 Mnozí z nás se dostávají do problému, jak
archivovat hmotnou předlohu textu do počítače a nemusí to být nutně jen papír, tiskne se
i na další a méně skladné materiály.
Důležité je předlohy správně naskenovat a nejlépe, s co nejmenší námahou,
je převést do textové
podoby pro zpětnou editovatelnost. Protože se nám podařilo pro Chip získat
plnou verzi rozpoznávacího programu FineReader 5 Sprint v české a slovenské
lokalizaci (instalace), rozhodli jsme se této otázce věnovat více
včetně teorie OCR. Pro úplnost jsme oprášili
i poslední test stolních
skenerů a recenzi nejnovější verze FineReader
6.0.
Mnozí z nás se dostávají do problému, jak
archivovat hmotnou předlohu textu do počítače a nemusí to být nutně jen papír, tiskne se
i na další a méně skladné materiály.
Důležité je předlohy správně naskenovat a nejlépe, s co nejmenší námahou,
je převést do textové
podoby pro zpětnou editovatelnost. Protože se nám podařilo pro Chip získat
plnou verzi rozpoznávacího programu FineReader 5 Sprint v české a slovenské
lokalizaci (instalace), rozhodli jsme se této otázce věnovat více
včetně teorie OCR. Pro úplnost jsme oprášili
i poslední test stolních
skenerů a recenzi nejnovější verze FineReader
6.0.
OCR a čo s tým
alebo Ako previesť papierovú predlohu do textového súboru
Skenovanie:
Takže ak to chceme spraviť, musíme mať skener, ktorým obraz predlohy zosnímame
do počítača. Môže to byť aj digitálny fotoaparát, ale ten má na tento účel pomerne
nízke rozlíšenie. Našťastie to už prestáva platiť, ale musí byť k nemu statív,
dobrý /rovnomerný/ zdroj svetla a rozlíšenie aspoň 2MPx. Nezabudnime na to,
že v tejto etape dostaneme do počítača iba bitovú mapu, nie hotový text!
Dôležitý je výber vhodného skeneru. Budem hovoriťo skeneroch pre domáce použitie,
kategória SOHO, teraz do cca 3-4000,- Sk. Na knihy sú pomerne nevhodné skenery
s CCD snímačom - tie najlacnejšie a najľahšie niekedy ani nepotrebujú napájací
zdroj. Rozoznajú sa aj tým, že u nich je zdrojom svetla pás na zeleno svietiacich
diód. Dajú sa použiť iba na jednotlivé listy, pretože majú malý svetelný výkon,
maximálne na 1mm od skla. Obvykle sú aj výrazne pomalšie. Odporúčam skenery
s vlastnou lampou, či už halogénovou - /Umax/ alebo lampou so studenou katódou
/Microtek/. Halogénové lampy majú rýchlejší nábeh, ale niekoľkokrát menšiu životnosť,
studenokatódové by mali chvíľu bežať, kým sa ustáli ich svetelný tok. Obraz
je obvykle ostrý až do 20mm, rozoznateľný do 30mm. Pokiaľ majú externý zdroj,
rýchlosti sú podobné - či už sú s rozhraním SCSII, USB, paralelný port. Bežne
zosnímajú stranu A4 v rozlíšení 300DPI a vo farbe /25MB/ do dvoch minút, 600DPI
/100MB/ do štyroch minút. Pri 300DPI a 8bit šedej A4 trvá cca 40-60sekúnd. USB
a SCSII mávajú rýchlejší náhľad, do 20 sekúnd. Čo som skúšal napríklad Microtek2000,
napájaný cez USB - je dobrý, ale zúfalo pomalý. Na rozlíšení nezáleží, všetky
zvládajú rozlíšenie 300DPI /bodov na palec/, ani pri skenovaní obrázkov nemá
význam ísť vyššie - iba pri skenovaní negatívov je potrebné aspoň 1200DPI, dianástavec
a skener musí vedieť vypnúť vlastnú lampu.
Medzi skenermi vybavenými USB a paralelným portom, prípadne SCSII nie je v rýchlosti
výrazný rozdiel, robieva to asi 10-20% v prospech USB /SCSII/, ale rýchlosť
procesora sa podpíše veľmi výrazne. Napríklad PII 700 oproti P100 robí na rýchlosti
viac ako 100%!
