HPC a grid computing
Když se dnes řekne HPC, máme na mysli High Performance Computing, což se do češtiny překládá jako vysokovýkonné počítání.
Na systémy sloužící pro HPC se můžeme dívat několika úhly pohledu. Člověku je asi nejbližší pohled z fyzické roviny. Kde je co umístěné, co je s čím spojené atd. Neméně důležitý je i pohled logický – jak je co udělané, aby to fungovalo. Zkusím proto dnešní HPC systémy popsat a klasifikovat nejdříve z logického pohledu, zastavím se i u fyzického náhledu a samostatně se rozepíšu na téma klastrů – gridů.
K dnešnímu dni se zažilo členění HPC systémů na čtyři kategorie. Toto členění je založeno na způsobu zpracování instrukcí a datových toků.
Jedna instrukční sada, jedna
datová sada – SISD, Single Instruction Single Data
Jde převážně o konvenční systémy s jedním procesorem opatřeným jednou instrukční
sadou vykonávanou sériově na jedné množině dat. Nicméně některé dnešní mainframy
obsahují více než jeden procesor, vždy ale každý vykonává nezávislý instrukční
tok.
Jedna instrukční sada, více datových
sad – SIMD, Single Instruction Multiple Data
Systémy SIMD se vyznačují schopností vykonávat jeden instrukční tok nad vícero
datovými toky. Pro řadu úloh, hlavně typu paralelního datového toku, je tato
architektura schopna poskytnout vysoký výkon. Stroje SIMD mívají jednu instrukční
jednotku ICU (Instruction Processing Unit) občas nazývanou jako kontrolér
procesor a více datových jednotek DPU (Data Processing Units), někdy též nazývané
procesními elementy (PE).
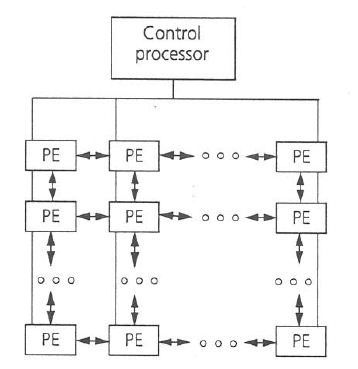
Samostatnou podmnožinu pak tvoří tzv. vektorové počítače. Ty pracují spíše než s jednotlivými daty s podobnými daty uspořádanými v polích. Používají speciální struktury CPU, která jim dovoluje pracovat s daty téměř paralelně. Pokud tyto stroje pracují ve vektorovém modu, poskytují mnohonásobně vyšší výkon, než když pracují v konvenčním skalárním módu.
Více instrukčních sad, jedna
datová sada – MISD, Multiple Instruction Single Data
Teoreticky tyto systémy umějí provádět nad jedním datovým tokem více toků
instrukčních sad. Prakticky se ale takové systémy nekonstruují.
Více instrukčních sad, více datových
sad – MIMD, Multiple Instruction Multiple Data
Tyto systémy vykonávají několik instrukčních toků paralelně nad různými daty.
Na rozdíl od víceprocesorových systémů SISD jsou instrukce a data závisle
spojené. Procesor zpracovává různé části stejné úlohy. Systémy MIMD mohou
pracovat s mnoha podúlohami paralelně, aby zkrátily čas potřebný k vyřešení
hlavní úlohy. Většina víceprocesorových počítačů patří právě do této kategorie
a podle architektury je ještě dále dělíme (viz obrázek).
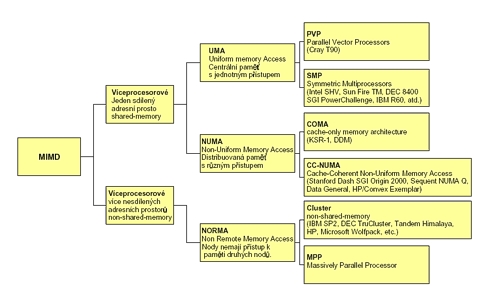
UMA – Uniform Memory Access
Paralelní počítače mívají paměť buď centrální nebo distribuovanou. Systémy s centrální pamětí jsou známé také jako UMA architektury. U těchto systémů platí, že všechny paměti jsou zhruba stejně vzdálené od všech procesorů a stejně tak i přístupové časy ke všem jednotkám paměti jsou zhruba stejné. Hlavním znakem pak je, že centrální paměť je sdílená. Existují dva druhy UMA architektury – systémy s paralelními vektorovými procesory a symetrické multiprocesorové systémy.
