Tato stránka se rozšířila po Internetu, takže její již neaktuální kopie jsou na různých serverech, zde by měla být poslední verze s drobnými opravami podle přednášejícího INg. M.Viria, CSc.
Nejnovější verze stránky je na:
http://sweb.cz/fsokolovsky/cpp.zip. Pokud někdo na Internetu objevíte starší verzi, dejte
mi prosím vědět - její URL.
Programování v C++ - 1. část:

Buď pozdraven poutníku, kdo v dobrém přicházíš.
Pomoc hladovým
Můžete přispět na
humanitární pomoc lidem, kde je hladomor, pokud kliknete na reklamu sponzorů.
Tím, že kliknete, přispěje sponzor na dodávku potravin.
http://www.thehungersite.org/
Dále na odkaz DONATE FREE FOOD.
Můžete také zveřejnit tento server i na svých WWW stránkách. Děkuji.
Programování v C++ - 1. část:
Stažení této stránky pro lokální prohlížení (i s příklady)
v archivu ZIP (ze dne 7.1.2000) - časem jsou odstraňovány překlepy,
doplňováno podle připomínek čtenářů, dívejte se proto po aktuální verzi na http://www-troja.fjfi.cvut.cz/~sokolovs/CPP.HTM
Moje poznámka: Vlastní zkoumání jazyka C++,
když jsem byl ještě začátečník... Stáhněte si archiv.
Poznámka: Cílem této html stránky je podat základní "kurs"
o programování v C++, protože některá literatura je příliš drahá a také velice
rychle zestárne.
Poznámka: Informace a výklad je tedy veden podle přednášek
Programování v C++ na FJFI (to je Fakulta Jaderná a Fyzikálně Inženýrská - to
je zde, kde si nyní prohlížíte tuto WWW stránku), patřící pod ČVUT. Přednášky
přednáší ing. M.Virius, Csc.
Žádost: Pokud uvidíte jakoukoliv chybu, dejte mi prosím vědět.
Chybička totiž pravděpodobně vznikla přepisem prográmků do WWW stránky, na
přednášce se chyby vyskytují jen zřídka.
Poznámka: Ovšem žádný text se nevyrovná přednáškám Programování v C++
v Trojanově 13 a praktických ukázkách předváděných na počítači s možností
promítání obrazu na tabuli či stěnu.Ovšem předášky jsou nenahraditelné, jelikož
se zažije někdy i legrace, když počítač či projektor nepracuje, tak jak by
měl...
Doporučená literatura: Názvy literatury ani jména autorů - bez
záruky, formát: nakladatelství - autor - název díla
- Grada - ing.M.Virius, Csc.
- Objektové programování
- Kopp - Herout - Učebnice
jazyka C
- ??? - P.J.Plougher -
Standard Template Library (STL)
- Kopp - St.Racek - Objektově
orientované programování v C++
- Grada - ing. M.Virius, Csc.
- Pasti a propasti jazyka C++
- The C++ programming
language ADDISON, BJARNE STROVSRUF, WESLEY 1997, 2100 Kč
- C++ programovaci jazyk,
žlutá knížka, 699 Kč
- Programovací jazyk C, C++,
ing. M.Virius, Csc.
- Programujeme ve Visual C++
(objektvá knihovna MFL, o prostředí a základy programování)
- Visual C++ 5.0 (prostředí,
úvod)
- Herout, C++
Naopak nedoporučená literatura: Obsahuje totiž tolik chyb, že kdo se z ní bude učit, ...
Seznam další doporučené a nedoporučené literatury najdete na stránce přednášejícího Ing. Viria, CSc. na http://kmdec.fjfi.cvut.cz/~virius/liter.htm.
Obsah:
- Úvod -
překvapivě :-) a historie C++ (doporučuji si přečíst)
- Základní
program v C++ resp. C
- Program
na výpočet faktoriálu
- Demonstrační
program na použití operátorů ++,--
- Projekty
- Příklad
komplexních čísel - objektové řešení, povídání o objektech a přetěžování
objektů
- scanf,
printf
- Popis
jazyka C++
- Konstanty
- Typy
proměnných a operátory (operace s proměnnými), matematické funkce
- Rozdíl
mezi C a C++ v bloku
- Blok
- Podmíněný
příkaz, podmínky
- Podmíněný
výraz
- Pořadač
- Směr
operací a přiřazování
- Cykly
- Pole
- Větvení
programů - příkaz Switch
- Vkládání
instrukcí v Assembleru
- Příkaz return
- Výčtové
typy a normální typy
- Makra a
podmíněný překlad
- Ukazatele
- Adresová aritmetika - příklad kopírování obsahu
řetězců
- Vícerozměrná
pole
- Reálný mód v DOSu, paměťové modely
- Chráněný mód, typy ukazatelů, konverze
- Obrazová
paměť - videopaměť
- Práce s dynamickými proměnnými
- Objekty
a ukazatele
- Funkce
jako parametr funkce
- Rekurze
a nebezpečí
- Paměťové
třídy
- Return
- pokračování
- Reference
- Implicitní hodnoty parametrů
- Výpustka
- funkce s výpustkou
- Vytvoření
funkce v C, C++ pro Pascal
- Vytvoření
funkce v C, C++ pro Pascal v Borland C++ 3.1
- Parametry příkazové řádky
- Modifikátor
inline
- Používání
funkcí pro C v C++
- Funkce
- Enviropment
- proměnné DOSu
- Přerušení
a jeho obsluha
- Reference
- 2. část
Další (druhá část) této WWW stránky
Úvod, historie
jazyků C, C++:
Nelze se nezasmát :-) Programovací jazyk C se jmenuje C, protože před
ním byl programovací jazyk B (zkratka od B CPL - central programming language,
používán pro Unix).
Poznámka: C++ se označuje C++, protože je následovníkem jazyka C a
symbor ++ znamená operátor (viz dále), který znamená
následníka nebo další možnost (u celých čísel znamená zvětšení o jedničku).
Co tvoří dnešní jazyk C++?
- Jazyk C (včetně ukazatelů
a adresové aritmetiky)
- Reference
- Přetěžování funkcí
- Objektové typy
- Přetěžování operátorů
- Šablony
- Vyjímky
- Prostory jmen
- STL (Standard Template
Library)
- Dynamická identifikace
typů RTTI
1,2,3 = neobjektové C++
1 až 8 = dnešní C++
Šablony: Používají se, pokud naznáme předem typ, jako univerzální
konstrukce pro různé typy proměnných, ale pro stejný algoritmus (např. zásobník
- pro ukládání různých typů proměnných - vždy jsou operace totožné, pouze se
liší typem proměnné se kterou se pracuje; třídění - zde také můžeme
naprogramovat stejný algoritmus, který můžeme použít pro třídění různým typů
proměnných, kde je definován operátor porovnávání).
Vyjímky: Používájí se v případě, že je nějaká část programu (např.
funkce) přerušena nějakou chybou, takže je možné potom zadat, jak se bude na ní
reagovat resp. kam se má předat řízení, jelikož funkce se nemůže normálně
ukončit, ale musí dát vědět tomu, kdo ji zavolal, např. tím, že se tato vyjímka
nějak ošetří - někam se skočí.
Historie:
Asi roku 1972 navrhli Ritchie a T(h)omson jazyk C.
Ritchie + Kerningham - Programming language C
Roku 1990 - poprvé navržena norma ANSI C
C++ - poprvé navrhl a definoval Bjarne Stroustrup
Různé C FRONT 1, 1.1, 2.0, 2.1
Překladače od různých firem: Borland, MS (není MakroSoft, ale Microsoft),
Watcom, GNU
Borland - Turbo C++, pro Dos verze: 1.0, 2.0, 3.0, 3.1
Borland - Verze 3.1 je nejlepší verze C++ pro DOS
Borland - Další verze jsou pro Wokna (slušně řečeno MS Windows, kde
MS není MakroSoft), ale Microsoft - verze: 4.01, až 4.5, 5.0
MS verze: 2.0 je vlastně C, 7.0 je C++ (asi jako Borland 3.1), dále
jsou verze pro Wokna označená Visual C++ 1.0 (pro Windows 3.1),2.0 (už umí
přeložit i jako 32bit. aplikaci), ... 5.0 (pro Win95)
Watcom verze: 10.5 a 11, OPTIMA++, překlad pro různé platformy, DOS,
Win, OS2, i pro Novell, POWER++
Základní
program v C++ resp. C:
Poznámka: Hlavní program je funkce, která v DOSu vrací číslo, které
odpovídá chybovému kódu DOSu - proměnná DOSu ERRORLEVEL. Proto je dobré definovat
hlavní program jako funkci main() vracející chybový kód. Chybový kód se
zde vrací příkazem return, za kterým se napíše vracená hodnota. Lze
napsat i bez hodnoty za příkazem ruturn, v takovém případě pouze ukončí program
(pokud je příkaz return ve funkci main), ale nelze s určitostí říci jaký bude
chybový kód (většinou 0, ale nelze se na to spolehnout).
Varování a poznámka: Programovací jazyk C++ rozlišuje velká a malá
písmena. Přednášky jsou uskutečnovány na překladači Borland C++ 3.1, překladači
pro DOS. V jiných překladačích může být situace trochu odlišná. Takže, pokud
místo main() napíšete např. Main(), kompilátor ohlásí chybu, jako by funkce
neexistovala. Při startu programu se předá řízení proceduře main(). Procedure
main() smí být maximálně jedna. Aby program odstartovan, musí být právě jedna,
nesmí jich být tedy víc a musí existovat alespoň 1 funkce main(). Závorky ()
jsou důležité, neboť tak dáte překladači najevo, že definujete funkci a ne
pouze proměnnou.
Poznámka: Za většinou deklaracemi se píše středník. Na vyjímky Vás
upozorní tato WWW stránka nebo chyba při překladu nebo špatná funkčnost
programu.
Všeobecné poznámky - zdvojování \\: Dále se
nesmí šetřit znaky \, pokud je v názvu adresářové cesty, protože znak \ C++
bere jako speciální znak, takže je nutné ho zdvojit, potom bude brát \\
skutečně jako \. Doporučujeme si vyzkoušet při práci se soubory (viz dále),
když v adresářové cestě použijete místo \\ pouze jeden znak \ (častá chyby
začátečníků), abyste se vyvyrovali případných budoucích nadávek, proč ten
program nemůže najít adresář či soubor.
Poznámka: Dále je dobré nešetřit závorkami () např. u maker s
parametry (viz dále). Dále je dobré nešetřit znakem = při porovnávání (zde je
nutné psát ==), protože jedno = se používá pro přiřazení, == pro porovnávání
(je to někdy chyby těch, kteří znají Pascal, než si zvyknou na C++).
ZAKLADNI.CPP: Základní program v C++ resp.C
Popis základního programu ZAKLADNI.CPP:
- Příkaz #include
<iostream.h> (direktiva) slouží k načtení tzv.hlavičkového
souboru, abychom mohli používat některé funkce, které by jinak
kompilátor "neviděl" a hlásil by chybu. Význam je takový, že
kompilátor přečte a přeloží soubor zadaný v < > a tak lze
zpřístupnit část programu, která je v jiném souboru. Soubory s koncovkou h
jsou hlavičkové soubory. Ale příkazem include lze přidat k Vašemu programu
i těla funkcí. Hlavičkové soubory se hledají v adresáoi, který je nastaven
v Option - Directories - Include directories. Pokud zadáme #include
"jméno.h", potom se bude soubor jméno.h hledat v aktuálním
adresáři. Můžeme také zadat i soubor s jinou koncovkou, ten nám kompilátor
přeloží a budeme moci ve svém programu používat ty funkce, které jsou
definovány v tom daném souboru.
- Řádkou int main() definujeme
hlavní program, kam se předá řízení při startu programu. Musí vždy
existovat, pokud chceme program spustit (což zpravidla bychom si
přáli...). Ale může být maximálně jedna. int znamená typ proměnné
integer, která je v Pascalu (tedy 2B celočíselná proměnná se znaménkem v
rozsahu -32768 až 32767). Tedy hlavní program representovaný funkcí main()
bude vracet hodnotu int. unsigned char znamená proměnnou v rozsahu
0..255. char znamená proměnnou v rozsahu -128..127. Pokud
definujeme hlavní program jako void main(), potom se nebude vracet
nic, neboť void znamená prázdný výstup - tedy nic nevrací, je to tedy
obdoba procedur v Pascalu. Potom tedy nepoužijeme return, abychom vrátili
nějakou hodnotu. Pokud definujeme hlavní program jako unsigned char
main(), bude tedy možné vrátit hodnoty 0..255, takže hodnoty
odpovídající ERRORLEVEL v DOSu. main() se musí jmenovat ta funkce,
do které se předá řízení při startu. Nesmíme zapomenout za názvy funkcí a
procedur (), jinak by překladač předpokládal, že definujeme proměnnou
místo funkce. V C++ jsou všechno funkce, ikdyž nevrací nic. Říká se, že v
C++ jsou všechno deklarace: deklarace proměnných a typů, fukcí - ve
kterých jsou deklarace příkazů. Výjimku tvoří direktivy - např. #include.
Ale i to lze brát jako deklaraci...
- Znakem { chápeme
začátek těla funkce nebo složeného příkazu nebo bloku. Za to můžeme již
vložit jak deklaraci proměnných (ty jsou lokální (pokud se neřekne jinak)
a budou existovat v tomto bloku a zaniknou přechodem přes }, patřící k
dané {. Bloky {....} se mohou do sebe vkládat a je tedy rozumné, aby byl
stejný počet { jako }. { je obdobou begin v Pascalu, tam je také nutné
napsat ke každému begin také i end, což je zde znak }.
- cout je funkce,
která provádí přesměrovatelný výstup (do proudu) na standardní výstupní
zařízení (původně to je obrazovka). << je operátor, který se
používá pro vložení do výstupního proudu ve funkci cout. Píše se před
vším, co chceme vytisknout. Lze vytisknout všechny typy proměnných, pro
které je definován operátor << výstupu do proudu (standardně to jsou
řetězce, jednoduché proměnné, konstanty). Operátor << lze
předefinovat, takže můžete docílit výstupu proměnných, které se nedají
standardně zobrazit, protože pro ně nění definován tento operátor. Před
každou proměnnou je nutné psát operátor <<, který zde slouží také
jako oddělovač mezi parametry. Řetězec se zde v C++ zapisuje v uvozovkách
"smysluplný řetězec..." narozdíl od Pascalu. Symbol endl
vlastně znamená kód pro konec řádku, takže nastane odřádkování a návrat na
nový řádek. Bez endl by se psalo za poslední znak v místě kurzoru, tedy ve
stejném řádku, kde se přestalo.
- Příkaz return, jak
jsme si už řekli, se používá k ukončení bloku (návratu z bloku) a případně
vrácení hodnoty. Pokud zapomeneme na return, potom nás většinou překladač
varuje, ale program lze přeložit a blok se automaticky ukončí, když se
narazí na odpovídající znak }.
- Znakem } chápeme
konec těla funkce nebo složeného příkazu nebo bloku.
Program na
výpočet faktoriálu:
Nyní prográmek zkomplikujeme a naprogramujeme výpočet faktorialu z celého
přirozeného čísla.
FAKTORIA.CPP: Zde je program na výpočet
faktoriálu, jak jsem slíbil.
Popis programu na výpočet faktoriálu FAKTORIA.CPP:
- #include
<iostream.h> nám umožní použití funkcí vstupu a výstupu, protože
se natáhne hlavičkový soubor iostream.h, s hlavičkami funkcí, takže je
bude již překladač "vidět". Soubory *.h jsou obvykle v
podadresáři INCLUDE v tom adresáři, kde je překladač jazyka C.
- unsigned long fak(int n)
znamená, že jsme definovali funkci se jménem fak, vracející proměnnou typu
unsigned long (0...4294967295 - zabírá 4B - je tedy bez znaménka) a funkce
má jeden (vstupní) parametr - proměnná typu int , která se jmenuje n.
- Znak { je pro začátek bloku
- těla funkce a znak } je konec bloku - těla funkce.
- unsigned long s=1;
znamená deklaraci proměnné s, která je typu unsigned long a do níž se
přiřadí hodnota 1. Proměnná bude existovat v tomto bloku - v této funkci.
Pro výskoku z bloku již přestane existovat, takže již nebude
"vidět".
- int i=1; Deklarace
proměnné i typu int, do které se přiřadí hodnota 1. Takto lze snadno
spojit deklaraci a přiřazení. Máme potom jistotu, že v té proměnné máme
nějakou rozumnou hodnutu, že např. nebudeme násobit nulu (to by nám vadilo
v případě proměnné s).
- while (i<=n) je
příkaz cyklu (který také známe z Pascalu, pouze zde chybí klíčové slovo
"do"), který se opakuje - provádí se blok - tělo cyklu, pokud je
proměnná splněna. Pokud přestane být podmínka splněna, tělo se přeskočí a
pokračuje se na další příkaz za tělem cyklu. Může vzniknout nekonečný
cyklus, např. v případě, že napíšeme: while (1) {}. Další varování: Pokud
napíšete while(podmínka); {nějaké příkazy}, tak Vás překladač ani nebude
varovat. Co se stane? Nejspíš nekonečný cyklus, pokud je tedy podmína
časově neměnná a pořád je splněna. Důvod: Středník za while(podmína) se
bere jako prázdný příkaz, který se provádí v tomto cyklu. Pokud tedy za
něco napíšete středník, znamená to, že je to příkaz. Pokud tedy před tím
nebylo nic rozumného, je to potom prázdný příkaz. (Může te se podívat
např. do Turbo-Debuggeru, jak se prázdný příkaz přeloží do Assembleru -
většinou to není žádná instrukce, tedy nedělá vůbec nic.) Prázdný příkaz
tedy nedělá nic, takže podmínka většinou bude opět splněna, protože byla splněna
i tentokrát, tak bude splněna asi i nadále. A blok {} příkazů a deklarací
může být skoro kdekoliv, takže překladač nevidí žádnou chybu ani žádný
problém, před kterým by Vás měl varovat.
- s = s*i; Vynásobí
proměnné s a i a výsledek uloží do s.
- i++; Zvýší proměnnou
i o 1. Má význam, že vrátí následovníka proměnné i, tedy následovníkem 1
je 2, následovníkem programovacího jazyka C je C++, ale všechno, co je za
něčím, nemusí být následovník (např. nelze říci, že C je následovníkem
jazyka B, ale C je za jazykem B - v historickém vývoji). Příklad na použití operátorů ++ pro zvýšení proměnné a
-- pro snížení demonstruje TEST.CPP
- {return s;} Schválně
je příkaz return zapsán v bloku. Na funkčnosti se to neprojeví. Každý
příkaz si můžeme dát do složených závorek. Vrací tedy výstupní funkci a
ukončuje program.
- int main() Definice
hlavního programu. Této funkci se předá řízení při startu programu.
- cout <<
"Ahoj\nlidi\nVysledek - faktorial je " << fak(5) <<
endl; Vypise na obrazovku "Ahoj". Potom je zde v retezci
obrácené lomítko \, které má speciální význam (viz
poznámka o zdvojování \\ u jmen souborů)
- return 0; Vrací
chybový kód a ukončuje program - zde je totiž return v hlavním programu -
funkci main().