Multifunkčné zariadenia sa dajú takisto použiť /napríklad HP/, ale musíme si
uvedomiť, na aký účel sa bude používať skenovaciu časť. Ak má celé zariadenie
tvar tlačiarne, môžeme doň vložiť iba jednotlivé listy a na oskenovanie zviazanej
brožúry môžeme zabudnúť. Vhodnejšie /a drahšie a väčšie/ sú s rovnou doskou
pre skenovanie - ale sú univerzálnejšie.
V poslednom čase sa objavili skenery s rozhraním USBII. Ich mechaniky sú stavané
na rýchlejší pohyb, náhľad býva do 10 sekúnd, čo bolo ešte nedávno výsadou špičkových
SCSII skenerov. Pre tých, čo majú veľa skenovania sú zrejme vhodnejšie.
Dosť veľa záleží od vhodného ovládača pre skener. Vždy nejaký čas trvá, kým
výrobca vychytá muchy, takže ak pri skenovaní počítač padá alebo je skenovanie
príliš pomalé, neváhajme a stiahnime si novší ovládač zo stránky výrobcu. Mne
napríklad novší ovládač /skener Microtek V6USL/ zrýchlil skenovanie skoro o
polovicu.
S vhodným skenerom sa dá skenovať cca 200strán za hodinu /100 snímkov/, pri
nastavení 300DPI, 8bit šedej /gray scale/, dve stránky A5 na jeden raz, jeden
snímok potom zaberie asi 7MB. Treba rátať aj s dostatočne veľkým diskovým priestorom
cca 500 - 1000MB na jednu knihu. Nezáleží na výstupnom formáte, ten si prednastaví
skener a bolo by ho potrebné stále meniť - stačí použiť nekomprimovaný TIFF,
BMP, PCX, každý moderný OCR /Optical Character Recognition - Optické rozoznávanie
znakov/ ich pozná. Najvhodnejší je nekomprimovaný Tiff, napríklad PNG z AcdSee3
mi FineReader6 nezobral, zatiaľ čo z XnView bol bez problémov.
Ak stránka obsahuje grafiku, ktorú chceme zachovať, je vhodné si vždy urobiť
náhľad /preview/, text potom zosnímať ako odtiene šedej a obrázok ako pravé
farby /true color/. OCR to obvykle síce zvládne, ale väčšinou je potrebné obrázky
mierne natočiť, orezať na správnu veľkosť, použiť vhodný filter, vymazať chyby,
upraviť úrovne... Ak ide iba o text, stačí si raz nastaviť výrez a potom už
iba odťukávať a otáčať strany.
Program na prezeranie obrázkov ACDSee /od verzie 3.00/ alebo XnView /freevare/
majú možnosť Acquire /využívajú Twain rozhranie na získanie obrázkov/. V položke
Acquire setup nastavíme adresár, do ktorého ukladáme obrázky, formát a spôsob
automatického číslovania a dáme Acquire now. Program zavolá rozhranie Twain
a v ňom sa sa už iba odklepne SCAN. ACDSee v pozadí preberá obrázky, konvertuje
do zvoleného formátu a čísluje ich.
Skenovať sa dá aj priamo z OCR - buď pomocou Twain rozhrania alebo priamo z
programu. V takom prípade stačí výrazne menší diskový priestor ale napríklad
FineReader verzie 5 na Win 98 je v tomto režime háklivejší, ľahšie padá.
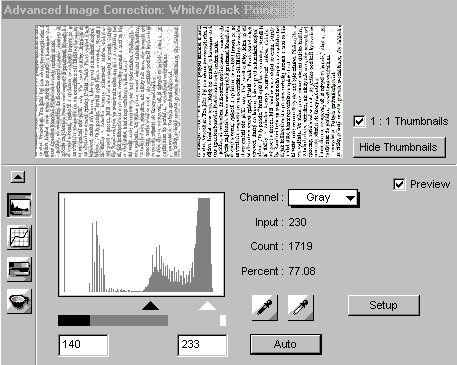
Časom som prišiel na jednu vec, ako zlepšiť obraz počas skenovania. Dlho som
totiž laboroval s nastavením jasu a kontrastu - veľmi to nepomáha, takže ich
ponechávam na default hodnotách. Ale výrazne pomáha v nastavení Twain v záložke
Advanced Image Correction: White/Black Points - najprv dám Auto - tým sa automaticky
odstránia prázdne okraje a potom ťahám ľavý /čierny/ trojuholník doprava. Tým
sa odstráni zažltnutosť strán a vyblednutosť textu.