PVP – Parallel Vector Processors
Architektura typického PVP systému je zobrazena na následujícím obrázku:
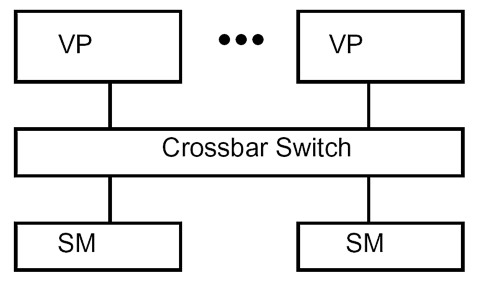
Příkladem takové architektury pak může být počítač Cray C-90, Cray T-90 nebo NEC SX-4. Takové systémy mívají menší počet specializovaných vektorových procesorů (VP). Procesory jsou spojené se sdílenou pamětí (SM – Shared Memory) switchovanou sítí s velkou propustností. Tyto stroje normálně nepoužívají cache paměti, raději používají instrukční buffer a velký počet vektorových registrů.
SMP – Symmetric Multiprocessors
Tato architektura poskytuje globální fyzický adresní prostor se symetrickým
přístupem. Každý procesor (P/C) může přistupovat ke všem částem sdílené paměti
(SM). Tento koncept se ujal nejenom u velkých drahých superpočítačů, ale i
u dnešních pracovních stanic. Stále více desktopových systémů se objevuje
s kapacitou čtyř procesorů a dnešní servery běžně obsahují osm, šestnáct a
více procesorů. Krása tohoto modelu je v tom, že všechny procesory sdílejí
stejný adresní prostor a vytvářejí pro uživatele (programátora) jednotný systém
bez jakékoli granularity.
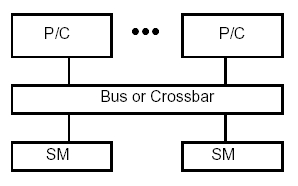
U SMP architektury se běžně používají dvě metody pro spojení mezi procesorem a pamětí. První je založená na technologii sběrnice (bus) a druhá na technologii switchovaného crossbaru (křížového přepinače). Sběrnicový systém vypadá podobně jako standardní obrázky počítačové architektury s množstvím komponent spojených jednou sdílenou datovou cestou.
Crossbarová architektura odstraňuje potencionální úzké hrdlo jedné sběrnice tím, že ji nahrazuje spojením typu každý s každým, popřípadě switchem. To zaručí, že opravdu každý procesor může mít v reálném čase svou datovou cestu k jakékoli části paměti. To však u velkých systémů vede ke značné hardwarové složitosti a k obrovskému nárůstu ceny řešení.
NUMA – Non-Uniform Memory Access
Systémy NUMA většinou obsahují více uzlů – nodů. Takový uzel si můžeme představit jako jakýsi základní stavební blok, který zpravidla obsahuje jeden nebo více procesorů a lokální paměť. Pamětem na cizích uzlech se říká vzdálené – remote memories. V dnešních komerčních a vědeckých řešeních existují tyto typy řešení distribuované paměti.
• Cache-Only Memory Architecture (COMA)
• Cache-Coherent NUMA (CC-NUMA)
• Non-Cache Coherent NUMA (NCC-NUMA) – jednotlivé uzly mají přístup k paměti
vzdálených uzlů, ale není řešena koherence jednotlivých pamětí.
Klíčovou roli v NUMA architekturách dnes hrají systémy COMA a CC-NUMA
COMA – Cache-only memory architecture
V této architektuře je paměť jednotlivých uzlů distribuována mezi ostatní
uzly. Nealokuje se však fyzický adresní prostor, ale paměť každého uzlu je
převedena do velké cache paměti, která většinou bývá pomalejším mediem. Převod
se provádí dodatečným hardwarovým zařízením. To umožňuje velkou a pružnou
replikaci dat, ale vyžaduje komplexní hardware a protokol pro zajištění koherentnosti
dat. Tím zpravidla bývají:
• Hašovací funkce k mapování mezi fyzickým
adresním prostorem používaným procesorem a reálnou fyzickou adresou DRAM cache,
která může držet daný záznam.