Demonstrační program na použití
operátorů ++,--:
Příklad
na použití operátorů ++ pro zvýšení proměnné a -- pro snížení demonstruje
TEST.CPP
Popis programu TEST.CPP:
- int a; Deklarace
proměnné a typu int
- a = 1234; A
přiřadíme do ní hodnotu. Všechno lze dát jako 1 příkaz: int a = 1234;,
který proměnnou zároveň definuje (vytvoří) a současně do ní hned přiřadí
uvedenou hodnotu.
- cout << "2.
vystup: " << ++a << endl; /*vytiskne se hodnota 1235 -
nejdrive se zvysi promenna a potom se vytiskne*/ Jednak vytiskne
uvedený řetězec. Operátor ++ slouží ke zvýšení obsahu proměnné - zde a.
Jak je zde napsáno v komentáři - začátek je /* a konec komentáře je dán
znaky */, se zde (tj. v případě ++a) proměnná nejdříve zvýší a vrátí zvýšenou
hodnotu, která se již vytiskne. A tedy bude o 1 větší, než byl předtím.
- cout << "4.
vystup: " << a++ << endl; /*vytiskne se hodnota 1235 -
nejdrive se vytiskne a potom se teprve zvysi o 1*/ Opět je zde text v
komentáři (který se nepřekládá a ignoruje se překladačem), začínající /* a
končící */. Zde se nejdříve vytiskne hodnota proměnné (tedy před zvýšením)
a potom se proměnná zvýší o 1.
Projekty:
Uvedeme si, co to je projekt. Předem se omlouvám, pokud by definice
nevystihovala to, co skutečně projekt je. Pokusím se to naznačit v následující
poznámce.
Definice: Projekt je určitá skupina menších programků, které
dávají dohromady jeden velký program.
Poznámka: Již mohou být přeloženy nebo se přeloží všechny najednou.
Situace se s výhodou používá u velkých programů, na kterém pracuje několik
programátorů, kteří se dohodnou na nějakém rozhraní a každý naprogramuje
určitou část programu (např. je to soubor, který je překladačem přeložen do
souboru s koncovkou obj) a potom (po naprogramování hlavního programu), v C++
je to funkce main() se linkerem spojí vechny soubory do jednoho spustitelného
programu (s koncovkou exe nebo com).
Zadání projektu: V menu Project (verze Borland C++ 3.1) zvolíme
položku Open project... Potom v dialogu zadáme nebo vybereme jméno projektu (s
koncovkou prj), pokud soubor neexistuje, potom se vytvoří. V stejném menu
položkou Close project můžeme project zavřít a položkou Add item... můžeme
vybrat soubory, patřící do našeho projektu.
Poznámka: Pokud teď budeme něco překládat, potom se bude překládat
projekt. V projektu mohou být již přeložené programy *.obj (např. z C, C++,
Assembleru). Aby to všechno šlo spojit linkerem, musí být právě jedna procedura
main(). Pozor! Jak jsme již zdůraznili, C++ rozlišuje malá a velká písmena, tak
proto se možná stane, že některou funkci linker nenalezne, protože jsou
rozlišovány malé a velké písmena. Kromě toho C++ komolí jména všech funkcí,
takže někdy používat něco co vytvořilo C++ je dosti obtížné, ale prakticky se
ukazuje, že to někdy jde... Linker v C++ asi bez problémů sestaví obj soubory,
které vytvořil kompilátor C++.
Výhody projektů: Každou část programu lze přeložit zvlášť, v jiný
okamžik, jiným programátorem. Pokud není k dispozici k obj souboru jeho
zdrojový program, měl by být k dispozici alespň hlavičkový soubor, obsahující
ty funkce resp. i proměnné, typy apod., co lze používat v ostatních programech.
V takovém případě do objektu vložíte obj soubor a program, ve kterém budete
chtít používat služby obj souboru. Do toho programu pomocí include načtete z
hlavičkového souboru hlavičky funkcí, pokud je po vložení do projektu linker
neuvidí a bude hlásit chyby. Použití projektů všeobecně urychluje překlad,
protože se některé části programu již nemusí překládat.
Nevýhody projektů: Někdy hlásí zbytečné chyby, které by se nehlásily,
kdyby se všechno dalo do jediného souboru (v tomto případě lze dost dobře
zjistit, co je deklarováno dvakrát, než prohledávání několika souborů -
doporučuji používat program Grep pro vyhledávání textových částech ve zvolených
souborech). Toto platí hlavně v případě sestavování, pokud linker najde něco
dvakrát. U projektu se zastavíme ještě někdy podrobně, ukážeme si to na
příkladech. Ale zatím si musíme vysvět něco jiného.
Příklad
komplexních čísel - objektové řešení
Poznámka: Zatím to nemá znamenat výuku objektového programování v
C++, ale následující program ma něco říci o možnostech C++ a výhodách (resp.
navýhodách) používání objektů, které budou patrné z programu.
Poznámka: Práce s komplexními čísly je možné naprogramovat i
neobjektově, je možné naprogramovat i v Pascalu, zde ovšem přicházíme již o
možnost psát práci s komplexními čísly pomocí operací +,-,*,/ jako v
matematice. C++ již umožňuje tzv. přetížení operátorů, mezi nimiž patří
+,-,*,/ (ale i jiné), což umožňuje přiřadit novou funkci, která bude
"počítat" sčítání, odčítání, násobení, dělení.
Poznámka: Nyní budu doslovně citovat v přednášky v C++ (ing.
M.Virius, CSc.): "Možnost přetížení operátorů může zdrojový text programu
zpřehlednit, ale také může znepřehlednit (pokud se předefinuje operátor + např.
pro násobení, - pro sčítání apod)."
Poznámka: Lze předefinovat operátor výstupu do výstupního proudu
>> (používá se u cout), ale také nám zatím neznámý operátor << pro
čtení ze vstupního proudu (používá se u cin - čtení z přesměrovatelného
vstupu a uložení do zadané proměnné). Tímto způsobem ukážeme předefinování
těchto operátorů pro práci s komplexními čísly.
Práce s komplexními čísly - program z přednášky
C++ obohacený o přetíženížení operátorů pro vstup a výstup ze
vstupního/výstupního proudu. (Něco jako jednotka v Pascalu.)
Práce se zlomky, obsahuje také přetížené operátory,
tento soubor již na přednášce nebyl a je moje dílko, takže se za případné chyby
zlobte na mně. (Něco jako jednotka v Pascalu.)
Použití práce s komplexními čísly a zlomky. Hlavní
program, který to všechno používá.
Nezapoměňte si stáhnout hlavičkové soubory ZLOMKY.H
a COMPLEX.H !!! Bez nich prográmek úspěšně
nepřeložíte.
Moje poznámka - jak to přeložit? V C++ někdy bývá úspěšně přeložený
program zázrak. Proto nelze s jistotou říci, že po dodržení tohoto postupu a
podmínek, program půjde přeložit. Ukážeme si to v Borland C++ 3.1:
- Otevřít projekt (Menu -
Project - Open Project...) a pojmenovat, např. COMPLEX.PRJ.
- Pokud se neotevře okno
Project, použijte Windows - Project
- Klávesou Insert (pokud
jsme v okně Project) vložíte jednotlivé části projektu. Zadejte ZLOMKY.CPP, COMPLEX.CPP,
POUZITI.CPP. Hlavičkové soubory *.H se
nezadávají.
- A nyní to již zkuste
přeložit a spustit. V případě chyby zkuste Compile - Build all a potom mi
napište mail.
Popis programu:
POUZITI.CPP je hlavní program (tedy obsahuje funkci main()), používá práci s
komplexními čísly COMPLEX.CPP (to je něco jako jednotka - unit v Pascalu, může
být přeložena do complex.obj souboru a přiložen hlavičkový soubor complex.h
nebo kompletní zdrojový text všetně hlaviček i implementace funkcí a všech
dat). COMPLEX.CPP pracuje se zlomky, používá tedy ZLOMKY.CPP (u zde bychom mohli
přeložit do ZLOMKY.OBJ a dodat pouze hlavičkový soubor ZLOMKY.H, takže nemusíme
dát kompletní zdrojový text včetně implementace těl funkcí a dat, ostatní
programátoři by tomu stejně nerozuměli :-) nebo by se snažili tomu porozumět).
Další povídání o objektech bude v kapitole Objektově orientované
programování. Zde se blíže seznámíme s práci, deklarací objektů (vlastně je to
vidět z uvedených příkladů). Lze vlastně použít struct nebo class
Použití přistupových práv:
soukromé - private - jako soukromé se většinou definují
atributy (tedy data objektu - třídy) a některé metody, které je zakázáno
používat mimo objekt. Soukromé je všechno to, k čemu je zakázán přístup z
vnějšku.
přátelské - friend - specifikuje název funkce, která může
pracovat se soukromými prvky objektu.
veřejné - public - lze používat i z vnějšku. Vhodné je to u
metod, aby se daly použít i z jiných částí programů. Nedoporučuje se definovat
atributy jako veřejné, protože ty data může kdokoliv kdykoliv měnit. Pro práci
s atributy - daty třídy jsou určeny metody, aby kontrolovaly přístup a změnu
svých dat, takto lze zabránit nechtěnné změně dat např. na nesmyslnou hodnotu.
Konstruktor a destruktor
konstruktor se vždy jmenuje stejně jako název objektu a může mít parametry,
nic nevrací
destuktor se vždy jmenuje ~jmeno kde jmeno je jméno objektu, nesmí mít
parametry, nic nevrací
konstruktor se volá deklarací příslušného objektu, stejně jako u deklarace
normální proměnné - zde se také volá standartní konstruktor, který vytvoří
proměnnou příp. nastaví nějakou hodnotu
destruktor se volá při zániku instance
pokud se u funkce neuvede žádný typ proměnné, pouze její název, předpokládá
překladač proměnnou typu int
Tabulka příkazů Pascal, C++:
|
Pascal:
|
C++:
|
Význam příkazu:
|
|
write;writeln
|
cout;printf
|
Tisk na obrazovku (standartní výstupní zařízení)
|
|
read;readln
|
cin;scanf
|
Čtení z klávesnice (standartní vstupní zařízení)
|
begin příkaz resp. příkazyend; |
{ příkaz resp. příkazy} |
Složený příkaz, který obsahuje 1 nebo více příkazů, resp.
blok příkazů
|
|
exit
|
return
|
Ukončení aktuálního bloku (v hlavním programu znamená
konec programu)
|
|
halt
|
exit
|
Ukončení programu - vždy
|
if podmínka then příkaz1else příkaz2 |
if (podmínka)příkaz1 else příkaz2 |
Pokud je splněna podmínka, provede se příkaz1, jinak
příkaz2
|
case výraz of k1: příkaz1 k2: příkaz2 kn: příkazn else příkaz0 end; |
switch (výraz) { case k1: {příkaz1;break;} case k2: {příkaz2;break;} case kn: {příkazn;break;} default: {příkaz0;break;}} |
Větvení podle uvedených možností k1,k2,...,kn. V případě,
že výraz nabyde jedné z těchto možností, potom se provede příkaz za
dvojtečkou. Pokud výraz nenabyde žádné hodnoty, potom, pokud je uvedeno else
resp. default, potom se provede následující příkaz za else resp. default
|
while podmínka do begin příkazy end; |
while (podmínka) { příkazy } |
jedná se cyklus, tj. opakují se příkazy mezi begin a end
resp mezi { a }, tak dlouho, dokud je splněna podmínka. Ti, kteří znají
Pascal, pro ty to není nic nového.
|
Dále existuje cyklus do { příkazy } while (podmínka),
který by při znegované podmínce odpovídat cyklu repeat příkazy end;
Tento cyklus (příkazy mezi repeat a until) se v Pascalu prováděl dokud není
splněna podmínka, ale cykluv v C++ do while se provádí při splněné podmínce,
tak dlouho, dokud je podmínka splněna.
Poznámka: Pozor! Nezapomeňte v příkazu větvení v C++ příkaz break,
který je velmi důležitý. Proč? Zkuste si to sami vyzkoušet, co se stane... To
si pak lépe zapamatujete a vyvarujete se případné chyby, než když si teď budete
snažit zapamatovat důvod. V případě, že si nebudete vědět rady, můžete mi
poslat E-MAIL a já Vám zpět pošlu vysvětlení.
Poznámka: Ti, co navštěvovali na FJFI kurs Pascalu, jistě umí vyvolat
nápovědu (a tak si mohou snadno obejít i bez této WWW stránky), naprogramovat
průměrně složitý program, odhadnout jeho složitost (časovou i paměťovou - viz
Základy algoritmizace - ing. M.Virius, CSc.) a jistě číst anglicky psaný help v
Turbo Vision.
printf,
scanf
Příkaz printf se používá pro výstup dat na standartní výstupní zařízení
(monitor). Přikaz scanf se používá pro vstup dat ze standartního vstupního
zařízení (klávesnice). Jako data může být u printf i řetězec, který se má
vytisknout, u obou (printf i scanf) může být proměnná, v tom případě s vypíše
její obsah resp. do ní se uloží to co se přečte z klávesnice. Funkce fungují
skoro stejně jako write a read v Pascalu, s tím rozdílem, že zde navíc může být
tzv. formátovací řetězec.
Ve formátovacím řetězci může být (ten se zapisuje do "....."),
parametry se oddělují čárkou, tak jak bychom to měli znát z Pascalu.
- %d - celé číslo v
desítkové soustavě (před znak d lze napsat číslo, odpovídající počtu míst)
- %f - reálné číslo (float)
- výpis s pevnou plovoucí čárkou
- %e - reálné číslo ve tvaru
3,21e+1 - exponenciální tvar
- %E - reálné číslo ve tvaru
3,21E+1 - exponenciální tvar (liší se výpisem E místo e)
- %g - vybírá si z možností
mezi exponenciálním tvarem a tvarem s pevnou plovoucí čárkou
- %o - celé číslo v
osmičkové soustavě
- %X %x - celé číslo v
16tkové soustavě
- %u - číslo bez znaménka
- %c - znak
- %f - proměnná float
- %lf - proměnná longfloat
- %s - řetězec
Odřádkování - vložíme \n - nový řádek
Upozorňujeme, že se zde používá výpistka (viz dále), takže počet ani typ
parametrů se nekontroluje, což můžeme mít nepředvídatelné důsledky pokud
programátor neví co chce nebo pokud napíše špatný typ (jde o to, že při zadání
%f počítač očekává název proměnné typu double, ale pokud zadáme např.
celočíselnou, bude buď část paměti přepsána (u scanf) nebo vypsán nesmysl (u
printf)
Poznámka: Pokud zvolíme v option a zaškrtneme políčko precompile
headers, potom si kompilátor vytvoří soubory *.SYM, do které si (jak už
anglický název napovídá) ukládá hlavičky funkcí, což má výhodu, že to urychlí
překlad, ale na druhou stranu to zabírá místo na disku. Ukládá se to adresáře
nastaveného jako output directory.
Popis jazyka C++:
Překlad programu: Překlad programu probíhá pobíhá zleva doprava na
řádku, potom se skočí na další řádek až do konce souboru, popř. se načítají
jiné soubory, na které se použije kompilátor stejný postup, pokud se jedná o
zdrový text nebo hlavičkový soubor.
Poznámka - token: Token je položka, na které se kompilátor snaží
rozložit text. Vstupem je tedy soubor s textem, ze kterého se za normálních
okolností odstaní přebytečné mezery (pokud to není řetězec) a hledá se vždy
nejdelší položka, která má smysl při postupu zleva doprava (tak většina
programátorů také píše a zezhora dolů).
Druhy token - položek v C++:
- identifikátor
- konstanta
- řetězec
- klíčové slovo
- komentář
- operátor
Význám jednotlivých názvů by měl čtenář znát z Pascalu nebo z jiného
programovacího jazyka.
Pod identifikátorem může být jméno procedury resp. funkce (v C++ jsou stejně
všechno funkce) nebo jméno proměnné či sloužitější datové struktury.
Konstanta může být číselná (celá, reálná, potom v různých soustavách -
desítková, šestnáctková a osmičková). A co dvojková? (To jsem se dovolil
zeptat...) Přednášející mi řekl, že C++ standartně neumožňuje dvojkovou
soustavu, ale že bych si to musel naprogramovat, k čemu se snad dostanu a
napíšu to zde, pokud se to ovšem naučím...
Řetězec je vlastně konstanta, je to ovšem spíše pole znaků a v C++ se
řetězec vždy kontvertuje na adresu ukazující na 1. prvek. Narozdíl od Pascalu
je zde vyjímka: První znak v řetězci neznamená jeho délku, ale 1. znak je
skutečně první znak řetězce. Řetězec se ukončuje znakem s ASCII kódem 0. Pokud
normálně řetězce zapisujeme - při vstupu a výstupu a ve většině přiřazovacích
příkazů, počítač ji za nás nakonec většinou přidá, pokud je mu jasné, jak je
řetězec dlouhý.
Klíčové slovo se většinou v Borland C++ zobrazuje bíle, aby se odlišilo od
jiných tokens. Klíčovým slovem je standartní příkaz v C resp. C++. Například
větvení, cyklus, podmínka, apod.
Komentář se zapisuje za znaky // V tomto případě se bere komentář až do
konce řádky. Nebo druhý druh je /* který platí až do */
Operátor je většinou něco jako matematická operace (ne fuknce), např. matematické:
+ - * / ( ) pro porovnávání: < > <= >= != == = zvýšení resp.
snížení o 1: ++ -- kombinace přičítání, odčítání, násobení a dělení, pokud je
výstup a 1. operand stejná proměnná: += -= *= /= a další speciální např. při
práci s objekty. Některé operátory lze přetížit a předefinovat jejich význam
pro svůj vlastní typ. Tak je možné zapsat sčítání komplexních čísel pomocí
operátoru +, jak jsme si na začátku ukázali v příkladu komplexních čísel.
Operátory + - mohou být binární (dva operátory) - při sčítání resp.
odčítání nebo unární - jako znaménko čísla.
V C++ je vlastně program posloupnost deklarací. Neboť i volání funkce je
vlastně deklarace, která se přeloží jako skok nebo volání přerušení.
Konstanty:
Číslo v desítkové soustavě se zapisuje zcela normálně a přirozeně: 123,
-123, +123, 5.123, 5E+11, 5e+11
Číslo v šestnáctkové soustavě se zapisuje jako 0xčíslo, kde číslo se skládá
z číslic 0123456789ABCDEF
Číslo v osmičkové soustavě se zapisuje jako 0číslo, což může u začátečníků
být docela problematické, neboť se to dá splést s číslem v desítkové soustavě.
Pouze pokud na začátku uvedeme 0číslo, bere se to jako v osmičkové soustavě
Číslo 0.125 je bráno jako číslo v desítkové soustavě (ne v osmičkové - to je
vyjímka) neboť si nedokážu představit blázna, který by si přál počítat v
osmičkové resp. šestnáctkové soustavě s desetinnými čísly.
Konstanty mohou být podle délky těchto typů:
- int
- unsigned
- long
- unsigned long
- short
- unsigned
V případě jiné konstanty se převádí konstanta na 1 z těchto 6 proěnných v
případě čísla. V případě řetězce či znaku zůstane řetězec řetězcem a znak
znakem.