Prevod do textu:
Je jasné, že oskenovaný obrázok zaberá príliš veľa priestoru. Dá sa zmenšiť
pri použití vhodnej kompresie, zmenšením počtu bodov, farebnej hĺbky, orezaním
na vhodný rozmer, použitím vhodných filtrov - ale stále je to obrázok, v ktorom
sa rozumným spôsobom nedá text editovať.
Na tento účel sú vytvorené rôzne programy typu OCR, ktoré pomocou inteligentných
algoritmov, vektorizácie textu a zabudovaných slovníkov rozoznávajú text z bitmapy,
prípadne ho priamo prevádzajú do textu alebo do tabuliek. Pre naše účely môžeme
použiť vlastne iba dva produkty - Recognita z maďarskej firmy Recognita, teraz
už OmniPage a Finereader od ruskej firmy Abbyy. Oba produkty sú vo verzii 5,
6, už sú veľmi slušne použiteľné. Ja osobne preferujem Abby Finereader, pretože
má lepšie výsledky pri prevode - menej chýb, nemá problémy pri farebnom pozadí
a pri veľmi zlom podklade, z domovskej stránky sa dá stiahnuť vo verzii Office
alebo Pro + príslušné slovníky podľa výberu + interface v slovenčine, čestine....
Nevýhody - je pomalší ako Recognita, stiahnutá verzia je typu Try & Buy
/30 spustení, vo verzii 6 už iba 15 spustení/ a je háklivý na zmeny hardwaru
a softwaru. Stiahnutá inštalačka /verzia 5, iba anglický jazyk/ zaberá asi 24MB,
nainštalovaná verzia cca 37MB.
Oficiálna stránka programu Abby Finereader je
www.abbyy.com, je možné si odtiaľ
stiahnuť príslušnú demoverziu. Odporúčam ísť aj na stránku www.nupseso.cz, kde
sú k dispozícii cenníky, aktualizácie, lokalizované demoverzie a návody na použitie.
Stránka programu Recognita je www.recogita.hu, na ktorej vidieť, že prešla pod
ochranné krídla OmniPage. Kedysi tam bola demoverzia Recognity 5, dnes už iba
podpora pre zakúpený produkt.
Čo sa týka stability programu FineReader, je to rôzne. Verzia 5 mi chodila
bez problémov na Win98, Win98SE i WinXP /s patchom na úpravu registrov/, zatiaľ
čo 6 mi na Win98 pri skenovaní so súčasným rozoznávaním textu pomerne spoľahlivo
asi po 30 stranách spadla /aj s operačným systémom - chyba modulu Scanman/.
Táto chyba zostala i naďalej, i keď sa tvrdí, že v novom builde sa zmenil skenovací
modul. V takom prípade je najlepšie najprv oskenovať a FineReader /ďalej iba
FR/ potom pustiť iba na obrázky. Inak na tom istom HW, s tými istými univerzálnymi
ovládačmi pod WinXP bez problémov - a je tam aj rýchlejší.
Pre tých, čo chcú experimentovať s úpravou FR, napríklad majú verziu bez jazykovej
mutácie a chcú si ju doinštalovať, pozor. FR si veľmi chráni integritu svojich
modulov a pri výmene knižníc skončí trialová verzia s nulovým počtom dní. Napríklad
Čediča /http://cedic.bonusweb.cz// svojho času dožralo, že FR6 nemal lokalizáciu,
upravil príslušnú dll - fungovalo to, ale ak ju použijeme na najnovšom builde
/647/, okamžite je po skúšaní. Dá sa tomu pomôcť iba tak, že si zazálohujeme
systémový disk /napríklad programom NortonGhost alebo Powerquest DriveImage
ešte pred inštaláciou FR/ a ak sa vám podarí zrušiť skúšanie, vrátime si systém
do pôvodného stavu a inštalujeme znovu. Pozor, vytváranie Restore Point vo WinXP
nepomôže.
Porovnanie medzi plnými verziami FR5 a 6 je z môjho hľadiska takéto: FR6 zaberá
viac miesta, je rýchlejší, vie lepšie rozoznávať, trial verzia je iba na 15
spustení. Výrobca tvrdí, že vie prečítať aj zaheslované pdf súbory, ale je to
tak, že si ich vytlačí do bmp a tie potom rozoznáva - síce s veľkou presnosťou,
ale aj tak...