• Paměťové tagy a porovnávače, které určí, která řádka z daného setu cache
paměti obsahuje požadovaná data.
• Extra paměťové stavy k řízení vybraných řádek z cache paměti.

Účelem tohoto hardwarového zařízení je vytvoření duplikátu fyzického adresního prostoru generovaného každým procesorem na domácím uzlu. Tím se COMA liší od architektury CC-NUMA, kde fyzická adresa přímo definuje, na kterém uzlu jsou data umístěna.
Výhodou COMA architektury proti CC-NUMA
je umožnění větší flexibility (právě díky tomuto přidanému hardwarovému zařízení).
Data jsou automaticky kopírována nebo migrována do fyzické paměti toho uzlu,
který je právě bude používat. Toto dynamické vyvažování dat na jednotlivých
uzlech umožňuje systémům COMA tvářit se jako CC-NUMA, včetně vlastností obsluhujících
migraci a replikaci stránek paměti používaných v aplikacích napsaných pro
CC-NUMA systémy. To znamená, že na některých COMA systémech mohou běžet aplikace,
které ne zrovna dobře mapují architekturu CC-NUMA, například aplikace, které
mají požadovaný větší paměťový prostor než jaký fyzicky má daný uzel. Nevýhodou
COMA architektury je, že vyžaduje nestandardní paměťové hardwarové systémy.
COMA systémy dnes patří k nejvýkonnějším, ale daň za to je ve v vysoké ceně
a v delších vývojářských časech.
CC-NUMA – Cache-Coherent Non-Uniform
Memory Access.
Fyzická paměť je distribuována mezi jednotlivé procesory tak, že malá část
paměti vždy patří k jednomu. Požadavek na paměť tak prochází přes vnitřní
spojovací sít. Přístup k lokální paměti bývá rychlý, ale latence při přístupu
k vzdálené paměti bývá o výrazně větší. Stejně jako u jednoprocesorových systémů
se využívá cache pamětí L1 a L2 – viz obrázek.
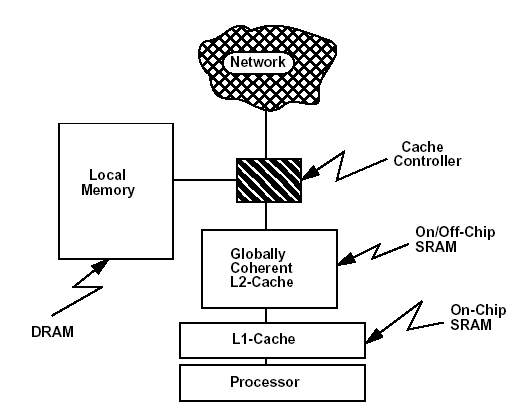
V tomto okamžiku se asi hodí vysvětlit,
co rozumíme pod pojmem „cache coherent“ popřípadě „cache coherency“.
Následující platí nejenom pro systémy CC-NUMA, ale i pro systémy UMA (tedy
PVP a SMP). Pokud si vezmu model z předchozího obrázku který obsahuje:
• procesor;
• L1 cache, která je malá (řádově stovky kB), často bývá součástí procesoru
a proto je přístup do ní velmi rychlý;
• L2 cache, která je již větší (řádově desítky MB), bývá velmi blízko procesoru
a přístup do ní je sice pomalejší než do L1, ale stále velmi rychlý;
• lokální paměť RAM, která bývá velká (řádově desítky GB), je fyzicky dále
a i přístupové časy k ní jsou dlouhé.
V modelu si můžeme představit procesor,
který pracuje s elementy (těmi jsou data, instrukce a adresy) a nestará se,
co jsou zač – prostě je zpracovává podle nějakých pravidel.
Tyto elementy jsou zapisovány do registrů. Najdeme je také v L1 cache, kde
několik tvoří paměťovou řádku (někdy také paměťový blok), nejčastěji o velikosti
32, 64 nebo 128 bajtů a už zde (v L1 cache) najdeme instrukční řádky, adresní
řádky a datové řádky.