Někdy je nutné předepsat, zda se má číslo brát jako určitý typ: 0U - znamená
0 jako unsigned, 0L znamená long a 0LU unsigned long
Znak se zapisuje 'a'
Řetězec se zapisuje "text"
Speciální ascii znak lze zapsat:
- "\OOO" kde OOO
je číslo v ASCII kódu v osmičkové soustavě
- "\xhh" kde hh
je číslo v ASCII kódu v šestnátkové soustavě
- \n - návrat na nový řádek
- odpovídá #13 v Pascalu - vloží se tedy znak s ASCII kódem 13
- \t - tabulátor
- \v - vertikální tabelátor
- \r - návrat na začátek
řádku bez odřádkování
- \a - zvonek
- \\ = \ takto se
implicitně v řetězci zapíše znak \, tj. je nutné zdvojovat \\
- \" = " takto se
implicitně zapíší uvozovky "
- \' = ' takto se
implicitně zapíše apostrof '
Operace,
proměnné:
a&b bitová operace and - logický součin
a|b bitová operace or - logický součet
a^b bitová operace xor - nonekvivalence
~a bitová negace
a<<1 bitový posun o 1 bit doleva (číslo určuje o kolik bitů se
číslo posune)
a>>1 bitový posun o 1 bit doprava (číslo určuje o kolik bitů se
číslo posune)
! logická negace: !a - pokud je proměnná nenulová, vrací nulu a pokud
a je nulová, vrací 1(v Pascalu byla proměnná Bolean, která mohla mít pouze
hodnoty 0 a 1, ale ostatní hodnoty byly nepřístupné, zde v C++ je i 2,3
-jakákoliv nenulová hodnota brána jako logická 1)
&& logická konjunkce (and) - logický součin
|| logické or - logický součet
Poznámka: Nezaměňovat || s | a && s |. Zatímco || a
&& sjou logické or a and (použití v podmínce), | a & jsou bitové or
a and (práce s více bity jako čísly v jedné proměnné - např. maskování,
analogické instrukcím OR a AND v Assembleru).
% operace modulo (viz mod v Pascalu), tedy zbytek po celočíselném
dělení
/ operace dělení (stejné jako v Pascalu), číslo se zaokrouhluje
(pokud je použito pro celočíselné proměnné je to analogické div v Pascalu)
+ - * ( ) normální sčítání, odčítání (binární se dvěmy proměnnými se
znakem uprostřed - vše normální) nebo znaménko číselné proměnné (unární - před
proměnnou), * je vždy násobení (asi nemá logický smysl unární *???) a je vždy
binární, / je dělení (také asi nemá smysl unární /???)
Reálné proměnné:float (4B) <= double (8B) <= long double (10B)
Rozsahy proměnných záleží na OS a verzi programovacího jazyka C, C++. doble =
long float
Přetypování: Jedná se o umělou změnu typu proměnných. Normálně se
provádějí automatické konverze proměnných v přiřazení, pokud jsou názvy
proměnných různých typů, ale někdy není možná. Pokud ovšem nutně chceme říci,
že proměnná x musí být nutně typu int, zapíšeme (int)x nebo int(x) (důvodem
může být např. chybná funkce programu nebo chyba při programu).
Rozsahy jednotlivých proměnných jsou:
shord <= int <= long
unsignedshor <= unsigned <= unsigned int
Znaková proměnná se deklaruje char, unsigned char, signed char, kde unsigned
char je znak bez znaménka 0..255 a signed char je znak se znaménkem -128..+127
Nezapomněl jsem se zeptat, jaký logický smysl májí znaménkové a neznaménkové
znaky. Bylo mi řečeno, že C++ chce uživateli umožnit využít všech schopností
operačního systému, takže když to umožňuje operační systém, C++ nechce
uživatele o tuto možnost obírat a tedy to záleží jen na uživateli, co s tím
bude dělat. A ješti jsem byl varován, že se s tím dá nadělat pěkný nepořádek...
Rozsahy jednotlivých proměnných int a short závisí na DOSu a zda používáme
16-ti resp. 32-ti bitový překladač C++. Na 16-ti bit. v normálním DOSu je int =
short -32767 .. +32767 u znaménkové signed int a 0..65535 u neznaménkového
unsigned int. V případě long celočíselných 32-ti bitových je rozsah -2mld ..
+2mld resp. 0 .. 4mld, mld jsou miliardy.
Operátory: Zopakujeme si: < (menší) > (větší) <= (menší nebo
rovno) >= (větší nebo rovno) = (přiřazení) == (testování rovnosti) !=
(nerovnost), + (sčítání nebo znaménko čísla), - (odčítání nebo znaménko čísla),
* (násobení), / (dělení), && (logické and), || (logické or), ! (logická
negace). Existuje prý až 55 operátorů s 16 různými prioritami. Pro ty, kteří
neznají jejich prioritu, je lepší, když budete používat závorky () - ty mají
nejvyšší a tedy mají přednost před ostatními. Proto se závorkami nešetřete.
Konverze: Pokud uvedeme různé proměnné, hledá se (pokud je to ovšem
logické) společný typ. char->int, short->int nebo unsigned. Po převedení
se objevují jen typy proměnných: int, unsigned, long, unsigned long, float,
double, long doule. Vše to jsou číselné proměnné, rozsahy najdete počet Bytů,
které zabírají v paměti, najdete v nápovědě, protože se to liší verzí
překladače a také OS, pod kterým máte C, C++. Výčtové typy a bitové pole se
také konvertují na celočíselné proměnné (int - bez záruky, záleží to na verzi a
OS).
int -1 se v DOSu (BC 3.1) bere jako 16-ti bitové a zapíše se jako FFFFH
long -1 se zapíše jako FFFFFFFFH
Pozor: Pokud je to jen možné, je dobré spolu nemíchat znaménkové a
neznaménkové znaky. Pozor máme definované funkce void f(char) a void f(int).
Pokud napíšeme f(c) (kde c je znak), volá se funkce f(char), ale pokud napíšeme
f(+c), volá se potom druhá funkce f(int).
Rozdíly u znakových proměnných mezi C a C++: Konstanta - znak např.
'č' se v C bere jako int (C nejspíš char nezná), ale v C++ se bere skutečně
jako char. Z toho vyplývá nebezpečí - viz další poznámka.
Poznámka: Funkce getchar() z hlavičkového souboru <stdio.h>
vrací int. To představuje někdy nebezpečí, pokud ukládáme výstup do proměnné
jiného typu. Podobně i všechny funkce v C++, které provádějí čtení znaku, vrací
int!
Matematické funkce: <math.h> Informace o funkcích lze najít v
nápovědě.
- sin(radiány)
(sinus)
- cos(radiány)
(kosinus)
- atan(x)
(arcustangens)
- log(x)
(přirozený logaritmus)
- log10(x)
(desítkový logaritmus - o základu 10)
- sqrt(x)
(druhá odmocnina)
- atan2(x,y),
která vrací úhel odpovídající podílu x/y, obsahuje tedy dva vstupní
parametry.
- atanl(long double
x) také vrací jako atan arcustangens, tahleta funkce atanl však
vrací long double 10B narozdíl od atan
- fabs(float x)
- znamená float abs - tedy absolutní hodnota pro čísla floating point
(čísla s pohyblivou řádovou čárkou), zatímco:
- abs(int x)
je pro celočíselné proměnné (int, unsigned int, char, unsigned char,...)
- fmod(dělenec,dělitel)
je jakousi obdobou Pascalovského operátoru mod, C++ operátoru %, tedy
zbytek po dělení dvou čísel, zobecněný i pro reálné čísla - floating point
čísla.
- pow(základ,mocnina)
vrací mocninu základu umocněný na exponent - mocninu a výsledek vrací jako
normální funkce.
- atof
provádí konverzi ze znakového řetězce do float. Zkratka vystihuje činnost
příkazu, proto zde nebude uvádět všechny možnosti (kompilátor resp.
nápověda Vás upozorní o případném nesmyslném převodu). Vysvětlení: a
znamená alfanumeric (tedy ten řetězec), to je anglicky do a f
je float.
- atol
analogicky provádí konverzi z řetězce do long double
- ltoa
analogicky provádí konverzi long double do řetězce (není to zase tak těžké
to pochopit...?)
Demonstarční prográmek pracující s funkcemi.
Poznámka pro studenty FJFI - ČVUT:
V Trojance na síti (pro začátečníky, kteří by si přáli studovat na FJFI
uvádím, že je to server katedry matematiky) jsou příklady všeobecně přístupné
všem, kteří mají na serveru katedry matematiky uživatelské konto. Ing. M.
Virius zde má veřejně přístupné příklady programů v C++ a v Pascalu. Prvácí,
kteří mohou být v Trojance na síti maximálně 10 minut (toť nové opatření
katedry matematiky, aby prváci netrávili čas na počítači a místo toho se
věnovali matematice) uvítají radu, jak se globálně napíchnout - tedy připojit
na server katedry matematiky a tak si prohlédnout příklady v C++ resp. Pascalu:
Server katedry matematiky: ftp://tjn.fjfi.cvut.cz
Username: jméno.prvaci. resp. jméno.studenti. nezapomínejte tečku na konci!
Bez ní budete jako odpojeni od serveru katedry matematiky.
Password: vaše heslo
Přiřadí vám implicitně jako pracovní adresář Váš home adresář, který máte na
katedře matematiky.
Potom budete asi dlouho hledat adresář přednášejícího ing. M. Virius, CSc.,
protože často se přemisťuje, úpravami na serveru.
Podle nové informace by to mělo být asi zde: KM1\DATA:\HOME\M64\VIR\VYUKA.
Po nalogování na tjn.fjfi.cvut.cz se ocitnete asi někde v adresáři
KM1\DATA:\nějaký adresář... V případě lokálního přilogování můžete použít
příkaz map. Jinak pomocí FTP se tam taky snad nějak dostanete.
Rozdíly mezi C,
C++:
Uvnitř bloku C nepokládá deklaraci za příkaz.
{ deklarace;
příkazy;
}
V C++ je deklarace = příkaz. Lze tedy psát skoro libovolně, deklarace mezi
příkazy, pouze musí být zachováno pravidlo: Nejdřív deklarovat, potom
použít. Překladač postupuje naprosto logicky - tedy zezhora dolů. To
snad není neobvyklé...? Většina programátorů píše program také zezhora dolů.
Další pravidlo zní: Deklarovat proměnnou až když ji použiju.
Respektovaní tohoto pravidla zabrání nechtěnému použití před svou deklarací.
Proměnná je známe ve svém bloku { } od místa deklarace dolů. Jak jsme již
upozornili, přechodem před } toho bloku, ve kterém je definovaná, proměnná
přestane existovat. Proměnné typu static se nezničí při výskoku z
bloku ani při přechodu }.
Napis N("Ahoj"); v tomto případě se vytvoří proměnná N typu Napis
a zavolá se konstruktor třídy Napis (nebo se použije standartní, pokud takový
neexistuje) a inicializuje se. Udělají se případné operace s řetězcem, to
záleží na implementaci konstruktoru třídy Napis.
if (x>0)
int i;
else
double i;
!!!Pozór!!!V tomto případě se vytvoří proměnná (v našem případě
"i") typu i různého typu podle hodnoty jiné proměnné (v našem případě
"x"). Proměnná "i" bude (jak jsme řekli) existovat od své
deklarace až dokonce do konce bloku. Ovšem pozor, zkuste si to přeložit a zjistíte,
že to nefunguje tak jak bychom si přáli... Neboť tento zápis je ekvivalentní
zápisu:
if (x>0)
{int i;}else
{double i;}
Otázka - proč? Z druhého zápisu je zřejmé, proč to tak je. Proměnná
přestane existovat přechodem přes } v tom bloku, ve kterém je definovaná.
Vlastně mě nenapadá, jak zařídit, aby se deklarovala proměnná různého typu
podle hodnoty nějaké proměnné, jejíž hodnota není známa v době překladu. Je to
tak dobře proto, že překladač neví jakého typu by byla a tedy by za podmínkou
nemohl rozhodnout, jakého je proměnná typu a nevěděl by, jak to přeložit,
protože pro každý typ proměnné vypadá překlad trochu jinak.
Nesmyslné příkazy: Všechno, za čím se napíše středník je příkaz. 3 je
číslo, pokud se ovšem za ní napíše středník 3; je to příkaz. Ale
je zajímavé, že překladač to přeloží ani nevypíše warning, ikdyž je to logický
nesmysl. Nevím, co to ve skutečnosti udělá, asi se to přeloží jako prázdný
příkaz. Pokud ovšem místo 3; napíšeme 3(); ohlásí
chybu "Call of nonfunction" a není důvod se mu divit. Také můžete
napsat samotný středník na řádku, to by se potom mělo přeložit jako prázdný
příkaz. Podobně je nesmyslným příkazem např. sin(x) samotné na řádku, má to
sice smysl, pouze výstup funkce se zahazuje. Má to smysl např. u funkcí getch(),
pokud nás nezájímá, jaká klávesa byl stisknuta, ale pouze chceme naprogramování
čekání na stisk libovolné klávesy.
Pozor: Z Pascalu jsme zvyklí psát volání procedur bez parametrů např.
ClrScr; nebo ReadKey; , ale zde v C++ je to nebezpečné, překladač má nějaký
výraz (viz náš příklad s 3; v předchozím odstavci) a přeloží se to jako prázdný
příkaz. Takové chyby se dost špatně hledají, snad s vyjímkou funkce v C++ nosound();,
pokud zde zapomeneme (), přeloží se to jako prázdný příkaz, nevypne se zvuk z
reproduktoru a programátorovi dojde, co se stalo... :-) , že za nosound
zapomněl závorky a tedy se funkce nosound nezavolala, protože se přeložila jako
prázdný příkaz.
Blok:
S blokem jsme se již seznámili, ale pro úplnost si zopakujeme:
{
[příkazy]OPT OPT = optional = volitelné
}
Příkazy a deklarace jsou nepovinné, blok může být prázdný ze stejného
důvodu, jako že příkaz může být prázdný. Blok totiž odpovídá složenému příkazu.
Blok je třeba volit v případě cyklů, větvení a podmínky, funkcí a hlavního
programu, kde se všude očekává 1 příkaz. Pokud tedy chceme mít více příkazů,
potom je musíme logicky dát do bloku a vytvořit složený příkaz. Složený přikaz
je již jedním příkazem, který už v podmínce a cyklu může být. { } odpovídá v
Pascalu příkazům begin a end.
Bloky lze (stejně jako v Pascalu) do sebe vnořovat. Lze samozřejmě dávat
každý jednotlivý příkaz do bloku, lze psát {{{}}} nebo {{{příkaz}}}, proč ne,
když to programátora baví :-)
Moje poznámka: Je nutné mít stejný počet { jako }. To je ovšem
logické. Nešetřete ovšem závorkami, jak kulatými ( ) ve výrazech a podmínkách,
tak i složenými { } v blocích. Pozor v cyklech a podmínkách se očekává 1
příkaz, pokud zde chceme uvést více příkazů a zapomeneme na to dát příkazy do {
}, potom doplatíme na svou šetrnost a chybu. (V těle funkce musí vždy být { }.)
Připomenu svou poznámku. Chtěl jsem si naprogramovat makro swap na přehazování
dvou číselných proměnných. Přednášející ing. M.Virius, CSc. mi řekl, že to lze
udělat bez deklarace lokální proměnné, pouze použitím operací sčítání a
odčítání? Napadne vás to? (Důvod proč to zde uvádím je ten, že to souvisí se
šetřením { } za podmínkami resp. cykly.)
Moje poznámka: Řešení mého problému: Makro swap bude vypadat #define
swap(x,y) x=x+y;y=x-y;x=x-y; Makro swap je vlastně jako nahrazení swap(x,y)
těmi třemi příkazy v každém místě programu. Zkušení programátoři se asi už
usmívají, co se mi asi stalo... Časem jsem swap používal v Bublinkovém třídění
pole a zapomněl jsem, že swap je makro a ne funkce (procedura), takže jsem
napsal if (a[i]>a[j]) swap(a[i],a[j]); kde pole a bylo číselné a mohl jsem
tudíž použít své makro. V případě funkce by to fungovalo normálně, tak jak to
má, zavolalo by se funkce swap a přehodila by proměnné a bylo by vše v pořádku.
Ale zapomněl jsem, že je to makro, takže se to ve skutečnosti přeloží jako:
if (a[i]>a[j]) a[i]=a[i]+a[j];
a[j]=a[i]-a[j];a[i]=a[i]-a[j];
Moje poznámka - vysvětlení: Podmínka if tedy, pokud je splněna,
provede pouze 1. příkaz a pokračuje se provedením zbylých dvou příkazů (to by
ještě šlo...), ale v případě nesplnění podmínky se 1. příkaz neprovede (tak je
podmínka if definovaná), ale zbylé dva příkazy se provedou vždy a zničí tak
obsah pole... :=(
Moje poznámka - řešení: Vzpomeneme si na poznámku, že nebudeme v
podmínkách šetřit složenými závorkami a použití toho makra napíšeme takto: if
(a[i]>a[j]) {swap(a[i],a[j])} Takto to už bude zaručeně fungovat. V případě,
že swap není makro, ale funkce (procedura), potom by byl zde blok zbytečný.
Moje poznámka:Prográmek s makrem SWAP.CPP
Poznámka: Přiložený prográmek demonstruje přístup ke globální
proměnné použitím ::i a také vnořování proměnných v různých blocích a jejich
zastínění.
Poznámka - prázdný příkaz: Prázdný příkaz je středník; samotný nebo
blok { }
Podmíněný
příkaz, podmínky:
Poznámka - podmíněný příkaz: Podmíněný příkaz - if(podmínka)
příkaz1 [else příkaz2]opt. Je také možné je do sebe
vnořovat, protože podmíněný příkaz je také příkaz a bloky je také možné do sebe
vnořovat.
if (i>0) x=7; else x=11;
je správně, zatímco:
if (i>0) {x=7;}; else x=11;
je chybně, protože středník za {x=7;}; je příkaz, který ovšem nemůže zde
být, jestliže následuje else.
Poznámka - rozdíl = a ==:V podmínce můžeme napsat x=7, což je možné,
protože x=7 přiřadí do proměnné x hodnotu 7 a jako výstup dá přiřazení hodnotu
7, což lze testovat v podmínce. 7 je ovšem nenulová, takže se příkaz za
podmínkou vždy provede. Kdyby ovšem byla výsledkem přiřazení 0, tak se příkaz
za podmínkou neprovede a provede se příkaz za else, pokud if obsahuje else. Ale
většinou má programátor na mysli x==7, tedy test, zda je x rovno hodnotě 7 a
pokud ano, provede se příkaz za podmínkou Proto když napíšeme v podmínce x=7
místo x==7, překladač program přeloží, ale vydá varování warning, podle kterého
jsme upozorněni, zda jsme to mysleli tak, jak jsme to napsali.