Takže ďalej o programe Abbyy FineReader 5, 6 /plná verzia/:
Po inštalácii programu a jeho úspešnom spustení je potrebné najprv zvoliť pracovný
adresár, kde sa ukladajú texty, obrázky a výsledky - buď nový - File/New Batch
alebo otvoriť predchádzajúci - Open Batch. Potom je potrebné zvoliť jazyk, prípadne
viac jazykov naraz, ak sa vyskytujú v texte.
Ak sa bude prevádzť text priamo zo skeneru, musíte ho najprv nastaviť - Tools/Options/záložka
Scan/Open Image/Select Source.
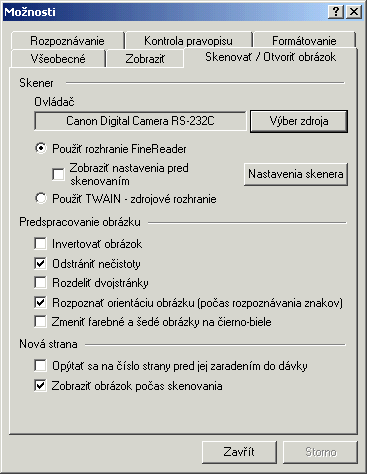
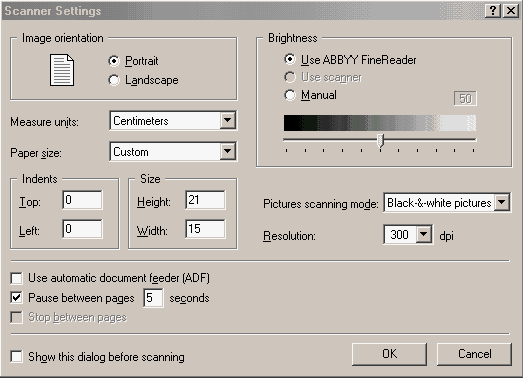
Ak sa bude prevádzať už naskenovaný obrázok, potom stačí cez tlačítko alebo
File/Open Image - formáty bmp, dcx, jpg, pcx, png, tiff.
Program obrázky načíta, vyberie vlastný náhľad, natočí do správnej polohy, prečíta,
do druhého okna vloží text, prípadne upozorní na chyby.
Samozrejmosťou je možnosť natočenia obrázka, ručného upravovania veľkosti rámcov,
ich typu /obrázok, text, tabuľka, čiarový kód/ ... - po týchto úpravách treba
príslušný dokument znovu prečítať. Výsledný text sa dá už priamo editovať, ale
ja si to nechávam na neskôr, po načítaní výsledného dokumentu do Wordu. Vyplatí
sa naštudovať si učiaci proces - hlavne pri častej práci a rovnakých podkladoch
- napríklad program si niekedy mýli ď a d'...
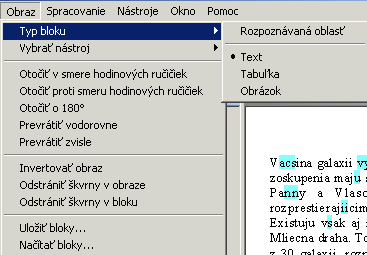
Ak už boli načítané všetky podklady, treba uložiť výsledný dokument. Ja ho ukladám
do súboru, vo formáte txt, všetky stránky do jedného súboru, s odstránením všetkých
formátovacích značiek, bez obrázkov, vo veľkosti A5. Ak chceme zachovať obrázky,
uložíme dokument ako dokument Word /bude vo formáte rtf, tak sa nečudujme, že
môže narásť aj na niekoľko sto MB/ a po otvorení vo Worde ho uložíme ako html.
Obrázky tam budú dvakrát, tie menšie vymažeme a tým máme /skoro/ originálny
naskenovaný obrázok, ktorý si môžete upraviť podľa vlastnej chute. Ale príliš
sa netešme, pretože je pri nich použitá silná kompresia /JPEG/ a detaily sa
dosť výrazne zlievajú. Takže ak chceme získať dobré obrázky, najprv podklad
oskenujeme, FR pustíme až na skeny a obrázky si robíme nezávisle.
V prípade, že ponecháme voľbu "Zachovať formátovanie", FR vytvorí
veľké množstvo štýlov, ktoré sa snažia čo najvernejšie kopírovať vzhľad pôvodného
dokumentu. Líšia sa od seba navzájom nepodstatnými drobnosťami - napríklad veľkosť
písma sa líši o 0,5 bodu, odsadenie okrajov v 0,1mm, rozšírene a zúženie písma
o 0,01mm... V dlhšom texte ich môže byť aj niekoľko stoviek. Dá sa to prežiť
vtedy, ak s tým textom už ďalej nebudeme pracovať a ak je toho iba niekoľko
strán. Ak je toho viac, je lepšie sa formátovania zbaviť a upravovať ho až pri
korektúre.