Pokud více procesorů sdílí lokální RAM paměť, je třeba vyřešit, jak k této paměti přistupují. Pokud procesor potřebuje nějaká data, hledá je nejprve ve své L1 cache, potom v L2 cache – když je nenajde, žádá o ně v popsaném řetězci o stupeň výše. Jde o požadavek typu „chci svoji kopii datového bloku". Následně může dojít k několika scénářům:
a) Žádný jiný procesor nemá kopii daného
bloku – není problém, procesor si udělá kopii.
b) Jiný procesor má kopii požadovaného bloku (asi nad nim pracuje – může mít
na blok výlučné právo nebo ho může mít v režimu, kdy ostatní procesory mají
právo daný blok číst). Musím tedy zajistit aby „majitel" bloku zapsal
svoje změny a blok uvolnil. V praxi ještě existují přesnější určení, v jaké
paměti (L1, L2, RAM) je právě daný blok a v jakém je stavu.
Mechanismus, který zajišťuje udržování požadovaných bloků v aktuálním stavu se nazývá cache coherency.
V praxi existuje několik metod jeho implementace, nejpoužívanější jsou:
a) Broadcast (snooping) – všechny požadavky
jsou posílány na všechna zařízení a ta se poohlédnou (snoop), zda právě nevlastní
daný blok ve své cache paměti. Pokud ano, odpoví.
b) Poin-to-point – požadavky jsou posílány pouze na ta zařízení, o nichž je
známo, že měla něco do činění s daným blokem. Většinou to bývá speciální RAM,
která si pamatuje ukazatele a jejich historii. Často se ji také říká director.
NORMA – Non-Remote Memory Access
U systému s architekturou NORMA má každý uzel svůj vlastní paměťový adresní prostor – uzel nemůže přímo přistupovat k paměti vzdáleného uzlu. Pokud chce nějaká data ze vzdálené paměti, vyžádá je pomocí průvodní zprávy (MP – Message Passing). První uzel pošle požadavek formou MP na druhý a ten v rutinní dávce zkopíruje data na uzel první. Celý mechanismus průvodních zpráv je dnes požíván ve formě protokolu MPI nebo protokolu OpenMP.
NORMA model se dále člení na MPP (Massively Parallel Processors) a klastry.
MPP – Massively Parallel Processors
Běžná architektura MPP systému je na následujícím obrázku:
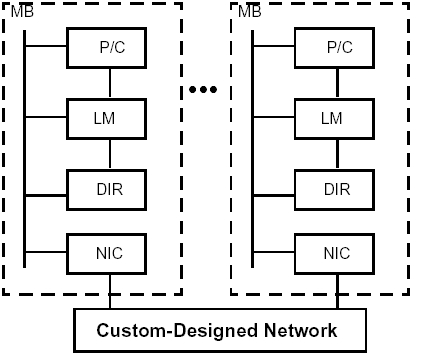
Všechny masivně paralelní systémy používají fyzickou distribuovanou paměť a stále více systémů také distribuovaná I/O zařízení. Každý uzel má jeden nebo více procesorů s cache (P/C), lokální paměť (LM) a většinou nějaký disk (LD – local disk) a cache director (DIR). Uzel má lokální propojení (interconnect), spojující procesor, paměť a I/O zařízení. Dříve býval tímto propojením jeden z typů sběrnice, u dnešních MPP se spíše setkáváme s crossbarovou architekturou s vysokou propustností. Každý uzel je připojen do sítě prostřednictvím NIC (Network Interface Circuitry ).
MPP je typ systému, v němž pod jedním programem běží mnoho samostatných procesů. Tímto se velmi podobá SMP s tím velkým rozdílem, že u SMP všechny procesory sdílejí jednu paměť, zatímco u MPP má každý procesor paměť vlastní. Proto je také psaní programů pro MPP výrazně složitější, jelikož aplikace musí být rozdělena na segmenty, které mohou být vykonávany samostatně a dokáží s ostatními částmi komunikovat. Na druhou stranu zde nenastává známé úzké hrdlo SMP systémů, když více procesorů zkouší zároveň přistupovat ke stejné paměti.