Poznámka - neúplné vyhodnocování: Pokud napíšeme např. if (x>0
&& sqrt(x)<10) f(); potom se vyhodnotí první podmínka (x>0)
nesplněna a následuje logický součin (and - a současně - &&, logický
součin 0 s jakýmkoliv výrazem je vždy 0), proto se další podmínky již
netestují. Analogicky by to bylo, pokud by byla 1. splněna a byl zde logické
součet (or - nebo - ||, logický součet 1 s jakýmkoliv výrazem je vždy 1), proto
se další podmínky již netestují. V Pascalu se toto dá nastavit, Pascal asi rád
dělá zbytečné operace nebo překladač nechce generovat lepší kód, pokud to není
nezbytně nutné, v Pascalu se to dá nastavit v Compiler Options - Complete
Boolean Evaluation. V BC C++ 3.1 jsem podobné nastavení neuviděl (možná že tam někde
je...???) a překladač automaticky používá neúplné vyhodnocování, takže šetří
operace, pokud už je výsledek jasný, již dále netestuje ostatní podmínky. V
našem případě se již nebude volat funkce sqrt (druhá odmocnina) pro záporné
čísla.
Podmíněný
výraz:
Poznámka - podmíněný výraz: Pod podmíněným výrazem chápeme ?:,
bližší údaje v nápovědě. Vysvětlení: Nechť napíšeme např. a?b:c potom se
testuje "a", je-li podmínka splněna (pravda - True), potom výsledkem
výrazu "b", je-li podmínka nesplněna (lež - False), potom je
výsledkem výrazu "c".
Příklad: Naprogramujeme hledání maxima dvou čísel:
if (x>y) max=x; else max=y;
nebo použitím podmíněného výrazu:
max=(x>y)?x:y
Pro programátora v Pascalu bude asi přehlednější 1. možnost, avšak
programátor v C++ raději uvidí 2. zápis. Je k dispozici
demonstrační prográmek pro maximum a minimum dvou čísel naprogramovaných dvěmi
metodami.
Pořadač:
Poznámka - pořadač: Pod pořadačem rozumíme, operátor - čárka ,
který má význam jako zahození výstupu z první funkce. Nechť f(x) a g(x) jsou
funkce (ne matematické, ale nějaké v C resp. C++). Potom výraz zapsaný v C++
takto: f(x),g(x) zavolá první funkci f(x), výstup zahodí a zavolá druhou funkci
g(x) a výsledkem f(x),g(x) bude vracená hodnota funkce g(x).
proměnná=(f(x),g(x))
je ekvivalentní zápisu:
f(x);proměnná=g(x);
Směry přiřazení a
operací:
Charakteristickými vlastnostmi operací (operátorů) je priorita a
asociativita. Ukážeme si směry přiřazování a směry operací např. sčítání.
Závorky mají nejvyšší prioritu a tedy co je v závorkách, to se vyhodnotí
nejdříve, nakonec se vyhodnotí to, co má nejnižší prioritu.
Příklad č.1: x=y=z=7; zde se postupuje zprava doleva, tj. nejdříve se
přiřadí sedmička do z, potom se překopíruje obsah proměnné z do y a nakonec se
překopíruje obsah proměnné y do x. Je to tedy ekvivalentní zápisu:
x=(y=(z=7)));
Příklad č.2: Výraz a+b+c obsahuje všechny operace stejné priority,
proto se postupuje zleva doprava. Překladač to přeloží asi jako: (a+b)+c
Příklad č.3:
int x,y;
double z,c;
c=x=y=z=3.14
Bude výsledkem v proměnné 3 ne však 3.14. Důvodem je, že zde (ač je tento
příklad nelogicky a nesmyslný, ale to teď necháme stranou, důležité je si
vysvětlit, proč to tak je, jak to je...). Budeme postupovat postupovat podle 1.
příkladu, tedy zprava doleva. Proměnná "z" je double, tedy reálné
čísla, tedy se do proměnné z přiřadí skutečně 3.14. Dobře, v "z" už
máme hodnotu 3.14. Nyní chceme přiřazení y=z, podíváme se, že "y" je
v našem případě int, tedy celočíselná proměnná. Na pravé straně "z"
je reálné číslo. Provede se tedy konverze z double na int tak, že se usekne
desetinná část a překladač provede ještě další operace a přesuny, které nejsou
teď až tak moc důležité. Po useknutí desetinné části máme v y již 3. Nyní máme
provést přiřazení x=y, obě proměnné jsou int, takže je to bez problémů, vše je
jednoduché, v x tedy máme 3. A posledním přiřazením je c=x, zjistíme, že c je
double a x je int, takže se provede konverze z int na double. Celá čísla ovšem
nemají desetinnou část, proto bude v "c" nulová desetinná část a tedy
v "c" skutečně bude po přiřazení 3.
Cykly:
- while(podmínka)
příkaz Místo příkazu ukončeného samozřejmě středníkem, lze napsat
blok, jak už jsme si zvykli.
· int x,y=11;
· while(x==y) ;
V tomto případě, tak dlouho dokud je splněna
podmínka, provádí je příkaz, který je za podmínkou while. Je to klasický
Pascalovský cyklus while, akorát, že zde chybí klíčové slovo "do" a
podmínka se zásadně píše do závorky, neboť závorky určují začátek "("
a konec podmínky ")".
- do příkaz
while(podmínka) I zde je možné napsat místo příkazu blok, ve
kterém budou i příkazy a deklarace (stejně je v C++ každá deklarace
příkaz). Zdánlivě připomíná Pascalovský cyklus repeat until, je zde
vlastně rozdíl v negaci podmínky. Ale to je zřejmé z anglického významu
slova while. Dělej příkaz dokud je spněna podmínka. Cyklus tedy vždy
proběhne alespoň jednou. Pascalový cyklus repeat until končí splněním
podmínky (opakuje se při nesplnění), C resp. C++ cyklus končí nesplěním
podmínky (opakuje se při splění).
- for(výraz1;výraz2;výraz3)
příkaz Je to vylepšený oproti Pascalovskému cyklu for, který uměl
pouze pro celá čísla, přičítat a odčítat jedničku. Cyklus for v C resp C++
je ekvivalentní zápisu:
· výraz1;
· while(výraz2) {· příkaz;
· výraz3;
}
Z tohoto ekvivalentního zápisu je zřejmé, že
"výraz1" je inicializace, tedy zde nastavíme proměnnou cyklu na
počáteční hodnotu (můžeme mít cyklus celých, reálných a také i komplexních
čísel - pokud někdo nalezne použití). Proběhne před vlastním cyklem.
"výraz2" je podmínka opakování, opakuje se při splnění podmínky.
"výraz3" je vlastně část, která se provádí v každém kroku. Zpravidla
se sem dává příkaz pro zvětšení (snížení) o 1 či příkaz pro další možnou
hodnotu. "příkaz" je normální příkaz, který se má provádět, může zde
být také složený příkaz, protože málokdy stačí jeden příklad v cyklu. Příklad
je v následující kapitole o poli.
Pole:
Příklad: Vyplnění pole jedničkami
int a[10]; //var a:array[0..9] of integer;
for (int i=0; i<10; i++) a[i]=1; //for i:=0 to 9 do a[i]:=1;
Deklarace pole a použití je analogické Pascalu. Deklarace je stejná jako
deklarace proměnné, pouze s tím rozdílem, že se za názvem proměnné napíše
[index].
Pozor: Pole má první prvek vždy s indexem 0. Vždy je počet prvků
tolik, kolik je číslo v hranaté závorce. Deklarace int a[10]; vyhradí v paměti
10 proměnných typu int, index prvního je 0 (jak jsem již napsal) a index
posledního je 9. Když to programátor neví a spoláhá na Pascalovské hlášení
Range Check Error, potom je v C++ nemile překvapen, že se mu přepisují obsahy
jiných proměnných, nebo že přepisuje část kódu nebo že se mu dějí podivné věci.
Takové hlášení se v C++ neobjevuje, je na programátorovi, aby si to ohlídal.
Proto, když to programátor neví, potom mu zpravidla program nefunguje tak, jak
by měl... Ani není v C++ možné nastavit, aby se hlášení Range Check Error, aby
se kontrolovaly meze. Jediným možností řešení je předefinovat operátor
indexování [ ], což se snad také někdy naučíte.
Poznámka: Je zde udělán prográmek pro obrácení
pole od posledního k prvnímu.
Poznámka - příkaz break: Příkaz break provede ukončení
cyklu a skok na další příkazy za cyklem. V Borland Pascalu 7.0 je již příkaz
break implementován, takže i v Pascalu ho můžete již používat. Starší verze
Pascalu ho ještě neumí. Demonstační program pro break.
Poznámka - příkaz continue: Příkaz continue přeskočí
zbytek těla cyklu a skočí na podmínku opakování. Cyklus se narozdíl od break
neukončí, ale přeskočí se ne konec cyklu a pokračuje skokem na podmínku
opakování cyklu.Demonstrační program pro continue.
Větvení - switch:
Tento příkaz je určen k větvení chodu programu na varianty podle hodnoty
výrazu v podmínce. Je to obdoba Pascalovského case of, ale programátor, který
znal Pascal, bude trochu nemile překvapen, že bude muset dávat za jednotlivé
možnosti break a také že nelze použít v jednotlivých možnostech interval
(10..25: příkaz), C++ totiž po skončení té větve totiž nedá skok do společné
části, ale pokračuje se dál, takže pokud je za ní další větev, skočí se do ní. Blíže to ukáže přiložený příklad, je ukázáno, co se stane
v případě, že zapomenete ve větvi příkaz break;.
Deklarace:
switch(výraz)
{ case hodnota1: příkaz1;
case hodnota2: příkaz2;
...
case hodnotan: příkazn;
defaulta: příkaz;
}
Příkazy 1-n většinou jsou sloužené, takže je tam blok { } a posledním v
bloku je příkaz break; , aby následoval skok do společné nerozvětvené části za
koncem switch. Příkaz break je nutný proto, že se podle hodnoty sice skočí na
příslušnou větev, ovšem C++ již nevloží skok do společné části, takže se
následuje pokračováním do další větve (u poslední nám to nevadí).
Vylepšené řešení prvního programu je zde, kde je
již problém vyřešen tím, že již obsahuje break; na konci větví.
Poznámka: Příkaz break lze použít v cyklech a ve
switch, zatímco continue lze použít pouze v cyklech.
Poznámka: Pokud si přejeme jedene stejný příkaz použít pro více možností
case ve switch, můžeme to udělat např. takto:
case 'a':
case 'A': cout << "Ahoj" << endl;
Je to domonstrováno v již ukázaném příkladu.
Poznámka - v C++ neexistuje Pascalovský příkaz with: V Pascalu
existuje příkaz with pro práci se strukturami a objekty a tady v C++
neexistuje.
Assembler v C,
C++:
U překladačů Watcom je možné vložit instrukce Assembleru takto:
asm(řetězec), asm("mov AX,10")
U překladačů Borland se Assembler vkládá takto: asm { instrukce Assembleru }
Správně:
asm { instrukce
}
Také správně (může to být se středníkem, ale také nemusí BC 3.1):
asm MOV AX,0
Špatně:
asm
{ instrukce
}
!!!Pozor!!! Proč je to špatně? Pokud existuje i možnost s asm na
jednom řádku, očekává buď jednu instrukci v Assembleru (ale to je směšné, co
udělá 1 instrukce Assembleru) nebo blok { }. Pokud tam nic nenapíšeme, přeloží
to jako prázdný příkaz a uvidí na dalším řádku blok, tak to je složený příkaz,
ale už předpokládá, že je to složený příkaz v C resp. C++, kde už nezná
instrukce v Assemleru, takže ohlásí chybu při překladu.
Poznámka pro specialisty: Assemblerovské instrukce se běžně vkládají
do programového - code segmentu. Lze je vkládat i do dat - data segmentu, což
běžní uživatelé asi nepoužijí, ale někdy se to hodí u samomodifikujících se
programů. Ale to jsou dost nebezpečné věci a může to udělat tolik zmatků, že to
může mít podobné důsledky, jako když přepíšeme část paměti např. při překročení
mezí pole a zapsání tam nějaké hodnoty.
Příkaz return:
Příkaz return hodnota má smysl pouze u funkcí, ale jelikož v
C++ jsou všechno funkce, tak to musíme upřesnit, že je to u fukncí, který mají
nějaký výstup. Příkaz return hodnota tedy nemá smysl u funkcí
vracející void - tedy ty, které mají prázdný výstup. U funkce vracející void
(funkce bez výstupu), je možné použít pouze return; - tedy bez vracené hodnoty.
A u funkcí, které mají neprázdný výstup, nelze použít return; ale pouze return
hodnota;.
Příkaz return okamžitě ukončuje funkci a předá se řízení za příkaz, který
vyvolal tu danou funkci.
V hlavním programu int main() { } se používá v DOSu pro vracení chybového
kódu DOSu - proměnná ERRORLEVEL. Proto je tedy dobré, definovat hlavní program
jako funkce vracející nějakou hodnotu. Jak je to s vracením hodnoty z hlavního
programu na Unixu, to si netroufám řící.
Další povídání o příkazu return je zde.
Výčtové typy
Deklarace: enum [jméno] { co bude obsahovat}
Příkady:
enum tyden {pondeli, utery, streda, ctvrtek, patek, sobota, nedele};enum mesice {leen, unor, brezen, duben, kveten, cerven, cervenec, srpen, zari, rijen, listopad, prosinec};enum Bible {Stary_Zakon, Novy_Zakon};
V C++ jsou výčtové typy zvláštní typ, v C je to celočíselný typ. Z toho
vyplývá, že v C lze napsat přiřazení x=7; (x je proměnná výčtového typu), ale v
C++ ne. Za poslední položkou ve výčtovém typu může být čárka, překladač
neohlásí chybu.
Příklad s výčtovými typy:
Pomocí typedef lze tvořit synonyma např.:
typedef enum dny {po,ut,st,ct,pa,so,ne} Dny;
Programátoři trápícíse aplikacemi pro Windows asi znají pojem handle. Někde
v překladači je napsáno něco jako:
typedef int handle; je to tedy alternativní typ pro int, nový
typ - název. Má to tu výhodu, že pokud chceme změnit rozsah proměnné typu
handle, stačí pouze změnit int na větší či menší typ a znovu přeložit. Sice to
znepřehledňuje výpis programu, že hned na první pohled není vidět, jakého typu
je proměnná hande (někdy to nelze ani poznat), ale lze snadno modifikovat a
není třeba zdlouhavě prohledávat, kde jsem hande použil, abych změnil její typ.
Poznámka: Pro výčtové typy lze přetížit operátory <<, >>.
To kdyby si někdo přál místo čísla výstup rovnou název.
Makra a podmíněný
překlad:
Moje poznámka: Někde si ještě pamatuje na to, že jsem si definoval
makro swap pro prohazování obsahu dvou proměnných a na (skoro začátečnický)
problém, který z toho vyplynul.
Moje definice - makro: Makro je něco, co se rozvine v
řetězec a odpovídá to jako Replace ve zdrojovém textu. Zdrojový text se ovšem
nemění.
Moje poznámka: Jedná se vlastně o nahrazení něčeho nečím, co dělá
překladač před vlastní kompilací. Nemám rád definice, vy snad také ne, proto
hned přejdeme k příkladům. V Assembleru (už na ATARI 800 XL byl
makroassembler), což je tvoření skupiny instrukcí, které se nějak označí
(nejlépe podle funkce) a tak při každém uvedení jména makra vložil strojový kód
přeloženého makra do místa volání. Je to jako podprogram, avšak se místo skoku
do podprogramu vloží tělo makra. Zde v C resp. C++ je to podobné. Zdrojový text
se nemění, pouze to umožňuje vytvořit kód, který nemusí mít skoky (je sice
delší), ale lze ho libovolně posunovat v paměti, aniž by se museli měnit
adresy, kam se skáče, protože přeložený strojový kód odpovídající makru se vždy
vloží na místo volání. V C++ makro můžeme použít k definování konstanty,
symbolu, či jako skupina příkazů, které se vloží na místě volání.
Deklarace makra: Z definice makra jste možná pochopili, že se bude
něco nahrazovat něčím.
Poznámka: Řetězec makra se bere až do konce řádky. Nepíše se nakonci
řádky středník, neboť
#define název_makra řetězec
Příklad č.1: Makro jako konstanta: #define N 1000 Před vlastním překladem
nahradí všude kde je N číslem 1000, tisíc zde bude jako řetězec (ne v binárním
tvaru) jako ve zdrojovém textu.
Příklad č.2: Makro jako procedura pro přehazování číselných
proměnných: #define swap(x,y) {x=x+y;y=x-y;x=x-y;} V každém použití makra se
vloží tyto příkazy. Tak se dosáhne přehození dvou proměnných.
Příklad č.3: Makro jako funkce pro vrácení maxima dvou čísel: #define
max(x,y) (((x)>(y))?(x):(y)) Je to výraz (který jsme si uvedli v kapitole o
podmíněném výrazu), pouze s trochu více závorkami. Poznáte, že u maker se
závorkami nevyplácí šetřit. Hodně závorek je zárukou úspěchu. Proč je dobré
dávat u maker hodně závorek, poznáte z příkladu 4.
Příklad č.4: Makro jako funkce pro vrácení druhé mocniny čísel:
#define sqr(x) x*x; Vyzkoušejte si, co se stane a zjistíte, že to někdy
nefunguje... Pokračování v příkladu. Můžete se mrknout
sem na příklad.
Poznámka: Nastavení šířky výstupu u cout se provede manipulátorem setw(n),
kde n je počet míst a lze ho nalézt v hlavičkovém souboru <iomanip.h>
Poznámka - podmíněný překlad: Jedná se možnost překládat či
nepřekládat části zdrojového textu v závislosti na existenci nějakého makra.
Deklarace:
#if podmínka
.....
#else
.....
#endif
Podmínkou může být existence makra, potom je podmínka takováto:
#if defined RET
.....
#endif
Podmínkou musí být taková, kterou je možno vyhodnotit v době překladu. Za
define se nepíše středník. #ifdef = #if defined.
Trik č.1: Odstranění části textu:
#if 0
...
#endif
Trik č.2:Existuje trik, pokud potřebujeme odladit část programu
samostatně, pokud se skládá z více souborů a potřebujeme mít alespoň nějakou
funkci main, abychom mohli podprogram odstartovat. Řešení:
#defined LADIM
.....
#ifdef LADIM
int main()
{ ....
}
#endif
Pokud tedy ještě ladíme, necháme existovat makro LADIM. Pokud už to bude
odladěno, zrušíme makro LADIM vymazáním řádky #define LADIM. Potom už nebude
makro existovat, takže se nebude ani překládat funkce main().
Trik č.3: <assert.h> je použitelné při ladění. Chceme např. mít
jistotu, aby např. x bylo větší než y. Potom použijeme hlavičkový soubor
<assert.h> a vložíme do programu makro assert(x>y);.
Pokud je podmínka splněna, potom se pokračuje, jinak se vypíše chybové hlášení.
Může se to hodit např. pro test, zda je alokovaná paměť. Pokud máme program již
odladěn (což je asi nejmilejší chvíle pro programátora), potom nemusíme
vyhledávat použitá makra assert, ale stačí přidat: #define NDEBUG,
které způsobí, že makro assert se rozvine v prázdný řetězec, takže už formálně
nebude vadit a zdrojový text se stejně moc neukazuje...
Poznámka - zrušení makra: #undef jméno
# if !defined = #ifndef
#if defined = #ifdef
#else if = #elif
Ukazatele:
Ukazatel definujeme tak, že před proměnnou napíšeme *.
