bool bNavrat = false;
if(m_lpPosledni) // pokud existuje zarazka
{
// vytvorime novy konec (prazdny prvek)- musime dynamicky
CJednPrvek<T> *lpNovy= new CJednPrvek<T>;
// ulozime data do posledniho prvku -
zarazky
m_lpPosledni->NastavData(_Data);
m_lpPosledni->NastavDalsi(lpNovy);
m_lpPosledni = lpNovy; // poslednim prvkem je nove vytvorena zarazka
bNavrat = true;
// pozor prvek novy zde nesmime uvolnit !!!
}
return bNavrat;
}
Zde využijeme toho, že poslední prvek je zarážka, která neobsahuje pro nás zajímavá data. Uložíme tedy data předaná jako parametr do této zarážky a vytvoříme nový prázdný prvek - novou zarážku. Alokaci provedeme dynamicky, protože staticky alokovaný prvek by zanikl po zavolání příkazu return. Poté nastavíme ukazatel v původní zarážce tak, aby ukazoval na nově vytvořenou zarážku a konečně posuneme ukazatel na zarážku na nový konec. Toto vše provedeme jen za předpokladu, že existuje zarážka, tedy seznam byl korektně vytvořen. Nyní si ukážeme funkci pro výpis seznamu:
template<class T> void CLinSpojSeznam<T>::Vypis()
{
cout << "Stav seznamu: ";
if(!JePrazdny())
{
CJednPrvek<T> *lpVypisovany= m_lpPrvni;
while(lpVypisovany!= m_lpPosledni) // data zarazky pro nas nejsou dulezita
{
cout << lpVypisovany->VratData() << " ";
lpVypisovany= lpVypisovany->VratDalsi();
}
}
else
{
cout << " PRAZDNY";
}
cout << endl;
}
Pokud seznam není prázdný (tedy ukazatele m_lpPrvni a m_lpPosledni jsou různé), využijeme cyklu while a pomocné proměnné vypisovany k vypsání obsahu všech prvků, samozřejmě kromě zarážky. A protože jsme alokovali dynamicky paměť, musíme sezname korektně zrušit:
template<class T> bool CLinSpojSeznam<T>::SmazSeznam()
{
bool bNavrat = false;
if(!JePrazdny())
{
CJednPrvek<T> *lpMazany;
while(m_lpPrvni)
{
lpMazany= m_lpPrvni;
m_lpPrvni = m_lpPrvni->VratDalsi();
// posun na dalsi prvek
delete lpMazany;
}
bNavrat = true;
}
return bNavrat;
}
Seznam uvolníme průchodem od začátku
postupným odmazáváním prvků v pořadí, ve kterém byly uloženy do seznamu. Tím
máme naši základní kostru, kterou budeme dále rozšiřovat o užitečné funkce. Nejprve
vyhledávání prvku:
template<class T> CJednPrvek<T>* CLinSpojSeznam<T>::Najdi(const
T& _Data)
{
CJednPrvek<T> *lpNavrat = NULL; // implicitne nenalezeno
if(!JePrazdny())
{
CJednPrvek<T> *lpZkoumany= m_lpPrvni;
m_lpPosledni->NastavData(_Data); // ulozime data do zarazky
while(lpZkoumany->VratData() != _Data)
{
lpZkoumany= lpZkoumany->VratDalsi();
}
if(lpZkoumany!= m_lpPosledni)
{
lpNavrat =
lpZkoumany; // nalezli jsme prvek
}
}
return lpNavrat;
}
Zde jsme s výhodou využili zarážky, do které uložíme hledanou hodnotu. Potom máme jistotu, že tuto hodnotu nalezneme vždy a nemusíme se zabývat tím, jestli jsme dosáhli konce seznamu. Ukážeme si, jak by vypadala metoda přepsaná pro ověřování konce pole:
template<class T> CJednPrvek<T>* CLinSpojSeznam<T>::NajdiBezZarazky(const
T& _Data)
{
CJednPrvek<T> *lpNavrat = NULL; // implicitne nenalezeno
if(!JePrazdny())
{
CJednPrvek<T> *lpZkoumany= m_lpPrvni;
while(lpZkoumany!= m_lpPosledni )
{
if(_Data == lpZkoumany->VratData())
{
lpNavrat = lpZkoumany;
break; //
preruseni cyklu
}
lpZkoumany= lpZkoumany->VratDalsi();
// posun na dalsi prvek
}
}
return lpNavrat;
}
Vidíme, že zarážka je velice užitečná věc. Ušetříme si totiž nejen problémy s prací s ukazateli, ale ušetříme si též ověřování podmínky na platnost ukazatele v každém kroku. Obě tyto metody vrací pouze první výskyt daného prvku. Přidáním parametru typu unsigned integer a jednoduchou úpravou metody bez zarážky lze upravit hledání pro nalezení k-tého prvku. Ukážeme si verzi bez zarážky:
template<class T> CJednPrvek<T>* CLinSpojSeznam<T>::Najdi(const
T& _Data, unsigned int _k)
{
CJednPrvek<T> *lpNavrat = NULL; // implicitne nenalezeno
if(!JePrazdny())
{
CJednPrvek<T> *lpZkoumany= m_lpPrvni;
while((lpZkoumany!= m_lpPosledni) && (_k != 0))
{
if(_Data == lpZkoumany->VratData())
{
if(--_k == 0)
{
lpNavrat = lpZkoumany;
break;
}
}
lpZkoumany= lpZkoumany->VratDalsi();
}
}
return lpNavrat;
}
V tomto případě je užití zarážky složitější. Nyní metoda pro vložení dat na začátek lineárního spojového seznamu:
template<class T> bool CLinSpojSeznam<T>::VlozNaZacatek(const
T& _Data)
{
bool bNavrat = false;
if(m_lpPrvni) // pokud je pred co vkladat
{
CJednPrvek<T> *lpNovy = new CJednPrvek<T>(_Data);
if(lpNovy)
{
lpNovy->NastavDalsi(m_lpPrvni); // novy prvek bude ukazovat na puvodni zacatek
m_lpPrvni = lpNovy; // a posuneme novy zacatek
bNavrat = true;
}
// opet novy prvek nemazeme !!!
}
return bNavrat;
}
#endif
Pouze vytvoříme nový prvek a zapojíme zepředu do seznamu a upravíme ukazatel na první prvek.
Kód naleznete v sekci Downloads (projekt Seznam1).
Pro dnešek jsme si ukázali základní operace pro práci s lineárním spojovým seznamem, v příštím dílu přidáme další metody. Jak bylo slíbeno v dílech věnovaných frontě a zásobníku, povíme si jak implementovat tyto dvě datové struktury pomocí lineárního spojového seznamu. Implementovat budeme také frontu obousměrnou. A možná už příště si povíme něco o dynamicky vytvářených stromech.
Příště nashledanou.