MPP dnes začínají hrát v HPC důležitou roli, a to díky nízkým cenám běžných čipů i nízkým cenám jednotlivých uzlů – velmi dobře vychází jejich poměr ceny k výkonu. Dokáží také nabídnout obrovskou absolutní velikost paměti a její vysokou propustnost. Pro vhodné problémy a pro část úloh s velkými požadavky na paměť jsou MPP systémy opravdovou jedničkou.
Důležité vlastnosti MPP:
• používá v procesních uzlech běžné čipy;
• používá fyzicky distribuovanou paměť mezi procesorovými uzly;
• podporuje standardní programovací modely jako PVM (Parallel Virtual Machine)
a MPI (Message Passing Interface);
• používá interconnect s vysokou propustností a nízkou latencí (velmi často
například infiniband);
• je to asynchronní MIMD stroj, tzn. že procesy jsou synchronizovány pomocí
blokových operací s průvodními zprávami;
• program pro MPP obsahuje více procesů, z nichž každý má svůj vlastní adresní
prostor a které mezi sebou komunikují pomocí průvodních zpráv (MP).
Klastry – Gridy
Klastry či gridy jsou systémy sestavené z celých počítačů. Existují dva základní
typy klastrů, první je složením více počítačů s cílem získat vyšší dostupnost
(HA – High Availability) celého systému, druhý typ je také složen ze samostatných
počítačů, ale s cílem získat vysoký výpočetní výkon. Druhé skupině se také
často říká výpočetní grid.
V tomto článku hovoříme o klastrech jako o systémech určených pro HPC. Každý uzel klastru je do systému připojen spojením typu LAN nebo jinou sítí s vysokou propustností. Typicky je každý uzel reprezentován SMP serverem, pracovní stanicí nebo obyčejným PC. Důležité je, že všechny uzly musejí být schopné pracovat dohromady jako jeden integrovaný výpočetní zdroj.
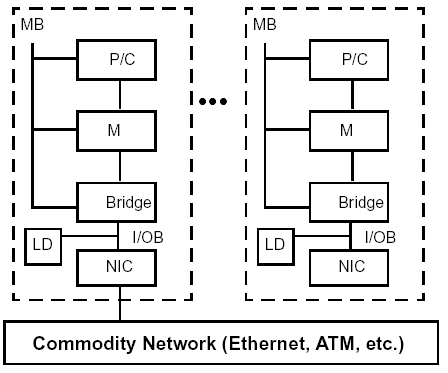
Problematika klastrů a gridů
Charakteristické vlastnosti
klastrů a gridů
• Každý uzel je tvořen samostatným počítačem. To znamená, že má procesor s
cache (P/C), lokální paměť (M), lokální disk (LD), interconnect (N IC), lokální
I/O zařízení a vlastní instanci operačního systému.
• Jednotlivé uzly v klastru jsou navzájem spojené – běžně pomocí vyhrazené
sítě typu ethernet, FDDI, Fiber channel, infinibiband, mirinet nebo ATM. Velmi
často se při vzájemné komunikaci používají standardní protokoly.
• Klastry přinášejí také zlepšení dostupnosti určité služby (při výpadku jednoho
uzlu může jiný transparentně zastat jeho práci).
• Klastry přinášejí lepší využití stávajících výpočetních zdrojů (hovoří se
o 80% využití procesorový cyklů).
• Klastry mohou nabídnout řešení úloh na vyžádání (on demand), neboli poskytnutí
tolika zdrojů právě v tom čase, kdy jsou potřebné.
• Klastry mohou spojit i více platforem, především unixových, resp. linuxových.
• Klastry mohou v řadě typů služeb nabídnout vyšší výkon. Pokud každý z M
uzlů klastru dokáže obsloužit N klientů, může celý klastr simultánně obsloužit
M*N klientů. Klastr se dá využít také ke zkrácení celkové doby běhu úlohy
jejím rozložením do několika paralelních úloh.
Celý výpočet na klastrech má několik
rovin:
• Rovinu budování klastru – spojování jednotlivých uzlů do sítí-gridů a fyzické
připojení dalších zdrojů typu diskových polí.
• Rovinu řízení klastru, jeho virtualizace do jednotného systému, který se
směrem k uživateli může tvářit jako jeden stroj.