Čo sa týka náročnosti na hardware - je vysoká. Ak pustíme rozoznávanie textu
na Celeron 400, je to asi rýchlejšie klepať ručne, pri 850MHz nemôžete spustiť
žiadnu inú úlohu, ale stíha v reálnom čase - t.j. kým sa jedna strana oskenuje,
predchádzajúca sa stihne rozoznať a pri procesore nad 1000MHz už môžete popritom
aj vypaľovať CD.
Porovnanie verzie Sprint a plnej verzie:
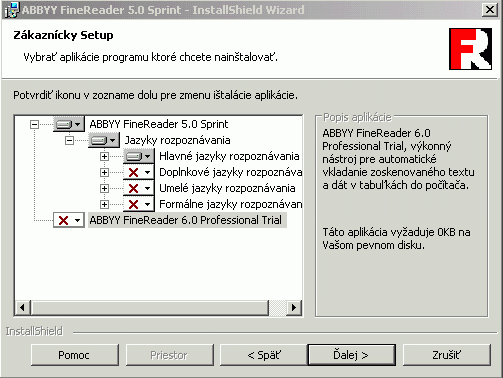
Po úspešnej inštalácii môžete dočasný adresár C:\ABBY vymazať.
Verzia Sprint je veľmi zjednodušená, hlavný rozdiel je v tom, že neumožňuje
načítať viacero obrázkov a dávkovo ich spracovať. To znamená, že vždy sa dá
otvoriť iba jeden obrázok, rozoznať ho a uložiť výsledok do súboru iba ako txt
alebo rtf. To isté platí aj pre skenovanie, vždy sa spracováva iba jedna strana.
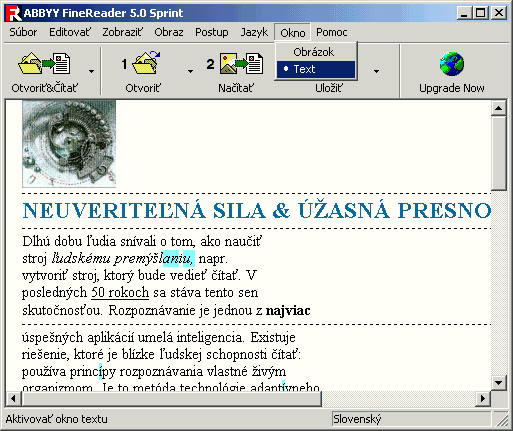
Nepodporuje viacstranové tif-y, ktoré vytvára FR6, takže je ich vhodné najprv
prekonvertovať do png. Okrem toho umožňuje použiť iba jeden rozoznávací jazyk,
je vidieť iba jedno okno - buď obrázok alebo rozoznaný text, nie oboje naraz,
nedá sa upraviť nástrojová lišta. Tiež chýba režim učenia a vytváranie užívateľských
slovníkov. Kvalita rozoznávania je veľmi dobrá, na počudovanie aj funguje celkom
svižne /žeby preto Sprint?/. Na občasné použitie je táto verzia dostačujúca.
Ak by bolo ale potrebné spraviť knihu s niekoľko sto stranami, potom je vhodnejšie
ju naprv celú naskenovať a na obrázky pustiť pribalenú FR6 trial verziu, prípadne
kúpiť plnú ako uprage na verziu Sprint.
Formátovanie a úpravy textu:
Najprv trošku všeobecne. Po digitalizácii dokumentu v texte vždy zostane určité
množstvo značiek, ktoré možno práve teraz problémy nerobia, ale neskôr sa možno
prejavia - buď pri konverzii do iných formátov, alebo pri čítaní v nových čítacích
programoch. Napríklad Word má určité rezervy, veľa vecí ignoruje - ale čo keď
sa to niekedy trafí? HTML stránky tiež niekedy na konci riadka pridávajú značku,
ktorú potom musíme odstrániť.
Najjednoduchšie sa formátovacie značky odstránia tak, že celý dokument sa uloží
ako prostý text. Ten sa potom otvorí buď priamo vo Worde alebo /lepšie/ text
sa cez schránku /Vybrať všetko alebo Ctrl+A, Skopírovať do schránky alebo Ctrl+C/
vloží do dokumentu /Vložiť alebo Ctrl+V/.