Příklady:
- int *ui,j; //ukazatel na
int pojmenovaný ui a definování int j
- char *a,*b; //ukazatele
a,b na znak
- char c; //deklarace znaku
= 8mi bitové číslo
- a=&c; //možné
přiřazení - do ukazatele na char se uloží adresa proměnné c, což je char
Pole a ukazatele: Každý ukazatel se pokládá za ukazatel na začátek
pole. U polí (jak už jsme řekli) nelze volit dolní mez, ta je 0. int P[10];
vytvoří pole P[0],P[1],...,P[9]. Pokud napíšeme const N=10; potom se bere jako
konstanta typu int. Potom můžeme zapsat:
const N=10;
int P[n],i,*ui; //deklarace pole intů, proměnná i typu int,ui je ukazatel na int
for (i=0;i<N;i++) P[i]=i; //vyplnění pole čísly od 0 do N
Rozdíly polí v C,C++ proti Pascalu:
- Pole se nedají přiřazovat
takovým způsobem, jakým známe z Pascalu:
int P[N],Q[N];
Q=P; //zde to naštěstí nejde přeložit, ale u řetězců to půjde, ale u
řetězců se změní pouze ukazatel na řetězec, ale to bude až dál.
Ale musí se použít cyklus pro překopírování obsahu pole: for
(i=0;i<N;i++) Q[i]=P[i];
- C ani C++ nekontrolují
překročení mezí, což má za následek přepsání části paměti
Dynamická alokace paměti:
- int *ui = new int; //
alokace jedné proměnné typu int, ukazatel ui bude ukazovat na alokovanou
proměnnou int, pokud není 0, pokud je 0, potom se alokace nezdařila
- int *ui = new int[N]; //
alokace pole o N proměnných typu int, ui bude ukazovat na první prvek pole
intů, pokud není 0, pokud je 0, potom se alokace nezdařila
Do místa, kam ukazuje ui se uloží 11 příkazem *ui=11;
Lze dereferencovat - lze aplikovat indexování ui[5]=7; lze tedy pomocí
ukazatele pracovat s polem.
Borland C++ 3.1 má hezkou pomůcku pro kontrolu paměti, která se jmenuje
inspektor a vyvolá se stiskem ALT + F4 nebo z menu Debug Inspect. Do okénka
napíšeme název proměnné, kterou si chceme prohlédnout. Narozdíl od Turbo-Debuggeru
umožňuje prohlédnout si dynamicky alokované pole, což se hodí např. v
seznamech, kde umožňuje si prohlížet i jednotlivé prvky v seznamu, aniž bychom
definovali nějakou funkci, která by seznam zobrazovala. Můžeme zobrazit i prvek
pole zadáním ui[4]. ui=p; To by mohlo mít následek, že byste moli považovat
pole za ukazatel na jeho první prvek za jedno a totéž. To ovšem není totéž, viz
následující vyjímky:
Vyjímky, kdy není totožný ukazatel na 1. prvek pole a pole:
- U operátoru sizeof(P). Zde
se skutečně pole nebude konvertovat na ukazatel na jeho první prvek a bude
vracet rozměr skutečného pole.
- Reference v C++
3. int ui = &P; //P je pole
4. int uui[10]*; //ukazatel na pole o délce 10 prvků int
5. int *uui=P; //lze
Adresová
aritmetika:
Co to je adresová aritmetika? Nechť tedy máme například pole a nějaký
ukazatel, který ukazuje někam v poli. Nyní můžeme přistupovat k dalším prvkům
pole tak, že můžeme pohybovat s tímto ukazatelem po poli.
int *ui; //bude použit jako ukazatel někam do pole intů
ui+1 bude potom ukazovat na další prvek pole
ui+5 bude potom ukazovat o 5 prvků dále
Podporované operace: Jsou tedy definované operace + - pro posun v
poli. To ovšem není všechno. Lze porovnávat ukazatele ui==uj a také testovat
nerovnost ui!=uj. Je možné používat používat operace < > <= >=
Ukazatele lze sčítat, odčítat. Odčítáním lze zjistit počet prvků mezi nimi.
Nulový ukazatel (obdoba Pascalovského NIL) má zde v C++ hodnotu 0 (někdy se
definuje konstanta NILL). Ukazatel lze testovat v podmínce if(ui)
ui<>True, ui=0 False.
Prográmek na vyplnění pole:
Prográmek na vyplnění pole použitím adresové
aritmetiky, popis je součástí prográmku.
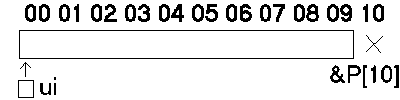
Prográmek na kopírování 2 řetězců:
Nejprve si zkusíme vysvětlit, co se stane pokud definujeme dva řetězce:
char *c = "AHOJ";
char *d = c;
Potom se vyhradí v paměti text, na který bude ukazovat ukazatel c. Pokud
nyní definujeme ukazatel d, tak místo vyhrazení nového prostoru se pouze
ukazatel d vezme a bude ukazovat na stejný řetězec. Kdo mi neuvěří, může si
zkusit změnit část řetězce c, změní se i d a opačně. V přiloženém příkladu je
všechno naprogramováno a je naprogramována a vysvětlena funkce strcpy pro
kopírování řetězců. Je naprogramována klasicky C++, takže programátorům v C++
to může připadat jako magická formulace, ale žádné magie neexistuje (všechno to
jsou podvody), tak přikládám vysvětlení.
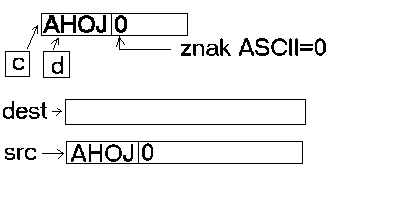
Zde na obrázku uvidíte, co se stalo v případě, že budeme chtít kopírovat
řetězce pouze přiřazovacím příkazem. Vlastně se stane pouze to, že se změní
ukazatel na řetězec a bude ukazovat jinam.
Zde u řetězcových operací je úmluva psát cíl jako první parametr nebo jako
výstup funkce.
Inicializace polí: Asi jste to již viděli v příkladu, nicméně člověk
je podle své definice tvorem zapomínajícím, proto to zopakujeme. Příklad: int
y[10]={1,2,5,88,} Pokud neuvedeme všechny čísla, potom by se měl zbytek doplnit
nulami. Nemusíme také počítat počet prvků napsat y[]={prvky pole}, v tom
případě si je počítač spočítá a deklaruje nejmenší pole obsahující všechny
prvky.
Zjištění velikosti polí: Použijeme sizeof(pole). V našem případě
můžeme např. napsat: cout << sizeof(y) << endl; - vypíše se 8 - což
jsou 4.int a int zabírá 2B.
Práce s dynamickou pamětí: Pojem dynamická paměť znamená
paměť, ve které můžeme za běhu programu vytvářet nové proměnné, pole a data, je
ji možné také alokovat. Tyto proměnné se neruší při výskoku z proměnné, někdy
se ani neuvolní při ukončení programu, ale za normálních okolností by je měl
programovací jazyk či operační systém vrátit a uvolnit, pokud tak neudělá
nepořádný programátor. Spolu s dynamickou pamětí se objevuje pojem halda, což
je jiný název pro tu oblast paměti, kde lze zřizovat nové proměnné a rušit je.
Proměnné tedy mohou být:
- globální v
C++ definované mimo blok funkce main hlavního programu a funkce. Globální
proměnné by měly být přistupné jak hlavnímu programu, tak i ostatním
funkcím a objektům.
- lokální v
C++ definované v bloku nějaké funkce nebo ve funkci main hlavního
programu. Lokální proměnné existují jen v tom bloku, kde jsou definované,
po opuštění bloku zanikají. Ukládají se většinou do zásobníku.
- statické
jsou to vlastně lokální proměnné, které se jen jednou vytvoří a po
opuštění funkce nezanikají, ale nejsou znát mimo blok.
- dynamické
uživatelský program nebo i programovací jazyk či operační systém je mohou
vytvořit i zrušit v libovolný čas. Počet proměnných, které je možné
přidělit, je omezen jen velikostí haldy - tedy maximálního prostoru
paměti, která je určena pro dynamické paměti.
- externí
mohou být buď proměnné uložené mimo program, např. na v souboru na disku,
nebo v paměti přístupné pro více programů nebo pro více částí stejného programu.
V tomto ohledu jsou to globální proměnné.
- objektové
proměnné patřící objektu. Vznikají spolu s objektem, mohou být
inicializované a vytvořené konstruktorem příslušného objektu, ke kterému
patří. Zanikají při zániku objektu pomocí destruktoru. Podle druhu mohou
být buď privat (soukromé), kromě toho objektu a jeho metod s
nimi nikdo dělat nic nemůže. Pokud je proměnná s přístupovým právem friend,
potom je ta proměnná dostupná všem odvozeným objektům a jejich metodám. S
proměnná s přístupovým právem public si může dělat každý, co
chce. Nevýhody proměnných typu public je, že mohou být kýmkoliv změněny a
nastaveny i na nesmyslnou hodnotu. Výhodou proměnných private je, že jsou
chráněné proti neodborným zásahům a o jejich existenci se neví, jen sám
objekt je může kontrolovat a měnit.
Přidělení dynamické paměti:
- int *i = new int; //
vytvoří proměnnou typu int a ukazovat na ní bude proměnná i - což je v
tomto případě ukazatel.
- int *i = new int(5); //
vytvoří proměnnou typu int a navíc ji inicializuje na hodnotu 5 a stejně
jako v předchozím případě na ni bude také ukazovat ukatzatel i
- int *i = new int [n]; //
vytvoří n prvkové pole, které nelze zde inicializovat
Odstranění - uvolnění dynamické paměti:
- delete []i; - uvolnění
pole, lze u neobjektových polí vynechat [] a napsat delete i;
Vícerozměrná
pole:
Vícerozměrná pole: příklad: double matice[3][5]; matice 3x5. V C
existují pouze jednorozměrná pole, což ovšem nevadí, pokud prvkem pole může být
zase pole. Takže dvourozměrné pole je vlastně pole, jehož prvky jsou pole.
Takže v našem případě to bude pole [0],[1],[2], které obsahují proměnné typu
double [0],[1],[2],[3],[4].
Jak víme, většinou se pole konvertuje na ukazatel na 1. prvek (až na těch
několik vyjímek). Nyní si ukážeme, jak je možné přistupovat k prvkům pole bez
použití indexování, např. pomocí adresové aritmetiky.
Příklad: Chtěli bychom se dostat a získat obsah případně změnit prvek
mat[1][1] pomocí adresové aritmetiky. První indexování může být *(mat+1), což
bude ukazovat na začátek mat[1], tedy na začátek prvku pole - jehož prvkem je
pole, takže se posuneme o délku prvku, kterým je pole, 2. indexováním potom se
posuneme v tom daném poli, nyní se posuneme o délku double a výsledek je potom
*(*(mat+1)+1).
Příklady: Deklarujeme matici:
- double mat[3][5] =
{{1,2,3,4,5},{11,12,13,14,15},{21,22,23,23,24,25}}
- double mat[3][5] = {0}; //
mat[0][0]=0; zbytek pole by se měl doplnit nulami
- double mat[3][5] =
{1,2,3}; //všechny budou v 1. poli, tedy v mat[0][0]=1, mat[0][1]=2,
mat[0][2]=3;
- double mat[3][5] =
{{1},{2,3}}; //mat[0][0]=1, mat[1][0]=2, mat[1][1]=3, zbytek se doplní
nulami
Nulování pole: for (int i=0;i<3;i++) for (int j=0;j<5;j++)
mat[i][j]=0;
Poznámka: Deklaraci 5 ukazatelů na int provedeme: int (*up)[5];
Budeme chtít pomocí těchto ukazatelů naprogramovat vyplnění pole čísly ještě
jinou metodou, např. pomocí adresové aritmetiky.
for (int (*up)[5]=mat; up<&mat[3]; u++) for (int *ui = *up;
ui<&up[5]; ui++) *ui=11;
Máme zde vlastně definované jakési přístupové vektory, což je vlastně
ukazatel na ukazatel.
Příklad, implementující ukázku na předchozím obrázku:
int **m;
typedef int *ukint;
m=new(int*)[5];
m=new uknit[5];
for (int i=0;i<5;i++) m[i]=newint[10];
m je ukazatel na pole ukazatelů na int, což je ukazatel na pole, na kterém
lze opět použít indexování. Lze tedy adresovat např. m[i][j]=11;m[3][3]=111;
Rozdíl mezi předchozím příkladem a maticí vytvořenou pomocí: double
mat[10][15] je že v příkladu je pole jednak alokované dynamicky a zpravidla
není ani za sebou v paměti, obecně nelze polohu alokované proměnné
předpokládat, proto se u new vrací ukazatel, protože potom by nikdo nevěděl,
kde se ta daná vytvořená proměnná vlastně nachází. Zatímco deklarací double
mat[10][15] se vytvoří pole, které není alokované dynamicky a je to oblast 150
intů v paměti za sebou. Můžete se podílat do Turbo Debuggeru a většinou to tak
bude. Výhodou dynamicky alokovaného pole je, že lze vytvořit například
trojúhelníkovou matici, aniž by to nějak zbytečně zabíralo paměť, ale staticky
lze vytvořit pole a pole polí, které jsou obdélníkové. Pro uložení
trojúhelníkové matice by se v tom případě plýtvalo pamětí.
Pozor: Operátor new nemusí obecně uspět, je proto nutné ověřit, zda
je vracený ukazatel různý od nuly, v takovém případě, byla alokace paměti
úspěšná a adresa alokované proměnné je platná. V případě, že ukazatel je nula,
v tom případě je adresa neplatná a alokace se nezdařila (nejspíš na nedostatek
paměti, protože ji nějaký nepořádný programár zapoměl uvolnit operátorem delete.
Uvolnění paměti: K uvolnění paměti slouží operator delete, za který
se napíše ukazatel proměnné, která se má uvolnit. Toto místo rušené proměnné
bude OS nebo programovacím jazykem označeno za volné, takže může být použito
pro další alokaci. Proto, pokud zapomenete uvolnit přidělenou pamět anevrátí ji
sám OS po ukončení Vašeho nepořádného programu, potom to zabraňuje práci
dalších programů, které potřebují hodně paměti (dnes to není nic neobyklého).
Může to dojít k zaseknutí počítače, ať už s vypsáním hlášení typu Out of
memory, system halted, apod. a zaseknutí.
Borland C++ má takovou malou ochranu proti programům od programátorů, kteří
přepisují svá vlastní data nebo data jinde v paměti. Někde nazačátku uživatelského
programu v paměti je jakýsi řetězec Borland C++ International (nebo tak nějak),
který pokud se poničí (překladač ani editor ani žádný jiný program firmy
Borland ho nepřepisuje), proto se po skončení uživatelského programu testuje,
zda je neponičení. V případě, že je poničený, potom ho nejspíš poničil
uživatelský program chybným adresováním a vypíše se hlášení: "Null pointer
assigment". Za normálních okolností byste se to asi nedozvěděli a
programátor by mohl na chybu nepřišel. Problém je většinou, že pracujete s
nějakým ukazatelem, který má nulovou hodnotu a děláte s nic něco, co přepsalo
začátek vašeho programu, protože ukazatel má nulovou hodnotu. Doporučuji v tom
případě počítač resetovat, kdoví co se ještě poničilo...
Reálný
mód v DOSu, paměťové modely:
Reálný mód v DOSu: Adresa se udává jako segment a offset, obě to jsou
16-ti bitové čísla. Segmentová část adresy určuje adresu segmentu, který se
použije k adresování (CS - code segment, DS - data segment, ES - extra segment,
SS - stack segment) a offset je posun vůči začátku segmentu. Délka segmentu je
64 kB. Fyzická adresa v paměti se určí jako segment*16+offset. Takovéto
uspořádání je zastaralé a již se moc nepoužívá. Adresa je tedy segment:offset,
v C++ lze ji zapsat jako 0x16AB:FF00. 0x???? značí číslo v šestnáctkové
soustavě, ale to jsme si asi již uváděli v konstantách a pokud ne, tak už to
teď víte.
Paměťové modely v C++: V Borland C++ 3.1 je v option - code
generation uvedeno několik paměťových modelů. Některé (které jsem pochopil) si
popíšeme.
Poznámka: Po přeložení programu a spuštění programu obsahuje většina
programů tyto části:
- Kód - to jsou příkazy
přeložené do strojového kódu, na začátek většinou ukazuje registr CS (code
segment), na prováděnou instrukci ukazuje registr IP(instruction pointer).
Pokud je ovšem program delší než 64 kB, což je délka 1 segmentu, potom se
registr CS postupně mění.
- Data - jedná se o
globální data - globální proměnné, na začátek ukazuje registr DS (data
segment) a na konkrétní data v segmentu se používají registry BP,BI.
- Zásobník - do něj se
ukládají návratové adresy při volání funkcí a při rekurzi hrozí nebezpečí
přeplnění zásobníku. Do zásobníku se někdy ukládají lokální proměnné a
obsahy registrů. Někdy se lokální proměnné ukládají do registrů
mikroprocesoru, což zrychluje funkci programu. Ovšem registrů je málo
(segmentové: CS,DS,ES,SS, všeobecné: AX,BX,CX,DX, BP, SP, BI, DI, Flags,
IP). ?X se dělí na ?H (high) a ?L (low) - horní a dolní půlku. Půlky jsou
8-mibitové ?L, ?H a ostatní jsou 16-ti bitové.
- Halda - ta slouží pro
vytváření a rušení dynamických proměnných. Je to vlastně volná paměť,
kterou může kdokoliv využít, i překladač.
Tiny model: Je to model, ve kterém jsou data a kód v jednom segmentu,
tedy do 64 kB. Programátoři na ATARI 800 XL/XE a ostatních 8-mi bitových
počítačích si museli s tímto omezením vystačit. Tento model se hodí pro
vytváření .com souborů v DOSu. Pokud je program přeložen v tomto modelu, potom
používá zásobník DOSu (nemá vlastní). Všechny ukazatele jsou blízké, registry
CS=DS=ES
Small model: Všechny ukazetele jsou blízké, i ty s new, zásobník
(stack) je vždy max. 64 kB. Už má svůj vlastní.
Large model: Všechny ukazatele jsou vzdálené.
Bližší informace lze získat v nápovědě (klávesou F1). Ale to většina
programátorů ví, protože většinou loví názvy příkazů a syntaxe, rozsahy čísel
apod.
V malém modelu se dá definovat vzdálený ukazatel pomocí far, _far, __far.
Obdobně blízký ukazatel se deklaruje near, _near, __near. V malém modelu dost
dobře nefunguje adresová aritmetika, neboť po přičení 1 k 65535 nedostaneme
65536 (jak spočítá dobrý matematik), ale nulu (čemuž se matematik diví :-( ),
protože je adresa 16-ti bitová, takže větší číslo než 65535 tu jaksi nejde
zobrazit. Takže poku ukazuje ukazatel na konec (někem kolem 65534) a máme
ukazatel int near *f; a napíšeme f++; dostaneme se na začátek segmentu, což je
nemilé a pokud tam něco zapíšeme, nelze s určitostí říci, co jsme vlastně
přepsali a zničili.