• Rovinu psaní aplikací a běhu konkretních úloh.
Budování klastru – gridu
Při výstavbě klastru se dnes nejčastěji setkáme se třemi scénáři:
1. Spojení stávajících výpočetních systémů do jednoho klastru. Příkladem může
být univerzita nebo jiná větší organizace, která vlastní řadu pracovních stanic,
středních serverů a PC, které přes den slouží uživatelům a v noci jejich výpočetní
výkon leží ladem. Taková organizace většinou již má i síť LAN, do níž jsou
tyto stroje připojené. Potom už stačí jen na každý stroj nainstalovat klientský
software a nastavit pravidla pro chování celého systému. Často bývá největší
problém organizační a bezpečnostní stránka projektu. Z technického hlediska
můžeme narazit na úzká hrdla ve spojení jednotlivých uzlů (LAN).
2. Organizace buduje klastr na zelené louce a nakoupí větší počet levných
strojů (dnes nejčastěji serverů na platformě x86 s Linuxem). Tyto stroje propojí
dedikovanou sítí (jak už bylo řečeno na technologiích ethernetu, fiber channelu
nebo infinibandu) a pro servery poskytne diskové prostory, dnes nejčastěji
na bázi diskových polích typu NAS (Network Attached Storage) a protokolu NFS.
3. Třetí scénář se velmi podobá druhému a liší se typem serverů. Nejoblíbenějšími
servery do druhého scénáře jsou servery vysoké jeden RU (skříňový modul) s
jedním nebo dvěma procesory – používají se servery typu blade. Výhodou této
varianty je obrovská hustota CPU docílitelná v malém prostoru. Všichni velcí
výrobci už dnes nabízejí blade servery, nicméně jejich existence je zatím
příliš krátká a jejích masové rozšíření se teprve očekává.
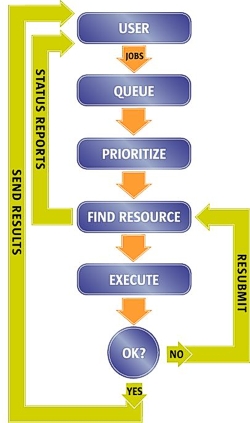 Řízení
klastrů – gridů
Řízení
klastrů – gridů
Dnes existuje mnoho softwarových produktů, které nabízejí klastrovou funkcionalitu,
například Sun ONE Grid Engine od firmy Sun Microsystems, Globus Grid od firmy
IBM, LSF či open-source Boewulf. Jejich porovnání by vystačilo na samostatný
článek, hlavní myšlenka však je společná. Uživatel pošle svojí úlohu do fronty,
úloze se najdou odpovídající zdroje a pak se odešle k vykonání. Výsledek se
pošle zpátky klientovi.
Rozhraním, kterým uživatel svoje úlohy posílá a prohlíží si jejich stav a status, bývá dnes nejen příkazová řádka (CL – Command Line) nebo grafické rozhraní (GUI – Grafical User Interface) ale i webové rozhraní typu portál. O řazení úloh do front, vyhledávání zdrojů a monitorování celého klastru se stará hlavní řídící server (master server). Na jednotlivých uzlech klastru je nainstalovaný klientský software, který přímá úlohy od master serveru a postará se o jejich zpracování. Dnešní klastry také umějí spojovat více menších klastrů do velkých celků. Často se tak můžeme setkat s výrazy departmental grid (klastr vybudovaný v rámci jednoho oddělení), enterprise grid (klastr složený z více menších klastrů, ale stále v rámci jedné organizace) či global grid (klastr klastrů, grid gridů, spojení více eneterprise klastrů na úrovni regionů, států nebo kontinentů).
Dobrou zprávou je také to, že existuje snaha o koexistenci různých typů klastrů v globálních gridech. Pracuje se na standardech, které umožní kompatibilitu například klastrů užívajících Sun ONE Grid Engine nebo IBM Globus Grid.