Normálne neviditeľné znaky si zobrazíme tlačítkom pre ich zobrazenie
 . Potom
je vidieť napríklad koniec odstavca, oddielu, viacnásobné medzery, voliteľné
rozdelenie, ktoré bežne nevidíme.
. Potom
je vidieť napríklad koniec odstavca, oddielu, viacnásobné medzery, voliteľné
rozdelenie, ktoré bežne nevidíme.

Vo Worde používam funkciu Rozvrhnutie dokumentu
 , podľa mňa je vhodnejšia než
Obsah. Umožňuje rýchly pohyb po dokumente a dobrý prehľad. Vyvoláva sa tlačítkom
alebo z menu Zobrazit / Rozvržení dokumentu.
, podľa mňa je vhodnejšia než
Obsah. Umožňuje rýchly pohyb po dokumente a dobrý prehľad. Vyvoláva sa tlačítkom
alebo z menu Zobrazit / Rozvržení dokumentu.
Ak je dokument zle naformátovaný, rozvrhnutie je neprehľadné, nachádzajú sa
v ňom kúsky textu... Vtedy je lepšie označiť celý dokument /Ctrl+A/ a z tlačítkového
menu Štýly vybrať Normálny, prípadne Vymazať formátovanie.
Potom sa dajú jednotlivé nadpisy označovať príslušným štýlom. Ak aj nebude hneď
vyhovovať, nevadí, po ukončení opráv sa dajú naraz upraviť z menu Formát / Štýl
/ Upraviť / Formát - odstavca alebo písma....
Číslo stránky sa obvykle nachádza na zápätí stránky, upraviť jeho formát je
možné po poklepaní. Ak chceme zmeniť niektoré vlastnosti - napríklad nezobrazovať
číslo stránky na prvej strane alebo začať číslovať nie od 1, nájdeme to v menu
Vložiť / Čísla stránek / Formát.
Word má možnosť korekcie pravopisu - samozrejme, musí byť nainštalovaná. Vie
síce automaticky rozpoznávať jazyk, ale nie je to slávne. Lepšie je označiť
celý dokument a z menu Nástroje / Jazyk / Nastavit jazyk vybrať príslušný jazyk.
Ak chceme mať slová na konci stránky rozdeľované, /preferujem, dokument sa lepšie
číta, sú v ňom menšie medzery/, je to dostupné z menu Nástroje / Jazyk / Dělení
slov.
V prípade, že chceme použiť písma mierne neštandardné /okrem klasických napríklad
Ariel, Times/, je dobré mať povolenú funkciu Vložit písma True Type z menu Nástroje
/ Možnosti / Uložit. Ak povolíme funkciu Vložit pouze použité znaky, môže sa
pri otvorení na druhom počítači stať to, že dokument bude otvoriteľný iba pre
čítanie a nebude sa dať editovať. Pomôže vybrať celý obsah cez schránku a uložiť
ako nový dokument.
A na koniec:
Mnoho ľudí si myslí, že po prehnaní podkladu cez OCR získa na 100% taký istý
text. Nie je to pravda. Podľa kvality podkladu sa získa text s určitou chybovosťou
- ak je dobrý, býva 1-2 chyby na stránke, ale môže byť i niekoľko desiatok.
Nerátam v to záhlavia a čísla stránok, ktoré vlastne tiež treba odstraňovať.
Preto vždy musíme po OCR ešte skontrolovať výsledný dokument a porovnať ho s
originálom, upraviť formátovanie, aby sa zhruba podobalo na originál a aby sa
dal dobre čítať na obrazovke. Inak pri takomto porovnávaní často prídete na
množstvo chýb aj v pôvodnom dokumente, tak sa veľmi nečudujme. A v tomto okamžiku
si môžeme byť istí, že v 100 stranovom dokumente máme ešte asi 10-20 chýb, ktoré
sme prehliadli. Preto nastupuje človek, nazývam ho korektor, ktorý si tento
text prečíta - obvykle nemusí mať podklad a buď priamo opravuje chyby v texte
alebo ich vyznačí farbou, prípadne ich uloží do textového súboru a pošle nám
ho naspäť. My tieto opravy buď prijmeme alebo zamietneme. Dobrý text získame
vtedy, ak si ho prečítajú aspoň dvaja rôzni korektori. Ak si teraz niekto pomyslí,
že stačí, keď si to po sebe prečíta ešte dvakrát, tak je na omyle - tých chýb
nájde oveľa menej.
OCR je dobrá vec, ale obrázok niekedy tiež...
RoboV