Upozornění - definice huge ukazatelů: Z definice adresy
segment:offset je jasné, že adresa není jednoznačná. Z toho vyplývá, že tedy
obecně dost dobře nefunguje, proto není dobré se v adresové aritmetice spoléhat
na operátory = < >. Proto se definovaly ukazatele huge,
které jsou definované tak, že pro ofset platí: 0<=ofset<16. Potom je
takto definovaný ukazatel již jednoznačný a lze je porovnávat a i rovnost je
skutečně jednoznačná. Takže známe již tři druhy ukazatelů: far, near, huge.
Tedy je dobré používat implicitní ukazatele, tj. nespecifikovat typ ukazatele
(implicitně v malém modelu jsou blízké (near) ukazatele, v velkém modelu jsou
vzdálené (far) ukazatele. Pro porovnávání je dobré používat huge ukazatele.
Dereference *0: Toto nebezpečí hrozí hlavně v malém modelu. Je to
vlastně práce s nulovým ukazatelem (ukazujícím a obsahujícím hodnotu 0). V
tomto případě pracujeme s adresou DS:0. Proto je na začátku DS (data segmentu)
nápis Borland International, která slouží pro kontrolu, zda tam někdo něco
nezapsal a tím nápis porušil. Toto umožní programátorům zjistit, zda určitě
zapsali něco pomocí nulového ukazatele a pokud ano, objeví se hlášení: Null
pointer assigment.
Chráněný
mód, typy ukazetelů:
Poznámka: Na OS Win95,NT se pracuje v chráněném režimu, kde OS i
dokonce procesor hlídá uživatelský program, zda náhodou nepřistupuje mimo data
svého vlastního programu, pokud to zjistí, objeví se asi okno přes celou
obrazovku a program je ukončen bez uložení dat, což uživatele nepotěší. Někdy
se hlášení objevují dost času, proto je dobré všechno ve Win dost často
ukládat, neboť Win se hroutí častěji, než programy v DOSu, např. když
odstartujete velké množství programů. V chráněném režimu je tedy zákázano číst
a zapisovat mimo data svého programu, číst ani zapisovat do kódu svého
vlastního programu. Virtuální paměť je paměť, která se uchovává na disku a
slouží pro zvětšení uživatelské paměti, protože Win a programy pro Win jsou
"velcí žrouti" paměti. Adresa v chráněném režimu je tepu: selektor:offset,
selektor je 2B index v tabulce adres, je to obdoba segmentu, pouze zde je to
index do tabulky s adresami segmentů a ne adresa vlastního segmentu jako v
reálném módu. Offset je 4B a je to posun vůči začátku segmentu stejně jako v
reálném módu, pouze zde je 2x větší. V chráněném módu jsou všechny ukazatele
blízké, pracuje se pouze s offsety
Pro studenty FJFI: Po nalogování na server katedry matematiky
(lokálně nebo globálně na adrese tjn.fjfi.cvut.cz) si můžete namapovat nebo
přejít do adresáře: KM1\DATA:\HOME\VIR\VYUKA\CPP\#ZAKL\01 až 05, kde jsou
některé z prográmků uváděných na přednáškách Programování v C++ na FJFI - ČVUT.
void * je ukazatel bez doménového typu, je to obdova typu pointer z Pascalu.
Příklad: Nechť máme ukazatel v definovaný void *v; a přáli bychom si
definovat funkci F, která bude podle hodnoty předané jako parametr změní nějak
proměnnou libovolného typu. Na proměnnou bude ukazovat ukazatel v: void F(void
*v, int i) {if (i==1) {*(int*)v=10;} else {*(double*)v=3.14;}} Příkazem -
přetypováním (double*) získáme z neurčitého ukazatele void * ukazatel ukazující
na double, který pak referencí *(double*)v=3.14 můžeme zapsat do proměnné tuto
hodnotu. Obdobně lze přetypovat ukazatel void * na skoro libovolný ukazatel.
Poznámka - modifikátor seg: Modifikátor seg, _seg, __seg
lze použít pro získání segmetové části ukazatele (adresy). Příklad: int
__seg*x; bude obsahovat segmentovou část ukazatele x.
Lze příšít k segmentovému ukazateli přičíst blízká a získat tak vzdálený. Na
globální proměnné ukazuje DS, protože globální proměnné jsou v data segmentu.
Na lokální proměnné ukazuje SS, protože lokální proměnné jsou v zásobníku
(stack segment). Některé proměnné mohou být i v CS (code segment), ikdyž to
nebývá tak časté, většinou jsou to konstanty v instrukcích. Pokud chceme
používat a implicitně specifikovat příslušný segment, ve kterém se proměnná má
nacházet, můžeme použít modifikátory _es,_ds,_cs,_ss, ale lepší
je se jim vyhnout.
Makro MK_FP: Makro MK_FP "make far pointer"
jak už napovídá anglický význam zkratky, udělá vzdálený ukazatel ze dvou
ukazetelů A:B. Opačně lze získat ze vzdáleného ukazatelele segmentovou a
offsetovou část makry FP_SEG, FP_OFF, fp je far pointer. Umožní rozklad vzdáleného
ukazatele.
Obrazová
paměť (videopaměť):
Teď, když už umíme různé typy ukazatelů a můžeme si tedy ukázat práci s
obrazovou pamětí na PC v textovém režimu. Přímý přístup do videopaměti
zrychluje práci s obrazovkou, než zajišťují pomalé služby OS. Výhoda služeb OS
je univerzálnost a tedy zaručená funkčnost na různých typech grafických karet,
nevýhodou je pomalost.
Popíšeme si obrazovou paměť v textovém režimu 0, počáteční adresa je
0xB800:0 a je rozměrů 80x25 znaků, každý znak je tvořen 2B, prvním je ASCII kód
a druhým je barva. Byte barva je určena pro barvu písma (4 nejnižší bity), 3
bity pro barvu pozadí znaku a 1 nejvyšší bit pro určení, zda znak bliká. V
chráněném režimu je dobré definovat zvláštní selektor ukazující na videopaměť,
zde se ovšem někdy může OS bránit zápisu, proto většinou zde není ani právo
zapisovat někam jinak, než program může. Jedinou možností je buď použít slyžby
OS pro zápis do videopaměti nebo si videopaměť přisvojit. V reálném a chráněném
režimu lze použít nepřímé adresování, které programátoři v Assembleru znají,
ostatní si nemesí dělat moc starosti.
Grafický režim závisí na rozlišení (podle toho je velikost paměti) a počtu
barev. Logicky si můžeme odvodit, jak budeme adresování provádět, raději
použijeme reálný mód, kdy nejsme omezováni s tím, kam můžeme zapisovat a kam
ne.Počáteční adresa většinou bývá na adresa 0xA000:0, ale nelze se na to
spolehnout. Adresace se liší podle maximálního počtu barev, které je možné
současně na obrazovce zobrazit. U 2 barevného režimu připadá na 1B videopaměti
8 pixelů. Podobně u 4 barevného režimu připadá na 1B videopaměti 4 pixely.
Podobně u 16 barevného režimu připadá na 1B videopaměti 2 pixely. Podobně u 256
barevného režimu připadá na 1B videopaměti 1 pixel. Vícebarevné režimy většinou
používají pro 1 pixel 3B, kde je potom možno zobrazit 16777216 barev. To ale
většinou lidské oko ani není schopné rozlišit, proto se asi nejvíce používají
16-ti barevné režimy (protože standartní grafická knihovna graph.h v C++
umožňuje práci s max. 16-ti barvami, pro více barev požaduje
jiný bgi soubor. 256 barevbné režimy se používají nejlépe, protože 1 bod -
pixel je současně 1 B, takže to umožňuje velice rychlou práci pomocí
videopaměti. Přičemž nejlepší je asi režim 320x200 a 256 barev, který se vejde
do 1 segmentu, což umožňuje rychlou práci v Pascalu, C++, Assembleru, je tedy
možné programovat rychlé zobrazení, což dokazují programátoři her.
Práce
s dynamickými proměnnými:
Pro alokování paměti v C a C++ lze použít funkci malloc, jejíž
prototyp lze nalézt v hlavičkových souborech alloc.h a stdlib.h. Vrací void *.
Syntaxe: void * malloc(velikost);
V C lze napsat:
int *ui;
void main() { ui=malloc(10*sizeof(int));
}
Ale v C++ nelze tento zápis přeložit, protože C++ neumí konvertovat (nebo je
to ochrana proti chybám), takže je nutné napsat:
int *ui;
void main() { ui=(int*)malloc(10*sizeof(int));
}
Po alokování paměti je tam smetí. Dynamicky alokovaná pamať se nenuluje!
ui[5]=11; zapíše do 6. prvku pole hodnotu 11 (v C, C++ jsou pole indexované od
0).
Poznámka přednášejícího: Chtěl jsem použít již naprogramovanou
knihovnu s Fourierovou transformací, která byla převzata z jiného
programovacího jazyka (asi Fortrana). Ale nějak to nefungovalo a tak jsem
hledal v čem je chyba. Po několika hodinách jsem chybu objevil a zjistilo se,
že prý nějaká podřadná pracovní síla přepisující programy z Fortranu do C
nevěděla, že v C se indexují pole od 0, takže tím byl i špatný výsledek.
Moje poznámka: Proto je dobré si dávat pozor na všechny to, co používáte.
Většina programátorů nechce něco programovat a raději použije cizí dílo, ovšem
přepisem ani většinou ani neotestuje, zda to funguje, protože si asi myslí, že
v tom nelze udělat chybu. Domýšlivost se nevyplácí. To znám také ze zkoušek na
FJFI, kde můžete být někdy, když riskujete i vyhození, takže někdy je lepší si
nechat napsat horší známku (3) nebo riskovat na lepší známku, ale zde opět
hrozí nebezpeší, že můžete (občas se také stane) něco, s čím si nevíte rady.
Ale někteří zkoušející jsou rádi, když nemusí dát všem jenom 3 a když mohou dát
i lepší známku. Ostatně to je jen na Vás. Většinou je ovšem jednoduché dostat
dvojku, na jedničku byste asi měli umět i důkazy vět a více rozumět tematice.
Zkoušející na zkouškách ostatně pozná, jak Vás to naučil a také vy poznáte co
umíte a neumíte. Většina zkoušejících je ovšem dobrá, že Vám nechce dokazovat,
co neumíte a tak Vám to na zkoušce vysvětlí, takže není se vlastně čeho bát.
Zrušení dynamicky alokované paměti: Provede se funkcí free.
Syntaxe free(ukazatel).
Opakování: Paměť lze dynamicky alokovat buď pomocí new
a rušit pomocí delete nebo pomocí malloc a rušit
pomocí free.
V C se používá calloc, c znamená programovací jazyk C, která
původně vracela char *, protože neexistoval void *, kde jako parametry jsou
počet položek a velikost jedné položky v B. Všechno si lze zjistit v nápovědě,
stiskem Ctrl+F1, po napsání calloc v editoru a umístěním kurzoru. Nebo Shift+F1
v indexu.
Rozděluje se ještě alokace ze vzdálené haldy: far malloc a far
free. Vždy se tu používá vzdálený ukazatel.
Zjištění velikosti volné paměti v haldě: Použije se funkce coreleft.
Viz nápověda.
Kopírování dat: Použijeme buď funkce movedata nebo movemem.
Liší se typem parametrů, které lze zjistit v nápovědě, movemem se umí vypořádat
se situací, kdy se kopírované pole překrývají.
Objekty
a ukazatele:
Příklad ukazatele na objekty. Zkusíme s pomocí ukazatele vyvolat metodu
vypis().
Class X{int x,y; public: vypis();};X *ux;
(* ux).vypis();
ux->vypis();
tečka má vyšší prioritu než *, proto bylo nutné napsat (* ux).
struct - záznam bez variatní části
unie - záznam pouze s variatní částí
Poznámka k hlavičkovým souborům: Někdy je problém, aby se hlavičkový
soubor nenatahoval vícekrát do paměti, jelikož by to mohlo způsobit, že některé
tělo fuknce by bylo uvedeno vícekrát, což způsobí chybu při překladu: Řešení:
#ifndef _TYP_H_
#define _TYP_H_
typedef int T;
#endif
Pokud není makro TYP_H_ definováno, potom se vytvoří a deklaruje se nějaký
typ nebo se vloží jiná deklarace či hlavičkový soubor. Vytvořením makra je už
řečeno, že to bylo již definováno, takže pokud je stejná deklarace v jiném
hlavičkovém souboru, makro již existuje a deklarace nebo natažení souboru bude
přeskočeno.
Konstruktor: Konstruktor provádí inicializaci objektu. Máme objekt T:
class T {T(int d=0);};T::T(int d) { };
V objektu T máme konstruktor T, můžeme ho tedy volat s parametrem typu int
nebo také bez parametrů.
Seznam: Popíšeme si příklad seznamu. SEZNAM.CPP (na serveru katedry
matematiky) obsahuuje implementaci seznamu, SEZNAM.H - obsahuje hlavičky funkcí
pracujících se seznamem. Je zde definován ukazatel "hlava", který
ukazuje na začátek seznamu. Seznam je definován jako seznam bez zarážky, viz
základy algoritmizace (1.ročník na FJFI).
Několik poznámek k prográmku. << má vyšší prioritu než ?:, proto se musí
uzávorkovávat.
Seznam je použit v programu na vyplňování plochy uzavřeného mnohoúhelníku,
zadaného jeho vrcholy.
Koho prográmek zajímá, může si stáhnout archiv zde.
Program je dost komentovaný, pro pochopení principu vyplňování mnohoúhelníku
dopuručuji navštěvovat program počítačová grafika - ing. Milota. FJFI pro 4.
ročník Tvorba software (ale přednáška je volně přístupná pro ostatní zájemce...).
Funkce
jako parametr funkce:
Funkce předávaná jako parametr funkce: Rovněž se musí zapsat void
(*uf) (int,int) kvůli prioritě., což je vlastně ukazatel na funkci, která nic
nevrací a má 2 parametry. Lze tak předat funkci jako paramětr. Je potom možné
přiřazení uf=g; g je nějaká funkce, která nic nevrací a mající dva parametry
int. Funkci je potom možno volat dvěma způsoby: uf(10,15); funguje pouze v C++,
(*uf)(10,15); funguje i v C i v C++. Další příklady definice: int * f() nebo
int(*f())[5] tedy vrací ukazatel na pole kvůli prioritě. Funkce může vracet
referenci, což je vlastně skoro jako vracení proměnné odkazem.
Další povídání o funkcích následuje v kapitole o funkcích.
Rekurze:
Rekurzí nazýváme volání funkce, pokud volá sama sebe. Rekurzi
známe z Pascalu a hezké použití (ikdyž ne moc inteligentní) je definice
faktoriálu. Z matematické analýzy nebo diskrétní matematiky známe posloupnosti
zadané rekurentně, takže pokud chceme spočítat něco zadaného rekurentně, musíme
spočítat všechny předchozí členy posloupnosti. Pokud chceme tedy spočítat
faktoriál n!, potom musíme znát faktoriál (n-1)! a vynásobit ho n (podle
definice), ale pokud ten neznáme (což zpravidla neznáme), potom musíme spočítat
faktoriál (n-2)! a vynásobit ho n-1, tak získáme (n-1)! a po vynásobení n
získáme n!. Tímto způsobem lze odvodit, že n! se skutečně rovná 1.2....n. Ale
jak jsme si již uvedli na začátku příklad faktoriálu,
je jasné, že někdy se podaří odstranit rekurzi, někdy je to tak obtížné, že
výpis programu by se dost zkomplikoval.
Rekurentní volání fuknce: Nechť máme funkci int f(int a, int b) { int
c; } V tomto případě a,b,c neexistují, dokud se funkce nezavolá, což je stejné
jako v Pascalu. Pokud si přejeme, aby c existovala pořád (a nebyla znovu
vytvářena a rušena), deklarujeme ji jako static: static int c; Potom bude
proměnná c existovat po celou dobu běhu programu. Ovšem není k ní možný přístup
vně funkce, ve které je definována. Pozor - zrada: Při rekurentním volání se
přemaže, neboť se znovu nevytváří, jak jsme si řekli. Proto je nutné zacházet s
ní opatrně.
Paměťové
třídy:
Paměťová třída auto je ještě pro některé neznámá. Nyní už
nebude, protože jí vysvětlím. Překladač si u třídy auto třídu doplní sám.
Paměťová třída static je už trochu známá, používá se ve
funkcích, pokud si nepřejeme, aby proměnná přestala existovat po opuštění
funkce. Po dalším volání funkce se proměnná již nevytvoří, protože existuje od
minulého volání a pokud ještě funkce nebyla volána a proměnná se nevytvořila,
tak se vytvoří. Proměnná přesto není známa mimo tělo funkce.
Paměťová třída extern se používá pro deklarování proměnné,
která má být použitá, aby byla vidět mezi soubory. Mám na mysli například
proměnnou, která se nachází někde v již přeloženém obj souboru, což lze použít
v projektu, kdy dáme k dispozici pouze hlavičkový soubor a přeložený obj
soubor. Pokud tedy má být nějaká proměnná vidět z přeloženého obj souboru,
potom se zpravidla používá deklarace extern tak, aby se proměnná dala používat.
Paměťová třída register je pouze doporučení pro
překladač, že by mohl dát proměnnou do registru. Je jasné, že je to pouze
doporučení, protože nějaké obrovské pole nelze narvat do malého registru. Proto
je to pouze doporučení pro překladač, že by to mohl udělat. Ale ve většině
případů to pozná sám překladač a narve jí do registru sám, aby se urychlilo
provádění programů.
V Optimalization Options lze nastavit:
- None - zakázání - což je
dobré při ladění, neboť pokud je proměnná v registru,potom ji nelze
zobrazit v Debuggeru.
- Register Keyword - což
znamená, že se použije, pokud se uvede klíčové slovo register. Musí být
ovšem volné místo pro uložení proměnné, jinak to nepůjde.
- Automatic - překladač je
bude vkládat, když to uzná za vhodné (to ještě neznamená, že překladač
dokáže myslet), pokud je to nějaká ze situací, kdy je to možné a urychlilo
by to provádění programu
Rekapitulace: Paměťová třída auto může být lokální proměnná nebo pro
parametr funkce. Proměnná static může být globální nebo na úrovni souboru,
potom je vidět pouze v tom souboru. Deklarací proměnná extern je řečeno, že
proměnná e definovaná jinde (nejspíš v nějakém obj souboru). Proměnná register
je rada: Zkus vložit do registru.
Je možné definovat i externí funkci: extern int f(); V některých situacích
lze extern vynechat, ale většinou je dobré napsat extern, potom se zvětší
pravděpodobnost, že by mohl jít program přeložit a spustit. Lze také definovat
funkci static: static int f(int); Použití je dobré, pokud chceme, aby byla
funkce vidět pouze v tomto souboru, pokud je program rozdělen na více částí do
souborů.
Return -
pokračování:
O příkazu return jsme si již něco řekli. Zopakujeme si
to, pro případ, že by to někdo zapomněl. Nechť máme tělo funkce. void f(...) {
... } Funkce f se ukončí přechodem přes } nebo příkazem return. V Pascalu máme
výstup funkce, že uložíme hodnotu do proměnné, která se jmenuje stejně jako
funkce, čímž se ale v Pascalu funkce ještě neukončí a pokračuje dál. Ale zde v
C resp. C++ se funkce příkazem return ukončí, ať už je to ve funkci, která
vrací nějakou hodnotu (return hodnota;) nebo ve funkci bez výstupu (v C resp.