Psaní aplikací pro klastr – grid
Každému, kdo jen trochu ví, jak počítače fungují, musí být jasné, že aplikace
napsaná pro jednoprocesorový stroj s nejrozšířenější architekturou typu MIMD
(nebo i pro víceprocesorové servery typu SMP) nemůže jen tak běžet na klastru
složeném ze stovek uzlů. V drtivé většině případů je nutný zásah programátora
a rozsah tohoto zásahu se liší případ od případu. Platí zde klasické schéma:
• řeším reálný problém;
• problém popíši fyzikálním modelem;
• fyzikální model popíši matematickým modelem;
• najdu vhodné numerického schéma odpovídající matematickému modelu;
• napíši aplikaci, která odpovídá numerickému schématu;
• při psaní aplikace používám nějaký programovací model, případně z něho odvozený
programovací jazyk (C,C++,F77,F90) – programovací model je poplatný hardwarové
architektuře.
Programátor je tak při psaní aplikace držen „uprostřed“ a jeho kód musí odpovídat jak programovacímu modelu, tak i navrženému numerickému schématu. Při psaní aplikace pro klastr pak obecně stojí před úkolem problém rozložit do menších paralelních úloh.
Problém paralelizace
Některé problémy z reálného světa lze velmi dobře paralelizovat již při tvorbě
fyzikálního a matematického modelu. V takovém případě bývá zásah programátora
relativně malý. Všechny reálné problémy toto štěstí nemají a pak programátor
musí řešit i modifikaci programovacího modelu. Setkáváme se zde s těmito pojmy:
Vlákna – samostatné
procesy, mající více exekučních cest.
RMO (Remote Memory Operation) – sada procesů, z nichž každý
může přistupovat k paměti jiného procesu bez jeho asistence.
SMD (Shared Memory Directives) – příkazy, pomocí nichž uživatel
definuje, jak se úloha paralelizuje. Způsob rozložení dat je v tomto případě
implicitní a vnitřní komunikace je také implicitní. Samotná paralelizace nastává
při kompilování. S tímto typem paralelizace se nejvíce setkáváme u SMP strojů
a od roku 1997 je v této oblasti standardem OpenMP. Typicky jsou dány sekce,
které mají být prováděny paralelně, a rovněž jsou dány smyčky, které mají
běžet paralelně.
Datový paralelizmus – uživatel definuje, jak budou data distribuována,
a vnitřní komunikace je implicitní. Uživatel explicitně definuje rozložení
na menší komponenty a vlastní paralelizace nastává při kompilování. Standardem
je dnes HPF (High Performance Fortran). Typické jsou distribuované matice
a vektory a pole s podobnou konstrukcí.
Message Passing (průvodní zprávy) – uživatel definuje jak
budou data distribuována, kdy a jak bude provedena vnitřní komunikace a explicitně
definuje i rozdělení dat a komunikace. Standardem je dnes MPI (Message Passing
Interface)
Který z modelů paralelizace je pro daný problém vhodný záleží na aplikaci, na hardwarové platformě, na tom, jaká účinnost je od platformy očekávána a na tom, kolik času je k dispozici pro realizaci paralelizace.
| Typ systému | SMP | Klastry složené z SMP strojů s možností přístupu do vzdálených pamětí RDMA (remote directive memory access) | Klastry složené z SMP strojů bez možností přístupu do vzdálených pamětí RDMA (remote directive memory access) | MPP |
| bez ochranného programování | OpenMP | OpenMP nebo HPF | HPF | HPF |
| s ochranným programováním – ruční práce | MPI | MPI+OpenMP | MPI+OpenMP MPI je aplikováno na všech procesorech | MPI |
Charakteristika typů gridového systému:
snadno programovatelný
těžší na programování
náročný na sestavování kódu
velmi náročný na sestavování kódu
složitý na sestavování paralelizovaného kódu
Reference
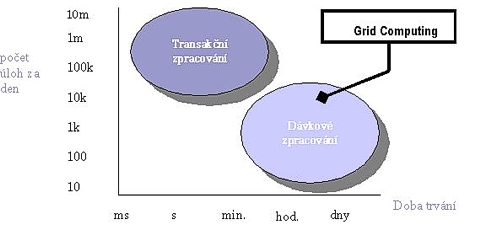
Dnes se setkáme s implementací gridů nejčastěji v těchto odvětvích:
• EDA (Electronic Design Automation) při návrhu a testování elektronických
součástek.
• Aplikovaná věda: genové inženýrství, farmacie.
• Automobilový průmysl: bariérové testy, napěťové testy, aerodynamika.
• EDA: simulace, ověřování, zpětné testy.
• Zábavní průmysl: rendering filmových políček.
• Těžařský průmysl: vizualizace, analýza dat.
• Vývoj softwaru: sestavování kódu.
• Vědecký výzkum: úlohy s velkými výpočetními nároky.
Vesměs jde o úlohy které mají dávkový charakter a vyznačují se dlouhou dobou běhu.
Konkrétní reference můžete najít například na následujících adresách:
http://wwws.sun.com/software/grid/success.html
http://www-1.ibm.com/grid/grid_customer.shtml
Jednoduchý návod na vybudování
gridu
1. Identifikujte své potřeby. Pro každý typ úlohy, kterou chcete zpracovat
v gridu, byste měli znát typ úlohy (běží v jednom vláknu, ve více vláknech
nebo ve více procesech), paměťové nároky na procesech a dobu běhu procesu.
Pokud jde o úlohu běžící ve více procesech, analyzujte úroveň meziprocesní
komunikace a podle toho se rozhodněte, zda potřebujete stroj SMP nebo rychlý
interconnect.
2. Odhadněte, jak se vaše nároky budou měnit v blízké budoucnosti.
3. Zjistěte, zda některá aplikace nemůže běžet pouze na dané platformě. To
ovlivňuje možnost mít v klastru více platforem.
4. Určete, existují-li mezi stávajícími stroji takové, které by mohly sloužit
jako výpočetní uzly budoucího klastru.
5. Zařiďte, aby byl klastr spravovatelný jako jeden výpočetní zdroj:
• vytvořte nebo použijte stávající nástroj pro „soft update“ (nástroj na automatické
instalace OS a jejich snadné konfigurace);
• vytvořte nebo použijte stávající nástroje na automatickou instalaci patchů;
• pokud bude v klastru licenční server, ujistěte se, že má vysokou dostupnost;
• vytvořte nebo použijte hotový nástroj, který umí zajistit běh úlohy na libovolném
uzlu klastru;
• vytvořte nebo použijte hotový nástroj, který vám umožní řídit celý klastr
z jednoho bodu.
6. Rozhodněte se, jaký budete používat frontový systém (NQS, PBS, Sun ONE
Grid Engine, LSF). Nainstalujte jej na nod, který bude ve funkci front master.
Pokud budete v klastru potřebovat sdílení souborů, budete asi potřebovat diskové
pole typu NAS, které poskytuje diskové prostory například přes NFS. Pokud
budete na některých uzlech potřebovat knihovny MPI, nainstalujte je.
7. Naučte uživatele posílat úlohy do front místo toho, aby je spouštěli interaktivně.
8. Rozhodněte se, které další výpočetní zdroje zapojíte do gridu. Vytvořte
pravidla k tomu, aby stroje s jedním procesorem byly využívány pro jednoprocesorové
úlohy a stroje s dvěma či více procesory pro úlohy víceprocesorové.
9. Pokud jsou některé aplikace paralelizované, ale jejich vnitřní komunikace
není příliš intenzivní, můžete zvážit spojení několika uzlů rychlým interkonektem
typu mirinet nebo přidání SMP stroje do klastru.
10. Pokud jsou některé aplikace paralelizované a jejich vnitřní komunikace
je velmi intenzivní, je přidání většího SMP stroje nebo spojení stávajících
uzlů rychlým interkonektem téměř nutností.
Infotipy:
http://www.sun.com/grid
http://www-1.ibm.com/grid
http://www.hp.com/techservers/grid
http://help.aei-potsdam.mpg.de/sc/lsf
http://www.beowulf.org
http://www.openmp.org
http://www-unix.mcs.anl.gov/mpi
http://www.sun.com/blueprints
http://www.hlrs.de
Použitá literatura:
Sun blueprint – Sun Based Beowulf Cluster
IBM redbook – Introduction to Grid Computing with Globus
Wolfgang Gentzsch – Grid Computing: A New Technology for the Advanced Web
Jaroslav Nadrchal, FZU AVČR – Architectures of Parallel Computers
Rolf Rabenseifner, Michael M. Resch, University of Stuttgart – Hardware Architectures
and Parallel Programming Models