C++ se nepoužívá výraz procedura), potom se hodnota nevrací (return;). Ve void
f nelze vrátit hodnotu a opačně.
V C nelze definovat funkce se stejným jménem. V C++ to lze, nazývá se to
přetížení funkcí. Funkce se musí lišit typem parametrů, ale ne nikoliv výstupní
hodnotou, to pro odlišení funkcí nestačí (zapřemýšlejte proč). Pokud jste na to
nepřišli, je to proto, že funkci můžeme volat tak, že její výstup zahodíme,
takže by překladač nevěděl, jakou chceme z nich volat. Také dalším důvodem je,
že zde probíhají konverze a to by také nestačilo k rozlišení, kterou funkci
vybrat.
V C neexistuje předávání proměnné odkazam. Je možné pouze předat ukazatel na
proměnnou. Ukážeme si, jak je nutné naprogramovat v C swap:
void swap(int *a, int *b) { int c = *a; *a=*b; *b=c;
}
void main() { int y=11, z=98;
swap(&y,&z);
}
Důsledek toho, že v C neexistuje předávání proměnné odkazem je knihovna
graph.h, která byla přenesena i do C++. Proto se i v C i v C++ při použití
knihovny <graph.h>, použije initgraph(&gd,&gm,"..."); -
v Pascalu bylo initgraph(d,m,'...');.
Reference:
Reference je skoro jako předávání proměnné odkazem.
Uvedeme si příklad funkce swap, kterou naprogramujeme dvěma způsoby, první
možnost je spíše z C než z C++, protože se pracuje s ukazately na proměnné (v
minulé kapitole jsme si řekli, že C ještě nemá předávání proměnných odkazem,
takže je nutné předávat ukazatel na proměnnou). Druhý příklad funkce swap1 je
naprogramována pomocí proměnných předávaných odkazem - reference,
takže je určena pouze pro C++.
void swap(int *a, int *b) { int c = *a;
*a = *b;
*b = c;
}
void swap1(int &a, int &b) { int c=a;
a=b;
b=c;
}
void main() { swap(&y,&z);
swap1(y,z);
}
Poznámka: Ještě něco o práci se segmentovou částí ukazatelů. Význam
je jasný z příkladu, máme globální proměnnou i a lokální proměnnou (definovanou
ve funkci main()).
int __seg *s;
int i;
void main() { int j;
s=int(__seg*)&i;
s=int(__seg*)&j;
}
Další povídání o referencích je zde.
Implicitní
hodnoty parametrů:
Funkce - rozdíly C a C++: Pokud máme definovanou funkci void f(inz a,
int b, int c) {.....}, potom jí můžeme zavolat např. f(3,4,5); Ukážeme si, jak
je možné deklarovat funkci, aby bylo možné vynechat některý z proměnných.
Ve Fortranu je např. funkce graphor, která umožňuje práci s grafikou.
graphor(1,.....) je asi otevření grafiky a za ním parametry, graphor(2) zavření
grafiky. My nyní chceme něco podobného naprogramovat. V minulých příkladech
jsem to asi již použil, ovšem to nebylo vysvětleno. Ukažme si to na deklaraci
následující funkce h:
int h(int x, double y=3.7, int *r = &i) { ..... } Funkci můžeme volat
následujícími způsoby:
h(3,d,&j) normální volání
h(3,d) ... pokud ji takto zavoláme, překladač za chybějící parametr doplní
implicitní hodnotu (proto se to tak jmenuje), která je určena v hlavičce funkce
typu int *r = &i. Pokud tedy parametr chybí, potom se doplní chybějící
parametr. Potom to bude mít stejný účinek jako volání h(3,d,&i);
Metoda implicitních parametrů se používá ve Windows, např.
create window.
Moje poznámka: Má prý tolik parametrů, které není v lidských silách
si je zapamatoval. Proto existuje vnější paměť, metoda vnější paměti se
osvědčuje, protože všechno se asi do mozku nedá nacpat, takže u zkoušek se
občas hodí taháky, tedy pomocné papíry.
Metoda implicitních parametrů je výhodná v tom, že není třeba všechny (jako
otrok) opisovat. Má to ovšem nevýhodu v tom, že pokud u nějakého parametru dáme
implicitní hodnotu v hlavičce funkce (tedy umožníme jeho vynechání), potom musí
mít všechny další také implicitní hodnotu. Rozmyslete si proč.
Moje poznámka: Pokud jste ovšem již unavení a přemášlení jaksi nejde,
tak se snažte se vzchopit a nyní dávejte pozor, pokud jste si to nerozmysleli.
Kdo má uši, tak slyš: Pokud tedy bychom vynechali nějaký parametr (měl by
nějakou implicitní hodnotu), potom by se z toho překladač asi zbláznil, protože
zpracovává parametry zleva doprava a vynecháním parametrů by se všechny další
parametry posunuly doleva, takže by již neseděky ani typy parametrů. Proto
vynechám-li nějaký parametr, potom musím vynechat všechny následující
parametry, takže pokud nějaký parametr má implicitní hodnotu, potom musí mít i
další implicitní hodnotu.
Nesmíme opakovat deklaraci implicitních parametrů, tzn. že pokud máme něktde
již hlavičku a jinde tělo funkce (např. v objektech, tam máme v objektu
hlavičky metod a dále implemetaci), takže jim v hlavičce implementace funkce už
nesmíme uvést implicitní parametr (vlasně to můžeme, ale takový program se
nepřeloží bezchybně).
int f(int = 33);
// ....
int f(int y) { return y+9;
}
void main() { int i=f();
}
Pokud nějaká funkce nemá parametry, je dobré napsat f(void). Většinou je to
ovšem stejné jako f(). V C se někdy říká, že je to fuknce, o jejichž
parametrech nehovoříme. V C++ se říká, že je to funkce bez parametrů.
Proměnné typu char, float, enum, bitové pole se konvertují na int nebo
unsigned int
V Kerningham C (no zde mají výhodu ti co četli úvod, někdy je dobré si
přečíst alespoň úvod a historii C a C++) jsou funkce bez prototypů, nemůžou mít
parametry typu char, float a výčtové typy. Ovšem co je povoleno a co je
zakázáno, to ukáže konkrétní překladač.
Podle definice Kerningham - Richie existuje jakási definiční deklarace.
Ukážeme si to na příkladu:
int f(a,b,c)
int a,b;
double c;
{
}
C toto toleruje, ale je to zakázáno pro metody objektových typů. Pokud zde
nespecifikujeme typ proměnné (jako většinou) si program doplní int. Jako
nevýhoda se někdy uvádí, že nezná typy parametrů a neumí je převést. Je to
náchylnější k chybám, které překladač asi neodhalí.
Výpustka:
Pod pojmem výpustka máme na mysli něco jako, že vynacháme
parametry funkce nebo také že je možné volat funkci s libovolným počtem
parametrů. Počet parametrů by měl být konečný (nekonečný počet parametrů by
žádný sebelepší počítač nebyl schopen za konečnou dobu přeložit, také je tu
omezení paměti, hlavně zde v překladači BC 3.1 v DOSu, kde máme 640 kB základní
paměti a část extended/expanded memory.
Příkladem výpustky v C++ resp. C je funkce printf. Proto může mít libovolný
počet parametrů libovolného typu. Zatímco toto bychom v Pascalu těžko
vymýšleli, jak deklarovat funkci s libovolným počtem parametrů, toto je v C++
možné. Citát ing. M. Virius: "Co si může v Pascalu dovolit autor
překladače, to si už nemůže dovolit jeho uživatel." V tento okamžik byla
totiž řeč o naprogramování write, writeln v Pascalu, kde je možný libovolný
počet parametrů, což ovšem mohl udělat autor překladače, ne však jeho uživatel.
Další citát: "Zde v C++ platí, že to, co si může dovolit autor překladače,
může si dovolit i uživatel. Uživatel si může skoro všechno naprogramovat
sám."
Příklad: int printf(char * format, ...);
Upozorňuji a zdůrazňuji, že teď jsou ty tři tečky skutečné (neznamenají
příkazy či parametry), ale takto se deklaruje výpustka. Říká se, že zde mohou
být libovolné počet parametrů libovolného typu. Dále je třeba upozornit, že
funkce s výpustkou musí mít alespoň jeden pevný parametr. Většina uživatelsky
definovaných funkcí s výpustkou mají jako první parametr počet parametrů, ale
není to nutné, neboť printf tvoří vyjímku, ta má jako první formátovací
řetězec. Ale v tomto formátovacím řetězci jsou uvedeny typy proměnných (takže
to udává i jejich počet), takže se z toho lze dozvědět počet parametrů a jakého
jsou typu. Jinak totiž ve funkci s výpustkou není možné kontrolovat typy
parametrů, neboť vše je necháno na uživateli, že ten ví, jak se má funkce
volat, což překladač předpokládá (někdy je to ukvapený předpoklad, ale to se
překladač nedozví, dozví se to uživatel, pokud se mu v printf vypisují podivné
údaje, tak z toho usoudí např. že typ proměnné ve formátovacím řetězci printf
není stejný jako typ proměnné, jež se předává za formátovacím řetězcem.
Probíhají konverze float -> double
Pro práci s výpustkou je určen hlavičkový soubor <stdarg.h>.
Příklad: int max(int n,...) Tuto funkci hledající maximum konečného počtu čísel
se může volat např. proměnná=max(3,a,b,c); Je nutné dát vědět, kolik parametrů
je na zásobníku a kolik se má vyzvednout. Parametry je třeba tedy všechny
vyzvednout a vědět jakého jsou typu. Ale jak jsme již uvedli, překladač
nekontroluje (ani to nějak nemůže), jaké jsou parametry a jakého jsou typu.
Ukážeme si schematicky znázornění stavu zásobníku.
Na záčátek zásobníku ukazuje v reálném módu registr SS (stack segment), v
Borland C++ 3.1 ukazuje na vrchol zásobníku BP. Potom se tak uloží 3 a všechny
parametry funkce, které jsou nutné před vyvoláním funkce.
A nyní si konečně ukažme, jak se z výpustkou pracuje: Jak jsme již řekli,
základem je použití stdarg.h.
- Musíme definovat nějakou
proměnnou typu va_list: va_list ap; (nevím to určitě, ale
asi to bude zkratka od variable list). Bez toho bychom nemohli s parametry
funkce pracovat.
- Nezalekněte se toho. Nyní
se provede jaká si inicializace, k tomu slouží funkce va_start(ap,PosledníPevnýParametr);.
Od posledního pevného parametru začne počítač brát všechny parametry jako
parametry na které bude použita metoda výpustky, jinými slovy: S dalšími
parametry se bude zacházet pomocí proměnné typu va_list, to je důvod, proč
jsme si ji deklarovali.
- Teď již můžeme vybírat
jednotlivé parametry (nejspíš v cyklu) příkazem va_arg(ap,TypProměnnéKteráSeBudeVybírat);
- Symbolické zakončení práce
s výpustkou se provede příkazem va_end(ap); Co tento příkaz
opravdu dělá, ví snad jen autor překladače resp. vševědoucí
a všemohoucí Bůh, ale skutečně je programátorskou slušností použít
va_end.
Nyní můžete kliknout sem a vyzkoušet si
demonstrační příklad: V tomto příkladu je také ukázáno, co se stane, pokud
nerespektujeme, že funkce počítá maximum pouze pro čísla int. Potom se
samozřejmě počítá maximum ze špatných čísel.
Pokud například potřebujeme, aby se v oknu Debug zobrazovalo u proměnné typu
char místo čísla znak, potom tam můžeme zapsat: char(i), kde i bude proměnná
typu char.
Zde ve výpustce se char konvertuje na int. Při výpustce překladač neví s
kolika a jakými parametry bude funkce volána.
Vytvoření funkce
v C, C++ pro Pascal:
V C je za úklid parametrů zodpovědný volající. Protože volající ví, co tam
na zásobník nacpal, takže musí vrátit zásobník v takovém stavu, jaký byl před
voláním. Většinou bystě měli vidět v přeloženém programu SUB SP, POP CX, RET n
- což znamená, že při návratu vytáhni ze zásobníku návratovou adresu a n bytů.
V Pascalu je opačné ukládání parametrů na zásobník, takže pokud si přejeme
vytvořit funkci, kterou budeme chtít používat v Pascalu, potom existuje
možnost, že v deklaraci funkce v C resp. C++ napíšeme:
VracenýTypProměnné pascal jméno(parametry) { tělo funkce };
Toto způsobí, že parametry se budou ukládat v opačném pořadí do zásobníku,
takže skutečně půjde funkci použít v Pascalu. Je tu ovšem problém, že C++
značně komolí jména funkcí, takže někdy Pascal ohlásí, že funkce nebyla
nalezena v přeloženém obj souboru. Mimochodem jméno funkce se komolí podle typu
parametrů (funkce může být přetížena, takže se nějak musí od sebe odlišit),
přidávají se tam mnohé znaky (mimochodem, koho to zajíma, ať se podívá do
přeloženého obj souboru). Proto doporučuji místo C++ použít C (soubor si místo
*.CPP pojmenujete *.C a v Options - Compiler - C++ options - v přepínači Use
C++ compiler ať je zvoleno: CPP extension). C méně (skoro jen někdy) komolí
jména, takže je to mnohem jednodušší. Kdysi jsme si na přednášce Programování v
Pascalu ukazovali příklad převodu programu z C resp. C++
do Pascalu. Opačný převod asi není možný (asi
podvodem), protože Pascal asi neumožňuje generovat *.obj a com soubory (pouze
*.exe). Je však možné v C i v Pascalu používat *.obj soubory vytvořené v
Assembleru. Ovšem programování v Assembleru je zdlouhavé a nudné, lze však
vytvořit krátké programy. Ikdyž někdy i v C lze naprogramovat krátký program,
vhodné pro rezidentní programy.
Zopakujeme si: Funkci pro Pascal tedy deklarujeme např. int pascal
f(parametry) { ....... } Úmyslně jsem napsal do { } vce než 3 tečky, aby se to
nepletlo s výpustkou, která má právě 3 tečky. Někdy lze použít i deklaraci
typu: int __pascal f(............) {.............}; To asi v případě, že první
způsob nepůjde. Obě deklarace by mělo být asi stejné.
Komolení
jmen v C, C++:
Důvodem komolení jmen v C++ je, že funkce mohou být (a zpravidla také jsou)
přetížené. Ovšem program v C++ se překládá do assembleru (v Options - Compiler
- Code generation - v zaškrtávacích políčkách Options - Generate assembler
source lze zvolit generování programu v Assembleru, vytvořený program bude mít
stejné jméno jako program *.C resp *.CPP a bude uložen do Output directory).
Ale v Assembleru však není možné přetěžovat funkce a procedury (tak dokonalý
Assembler není ani Pascal), takže je nutné rozlišit funkce různými jmény podle
parametrů.
Situace komolení jmen si ukážeme u překladače Borland C++ 3.1 (u jiného
překladače jsme si to totiž na přednáškách (Programování v C++ - ing. M.Virius,
Csc.) neukazovali, takže si to ukážeme jen na tomto překladači.
- Název funkce se převede
na velké písmena. Nechť je malé x název funkce v C++ (zde platí i pro C).
Potom prvním krokem se převede na _X. Pokud je název funkce velké X, potom
zůstane velké X.
- Druhým krokem (další
kroky jsou už jen pro C++, které umožňuje přetížit jména funkcí, C to
ještě neumí, takže další kroky tudíž logicky nemají smysl u C). Na začátek
se přidá @ a na konec $. Takže to bude takto: @f$kódy typů parametrů.
Písmenka zde mohou být například: q-následující parametr, i - int, d -
double, v - void - bez parametrů. Nazývá se to buď zdobení jmen
nebo komolení jmen.
- U objektových funkcí -
metod, se ještě přidá, ke kterému objektu patří. Výsledek potom může být
@max$qil. Takto se jména exportují v *.obj souboru.
Důvodem existence Pascalovské volací konvence je, že funkce ve Windows
používají Pascalovskou volací konvenci.
Jazyková třída - modifikátor:
- __fast call - některé
parametry se pokus dát do registrů
- __stdcall - ve Win 32
- __syscall - pro OS2
- __cdec - bližší informace
v nápovědě, je jen zde uvedeno, abyste věděli, že něco takového existuje
Parametry
příkazové řádky:
Při spuštění programu se některé programy spouštějí s parametry. Například
známe dir jméno souboru, command.com /c příkaz DOSu, help jméno příkazu, BP a
BC jméno souboru, které chcete nahrát do editoru. Parametry programovacích
jazyků může být nastavení prostředí. V Borland C++ a Borland nebo Turbo Pascalu
existuje překladač jako samostatný EXE soubor, ten se také ovládá pomocí
parametrů z příkazové řádky. Chci tím naznačit, že by bylo dobré, kdybychom ty
parametry uměli nějak zjistit a podle toho udělat něco ve svém uživatelském
programu v C resp. C++. Budeme se bavit o překladači Borland C++ 3.1 pracující
v DOSu.
Parametry z příkazové řádky dostaneme tak, že ve funkci main mohou být
parametry. Zatím jsme je nepotřebovali, proto jsme psali main() bez parametrů.
Nyní budeme psát:
int main(int argc, char ** argv, char ** env)
argc je zkratka argument count, tedy počet parametrů
argv je ukazatel na pole parametrů DOSu (??? jak je to u jiných OS, to
nebylo na přednášce řečeno.)
env je ukazatel enviropment, tedy systémových proměnných DOSu. Ukážeme si demonstrační prográmek, který si můžete
stáhnout.
int main(int argc, char ** argv, char ** env) { for (int i=0; i<argc;i++) cout << argv[i] << endl;
return 0;
}
Pokud si přejeme, aby parametr s mezerou byl brán jako 1 parametr, je dáme
do uvozovek, např. "a b n", potom se budou brát jako 1 parametr.
Parametr 0 je vždy jméno spuštěného programu. Ukazatel end je ukazatel na kopii
systémových proměnných.
Tato kopie systémových proměnných je uložena v tzv. PSP - program segment
prefix - česky: předpona programového segmentu. Tuto část si mohu změnit sám
pro sebe, např. path, avšak původní systémové proměnné se tím neovlivní,
protože je to pouze kopie. Každá položka je ukončena znakem s ASCII kódem 0,
protože je to řetězec v C++, poslední položka je ukončena 2x ASCII kódem 0.
Modifikátor
inline:
Některé funkce jsou tak krátké, že se už vyplatí je nevolat, ale vyplatí se
dát jejich těla na místo volání, místo toho, aby tam skok. Jedná se pouze o
doporučení, stejně jako register. Modifikátor inline tedy
doporučí překladači, aby místo skoku do funkce, vložil jej tělo na místě
volání. Odpovídá to skoro jako makrům v C++ a je to stejné jako makra v
makroassembleru. Pouze s tím rozdílem, že se zde jedná o funkce a ne makra.
Poznámka k vraceným hodnotám funkcí: Funkce nemůže vracet pole ani
funkci, je možné je však vracet jako referenci, ukazatel který se
dereferencuje.
Reference vytváří L hodnotu, kterou lze napsat na levé straně přiřazovacího
příkazu. L je jako levý, left, protože je na levé straně přiřazovacího příkazu.
Následující příklad ukáže, jak je možné
naprogramovat něco jako indexování. Tento jednoduchý prográmek by bylo možné
například upravit pro kontrolu mezí.
Používání
funkcí pro C v C++:
Poznámka: Pokud chci v C++ používat knihovnu z C: extern
"c" void clrscr(); Napíšu název funkce, kterou chci používat.
Pokud je více funkcí, potom napíšu: extern "c" { ......... }. Pokud
se podíváte na nějaký hlavičkový soubor, potom tam něco takového uvidíte.
Standartní hlavičkové soubory jsou v adresáři: BC31\INCLUDE
Příkladem jsou hlavičkové soubory conio.h, math.h, které chceme používat jak
v C tak i v C++. Proto byste tam měli vidět něco takového (je to tam trochu
složitější...):
#if def __cplusplus
extern "c" {#endif
double sin(double);
double cos(double);
#if def __cplusplus
}
#endif
Toto se přeloží v C++ takto: (Tam je definováno makro _cplusplus.)
extern "c" { double sin(double);
double cos(double);
}
Pokud se to překládá kompilátorem C, potom se to přeloží takto: (Není
definováno makro _cplusplus.)
double sin(double);
double cos(double);
Pokud napíšeme extern f(int); a vynecháme vracený typ, potom si překladač
doplní int, ovšem je lepší se tomu vyhnout a raději tam typ psát, je to totiž
programátorská slušnost. Takto definovanou funkci potom můžeme použít i v
jiných modulech. Stejně jako pokud napíšeme: const c=11; i zde se doplní int.
C, C++ nedovoluje vnořené funkce - lze napsat pouze prototyp.
V Trojance na síti je prográmek na obsluhu přerušení.
K tomu si, že existují modifikátory near, far, huge pro všechny
typy ukazatelů, které jsme si tu uvedli. Můžeme předepsat funkci jako blízkou
(funkce se bude volat pouze offsetem - 2B adresa) nebo vzdálenou (funkce se
bude volat pouze offsetem a segmetem - 4B adresa).
Adresa je tedy blízká nebo vzdálená. Blízká volání jsou rychlejší, protože
se předává pouze offset, kdežto u vzdálené se předává offset i segment. V
Assembleru známe instrukce call near a call far. V C resp. C++ se volání
projeví v knihovnách, které mají všechny funkce vzdálené. Proto je nutné napsat
far.
Poznámka - Pascalovský typ Boolean: Z Pascalu známe proměnnou
reprezentující logické hodnoty 0 = False, 1 = True. V C ani v C++ není
definován tento typ (snad s vyjímkou nejnovějších překladačů). Ale to nevadí,
lze si ho dost dobře definovat například takto: enum bool (false=0,true);
Logická nula bude 0 a logická jednička bude 1, jak jednodušeji to definovat?
Funkce:
Něco málo jsme si již řekli o předávání funkce
jako parametru funkcí.
Existují dvě definice (zatím jsme mohli programovat, aniž bychom znali
nějaké definice) a to pole Kerningham a Ritchie a podle normy ANSI. Také
pravděpodobně známe, jak předávat parametr hodnotou (normálně) a odkazem (v C++
pomocí referencí &). Dále také asi známe, že
výsledek je možné vracet hodnotou (normálně) nebo odkazem (opět použijeme referenci).
Dále asi víme, že existují rozdíly mezi C a C++, proto, pokud
chceme použít v C++ funkci z C, zadáme extern "c", což lze použít
jak pro proměnné, tak hlavně pro funkce. Ale v hlavičkových souborech to již
udělali za nás, takže se tím nemusíme zabývat. Pouze když budeme programovat
vlastní funkce a chceme je používat jak v C tak i v C++, potom je dobré si
udělat svůj vlastní hlavičkový soubor, který již rozliší, zda překládáme
překladačem C nebo překladačem C++, vyřeší se to podmíněným
překladem, jak je to, již jsme si uvedli a můžete se na to mrknout ve
standartním adresáři hlavičkových souborů (tedy pokud jste si ho
nainstalovali).
Také známe inline, což slouží jako doporučení, že se má
funkce místo skoku vložit její tělo na místo volání. Dále známe oarametry třídy
auto a register, také
známe blízké a vzdálené funkce near a far. Také víme,
jak deklarovat implicitní hodnoty pro parametry.
Dále umíme také pracovat s výpustkou, jejíž
hlavičkový soubor je stdarg.h. Víme, co jsou funkce va_list ap;, va_start, va_arg
a va_end.
Nyní ještě malé doplnění k parametrům typu funkce. Příklad:
void f(int i) { cout << "ahoj";
}
void (*Fun)(int);
Fun=f;
Někdy musím volat ukazatelem na funkci s tímto prototypem. Příklad také
ukázal, jak je možné přiřazení proměnných typu funkcí. Řekli, jsme si také, že
i funkce bez parametrů je nutno volat f() (narozdíl od Pascalu, kde je zápis
f() nepřípustný). Také jsme si něco řekli o rekurzi.
Příklad: ZAKL\07\INTEG.CPP - předávání funkce jako parametr. Prográmek
má za úkol vypočítat určitý integrál funkce zadané jako parametr. Funkce pro
integrování je univerzální a jejím parametrem je libovolná matematická funkce,
která má nějaký rozumný výstup. Počítá integrál s předepsanou přesností.
Ikdyž se nepodařilo nakreslit obrázek se stejnou šířkou obdélníků, měly by
skutečně být stejně široké. Máme tedy nějaký interval a na něm definovanou
funkci. Integrál se počítá touto známou metodou - obdélníkovým pravdilem.
Určitý integrál je roven ploše mezi osou a křivkou. Proto lze ho spočítat také
tak, že plochu rozdělíme na obdélníky a jejich plochy již umíme sečíst. Přitom
kdyby byly nekonečně malé (limitně nulové), dostali bychom přesné numero,
odpovídající ploše mezi křivkou a osou - tedy určitý integrál v intervalu
<a,b>. Takto stručně byla popsána metoda obdélníkové pravidlo.
Velký matematik by řešil problém odlišně. Vzal by si funkci, zintegroval by
a pokud by se mu to podařilo (což nelze zaručit), čímž by získal tzv.
primitivní funkci. Plochu by potom získal jako rozdíl primitivní funkce v bodě
b, od které se odečte hodnota primitivní funkce v bodě a. Největší problém je
ovšem nalézt primitivní funkci k zadané funkce. Matematik (pokud by se ovšem
dopracoval k výsledku a nestrávil nad integrací mnoho bezesných nocí), by zcela
jistě získal skutečně přesný výsledek, protože počítání na počítači přináší
chybu, která se přičítá k mnoha dalším chybám.
Zvolíme poloviční krok, pokud je rozdíl menší než e, potom přesnost je menší
než e. Potom již počítám jenom hodnoty mezi, protože ty ostatní již mám
vypočítané. Takovýto postup zmenšování obdélníčků bychom mohli dělat tak
dlouho, dokud máme malou přesnost. Uvedeme si ještě hlavičku funkce pro
integrování.
double Integral(double a, double b, double (*f)(double)) { ............. };
Funkci potom použijeme například: cout << Integral(0,M_PI,sin) <<
endl; nebo cout << Integral(0,1,&F) << endl; kde F je nějaká
speciální funkce.
HUGE_VAL - udává největší zobrazitelnou hodnotu v double.
Odpovídá to nekonečnu, se kterým je schopen počítat. Pokud tedy tuto hodnotu
něčím vynásobíme, vyjde nám opět, podobně když k ní něco kladného přičteme,
vyjde nám také tato hodnota. Chová se jako matematické plus nekonečno.
Číslo Pí: Pokud chceme zapsat tuto hodnotu, musíme natáhnout
hlavičkový soubor MATH.H. Konstanta se jmenuje M_PI, napsáním
M_PI a stiskem Ctrl+F1 získáte i označení násobků čísla pí.
Enviropment -
proměnné DOSu:
Příklad: ZAKL\00\MAIN.CPP: Program slouží k vypsání proměnných DOSu.
Posledním prvkem je nulový řetězec, který obsahuje jen znak s ASCII kódem 0
(takže jsou 2 znaky s ASCII kódem 0 za sebou, protože každý řetězec má nakonci
znak s ASCII kódem 0), což je možné testovat jako druhý parametr ve for.
Jednoduché? Přičemž char * * env je ukazatel na pole charů - řetězců. Primitivní příklad by mohl vypadat nějak takto jako tento
příklad. Další hezký příklad je u příkazu getenv a putenv v nápovědě
Borland C++ 3.1.
Přerušení a
obsluhy přerušení:
Mnoho programátorů používá C resp. C++ pro programování rezidentních
programů (to jsou ty, které po svém ukončení ještě zůstanou v paměti a něco
dělají) a virů (což je speciální případ rezidentních programů, protože většina
virů je skutečně rezidentních).
Mezi systémové programy patří kromě rezidentních programů také programy pro
obsluhu přerušení, mezi které patří i ovladače zařízení. Každé zařízení, které
máte připojeno v DOSu, komunikuje pomocí tzv. přerušení, což je
žádost určená pro procesor, aby dokončil právě prováděnou instrukci a předal
řízení jinam, protože se něco stalo. Události, při kterých se generuje
přerušení je například:
- Pohyb myši a stisk
tlačítek na myši
- Stisk klávesy na
klávesnici
- Reset počítače
- Výpadek elektrického
proudu
- Časovač generuje
přerušení v časových intervalech
V Trojance na serveru jsou programy (pokud je někdo nevymazal) KBD.CPP,
INT8.CPP, INT8A.CPP, INT8B.CPP, které jsou pro obsluhu přerušení z klávesnice.
Přerušení je generováno, ikdyž program přejde do nekonečného cyklu typu:
l: goto l; while (true) do ; to je v Pascalu
l: goto l; while (1) ; to je v C resp. C++
Po skončení obsluhy přerušení se program navrátí zpět za instrukci, při
které přišlo přerušení. Existují dva druhy přerušení: Maskovatelná
a nemaskovatelná. Maskovatelná přerušení lze zakázat a opětovně
povolit instrukcemi CLI (zakázání), STI (povolení). Nemaskovatelná přerušení
nelze zakázat, protože se budou vždy provádět. Podle typu zdroje přerušení
rozeznáváme hardwarové a softwarové. Hardwarové
jsou ty, které jsou generovány nějakým zařízením resp. časovačem. Softwarové
jsou generovány něčím v programu (např. dělení nulou, krokování, uživatelské
vyvolání přerušení např. instrukcí INT, přetečením podtečením čísla v
matematickém koprocesoru). Pokud změníme adresu obsluhy přerušení a zadáme svou
novou (například virus, který chce převzít kontrolu na systémem), potom je
programátorskou slušností zavolat starou obsluhu, je pravda, že to mnoho
programátorů o to nestará, proto se některé programy zasekávají a působí krach
systému. Pokud vir nezavolá staré přerušení, potom něco zpravidla přestane
fungovat a takový vir nepřímo prozradí svou existenci.
Může být až 16 hardwarových přerušení IRQ (interrupt request). V paměti od
adresy 0:0 je v DOSu tabulka přerušení, 1 položka 4 B (2 B segment a 2 B
offset) a jejich počet j 256, takže tabulka zabírá 1024. Mnoho programátorů,
kteří tam náhodně něco zapsali si asi říkají, proč ten můj program nefunguje a
proč se zasekává? Dokud totiž nepřijde přerušení, tak se nic nestane, ale pokud
přijde, počítač před provedením přerušení vybere odtud adresu a provede skok na
adresu podle tabulky přerušení. Kam skočí? To nelze s určitostí říci. Důsledkem
je zpravidla zaseknutí nebo nějaká nepředvídatelná činnost. Rada: Neskákejte a
nenastavujte adresy, které směřují do ROM BIOS, neboť každá ROM je jiná, mohly
byste se např. strefit na podprogram pro hloubkové formátování disku, který tam
někde v ROM je.
Před zavoláním přerušení se na zásobník uloží CS (2B), IP (2B), FLAGS (2B) v
tomto pořadí. Nyní si uvedeme něco z tabulky přerušení a číslo přerušení
(adresa = 4*číslo přerušení):
- č.0 ... dělení 0
- č. 3,4 ... ladění
- č.8 ... časovač - generuje
přerušeních každých 55 ms - používají ho služby pro vypnutí motoru Floppy
Disku, řeší se tak například hodiny v některých nadstavbách DOSu
- č.9 ... klávesnice
- č.0x21 ... služby jádra
DOSu
U hardwarových přerušení je nutné upozornit OS, že obluha přerušení již byla
ukončena. To se provede zápisem hodnoty 0x20 na port 0x20 (ne na adresu), což
způsobí, že budou přijímána další hardwarová přerušení. Do té doby jsou ostatní
hardwarová přerušení blokovány, takže nelze napsat nic z klávesnice, počítač
tedy přestane reagovat. Obsluha přerušení by měla být spolehlivá, takže by se
počítač neměl během přerušení zaseknout, potom nelze ani přepnout do jiné
aplikace, takže nezbývá než RESET. U obsluhy klávesnice se v přerušení musí
zapsat na port (ne na adresu) 0x61 hodnotu nějakou. Je to složitější, najdete
to v příkladu CPP\#ZAKL\09\!KBD.CPP void oziv_kl(). V přerušení udělám věci,
které potřebuji a zavolám starou funkci pro obsluhu přerušení.
void interrupt int8(...) zde se píše výpustka - registry DOSu. Registry lze
použít, ale změněné registry by se měly obnovit po ukončení přerušení. Pokud
zavoláme starou obsluhu přerušení, nemusíme se starat o oživení klávesnice,
protože to za nám udělá stará obluha přerušení, pokud jí zavoláme. Pokud ovšem
nechceme zavolat starou obsluhu přerušení (například softwarová ochrana disku
proti zápisu), potom musíme udělat skoro všechno to, co udělala stará obsluha
přerušení, aby se počítač dal použít i po provedení přerušení. Jinak je nutný
reset.
Novinka: Někde v tom souboru je proměnná deklarovaná jako extern
volatile. Jedná se o proměnnou, kterou lze měnit i mimo program,
neoptimalizuje se, vždy je brána z paměťového místa.
V souboru !KBD.CPP je něco jako:
unsigned c=inportb(KbData);
if (c==1) {pocet++;oziv_kl();}else StaKlav();
StaKlav() je vlastně stará obsluha přerušení, oziv_kl() je vlastně funkce
pro oživení klávesnice, kterou musíme zavolat, abychom rozchodili počítač, když
nezavoláme starou obsluhu přerušení. Funkce inportb(port) čte byte z portu.
V souboru INT8.CPP je něco jako práce s klávesnicí a zárovneň výpis na
videopaměť.
unsigned (*obr)[00]=(unsigned (*)[00]) MK_FP(0xB800,0);
Jak známe z kapitoly o obrazové paměti 0xB800 je
počáteční adresa obrazové paměti v textovém režimu 80x25 znaků. Makrem MK_FP z
něho uděláme vzálený ukazatel, kterým potom můžeme adresovat obrazovou paměť a
tak tam něco zapisovat resp. číst.
outportb(unsigned port,unsigned char co_poslat); pošle
"co_poslat" (což je zde 1 B) na hardwarový port "port". Je
to adresa portu 16-ti bitové číslo = 2B (0 - 65535). Lze to použít pro přímý
tisk na tiskárnu, sériový COM resp. paralelní port LPT - CENTRONICS nebo také
pro operace se zvukovou kartou, práci s pamětí C-MOS nebo také pro oživení
klávesnice v přerušení, pokud nepoužijeme standartní obsluhu.
_setcursortype(int typ_kurzoru); Změní tvar kurzoru v textovém
režimu na PC v DOSu. To je ta standartně blikající čárka. Určuje, kam se bude
psát znak. Pozici kurzoru v textovém režimu můžeme nastavit void
gotoxy(int x, int y); a zjistit souřadnice lze zjistit funkcí int
wherex(void) x-ovou souřadnici (vodorovnou) resp. int wherey(void)
y-ovou souřadnici (svislou). V grafickém režimu lze pozici nastavit funkcí void
far moveto(int x, int y); a zjistit lze x-ovou souřadnici v grafickém
režimu použitím funkce int far getx(void); a y-ovou funkcí int
far gety(void); . O grafice bude samostatná kapitola. Pro používání
standartních grafických funkcí použijte hlavičkový soubor graphics.h. Funkce se
zde v BC 3.1 skoro jmenují stejně jako v Turbo / Borland Pascalu 6.0 resp. 7.0,
pouze se píší s malými písmeny. Rozdíl je u initgraph, že se zde předává
proměnná odkazem, takže musíme zadat referenci na proměnnou typu int u gd a gm
(graphics driver a graphics mode). Častá chyba (proto ji raději nedělejte!), že
v cestě k BGI souboru zapomenete zdvojit \ !!! Takže zatímco v Pascalu píšete
něco jako 'c:\bp\bgi', tak v BC31 napíšete něco jako "c:\\bc31\\bgi".
Zde v cestě můžete napsat i malé i velké písmena, je to jedno, protože se cesta
předá DOSu, který malá a velká písmena nerozlišuje. Zatímco jména proměnných je
nutno dodržovat a grafické funkce je nutno psát malými písmeny. Budete se asi
divit (zkušenější asi ne), že Pascal 7.0 resp. 6.0 používá jiné BGI soubory,
které vzájemně nelze zaměňovat, což mě vadilo, když jsem měl v Pascalu BGI
soubor pro 256 barevnou grafiku a chtěl jsem ho použít i v BC 3.1, takže to
skončilo chybou na funkci installuserdriver sloužící pro zavedení
uživatelského ovladače. Nyní již mám správný ovladač
pro 256 barevnou grafiku.
Reference -
2.část:
O referencích jsme si již něco řekli. Takže asi už
víme, že na reference je možno se dívat jako na ukazazele, které se
dereferencují. Znak * pro ukazatele se nahradí znakem &, což lze většinou
(až na následující vyjímku) brát jako předávání parametru odkazem, což mnoho programátorů
používá. Ale není to totéž. Ukážeme si příkalad:
#include <iostream.h>
#include <iomanip.h>
int i = 11;
int &ri = i;
void main()
{ cout << ri;
}
Moje poznámka: Uvedený prográmek bylo
potřeba trochu upravit, aby ho diaprojektor v Břehové ve 103 správně
zobrazoval, protože neumí zobrazit 1. sloupec znaků v textovém režimu. Takže
FJFI si asi bude toužebně přát nový hardware. No příspěvky jsou pořád malé a
pořád se snižují... Naše vláda školství se zanedbává...
Moje poznámka: Vlastní zkoumání jazyka C++,
když jsem byl ještě začátečník... Stáhněte si archiv.
Moje poznámka: Připravuje se druhá část této WWW stránky, protože
editory www stránek již přestávají umět generovat tak dlouhé WWW stránky.
Druhou část najdete také na mé stránce pod jménem http://www-troja.fjfi.cvut.cz/~sokolovs/CPP2.HTM
Poslední modifikace stránek byla provedena - Last modified: